
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
0x00 安装
- 都只支持py3
- 运行报错一个一个模块安装很难看,看看dirmap给的requirement.txt
gevent
requests
progressbar2
lxml
直接
pip3 install -r requirement.txt
多么愉快和轻松
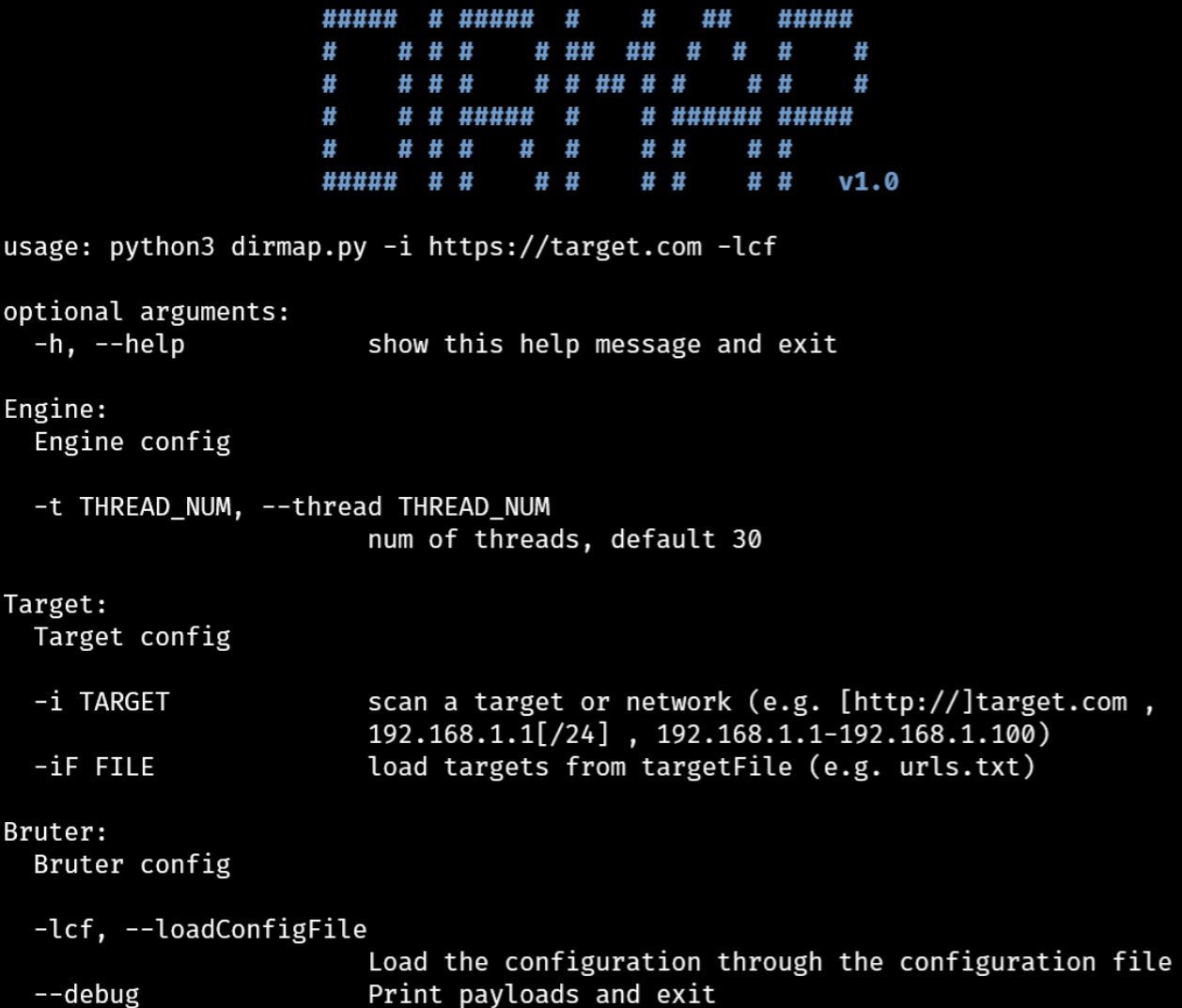

0x01 使用
dirmap
一个高级web目录扫描工具,功能将会强于DirBuster、Dirsearch、cansina、御剑
具备以下功能:
- 并发引擎
- 能使用字典
- 能纯爆破
- 能爬取页面动态生成字典
- 能fuzz扫描
- 自定义请求
- 自定义响应结果处理…
基础使用
python3 dirmap.py -i https://target.com -lcf
python3 dirmap.py -i 192.168.1.1 -lcf
单目标,默认为http
python3 dirmap.py -i https://target.com -lcf
python3 dirmap.py -i 192.168.1.1 -lcf
子网(CIDR格式)
python3 dirmap.py -i 192.168.1.0/24 -lcf
网络范围
python3 dirmap.py -i 192.168.1.1-192.168.1.100 -lcf
- 文件读取
python3 dirmap.py -iF targets.txt -lcf
targets.txt中支持上述格式
- 结果保存
- 结果将自动保存在项目根目录下的
output文件夹中 - 每一个目标生成一个txt,命名格式为
目标域名.txt - 结果自动去重复,不用担心产生大量冗余
dirsearch
python3 dirsearch.py -u <URL> -e <EXTENSION>
python3 dirsearch.py -u url -e *
py -3 dirsearch.py -u url -e *
Options:
-h, --help show this help message and exit
Mandatory:
-u URL, --url=URL URL target
-L URLLIST, --url-list=URLLIST
URL list target
-e EXTENSIONS, --extensions=EXTENSIONS
Extension list separated by comma (Example: php,asp)
-E, --extensions-list
Use predefined list of common extensions
Dictionary Settings:
-w WORDLIST, --wordlist=WORDLIST
-l, --lowercase
-f, --force-extensions
Force extensions for every wordlist entry (like in
DirBuster)
General Settings:
-s DELAY, --delay=DELAY
Delay between requests (float number)
-r, --recursive Bruteforce recursively
-R RECURSIVE_LEVEL_MAX, --recursive-level-max=RECURSIVE_LEVEL_MAX
Max recursion level (subdirs) (Default: 1 [only
rootdir + 1 dir])
--suppress-empty, --suppress-empty
--scan-subdir=SCANSUBDIRS, --scan-subdirs=SCANSUBDIRS
Scan subdirectories of the given -u|--url (separated
by comma)
--exclude-subdir=EXCLUDESUBDIRS, --exclude-subdirs=EXCLUDESUBDIRS
Exclude the following subdirectories during recursive
scan (separated by comma)
-t THREADSCOUNT, --threads=THREADSCOUNT
Number of Threads
-x EXCLUDESTATUSCODES, --exclude-status=EXCLUDESTATUSCODES
Exclude status code, separated by comma (example: 301,
500)
--exclude-texts=EXCLUDETEXTS
Exclude responses by texts, separated by comma
(example: "Not found", "Error")
--exclude-regexps=EXCLUDEREGEXPS
Exclude responses by regexps, separated by comma
(example: "Not foun[a-z]{1}", "^Error$")
-c COOKIE, --cookie=COOKIE
--ua=USERAGENT, --user-agent=USERAGENT
-F, --follow-redirects
-H HEADERS, --header=HEADERS
Headers to add (example: --header "Referer:
example.com" --header "User-Agent: IE"
--random-agents, --random-user-agents
Connection Settings:
--timeout=TIMEOUT Connection timeout
--ip=IP Resolve name to IP address
--proxy=HTTPPROXY, --http-proxy=HTTPPROXY
Http Proxy (example: localhost:8080
--http-method=HTTPMETHOD
Method to use, default: GET, possible also: HEAD;POST
--max-retries=MAXRETRIES
-b, --request-by-hostname
By default dirsearch will request by IP for speed.
This forces requests by hostname
Reports:
--simple-report=SIMPLEOUTPUTFILE
Only found paths
--plain-text-report=PLAINTEXTOUTPUTFILE
Found paths with status codes
--json-report=JSONOUTPUTFILE
python3 dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt
python3 dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt --recursive -R 2
python3 dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt --recursive -R 4 --scan-subdirs=/,/wp-content/,/wp-admin/
python3 dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt --exclude-texts=This,AndThat
python3 dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt -H "User-Agent: IE"
python3 dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt -t 20
python3 dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt --random-agents
python3 dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt --json-report=reports/target.json
python3 dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt --simple-report=reports/target-paths.txt
python3 dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt --plain-text-report=reports/target-paths-and-status.json
Traceback (most recent call last):
File "dirsearch.py", line 26, in <module>
from lib.core import ArgumentParser
ModuleNotFoundError: No module named 'lib.core'
安装 argumentpar 模块
- 如果安装模块后还是报错无法使用,请重新下载完整
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/188141.html原文链接:https://javaforall.net

![DialogBOX-函数功能[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
