
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
query.uniqueResult() 和 query.getSingleResult()
当我使用query.getSingleResult()返回实例时,提示有错,不知道什么原因。

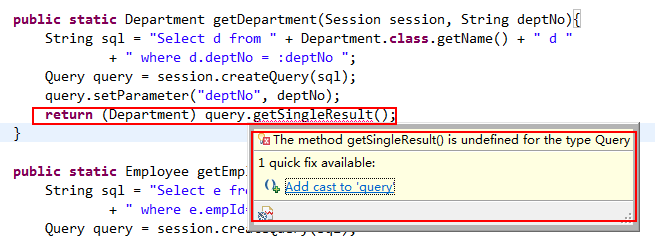
按提示修改后还是有错
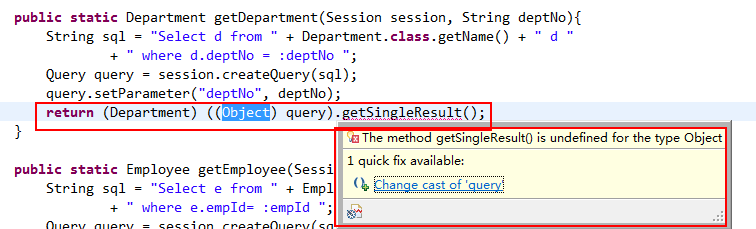
后来使用 query.uniqueResult() 方法解决问题
public static Department getDepartment(Session session, String deptNo){
String sql = "Select d from " + Department.class.getName() + " d " + " where d.deptNo = :deptNo ";
Query query = session.createQuery(sql);
query.setParameter("deptNo", deptNo);
return (Department) query.uniqueResult();
}版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/188353.html原文链接:https://javaforall.net


