
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
在Java7中,InputStream被定义为一个抽象类,相应的,该类下的read()方法也是一个抽象方法,这也就意味着必须有一个类继承InputStream并且实现这个read方法。
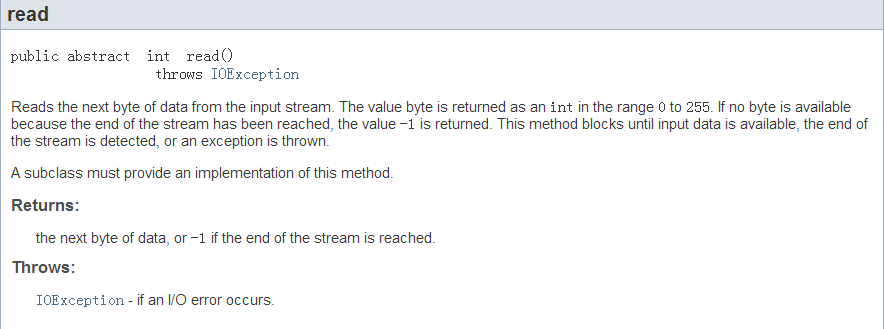
查阅Java7 API,我们可以看到,在InputStream中定义了三个重载的read()方法:

但是在这三个方法中,只有参数列表为空的read方法定义为抽象方法,这也就意味着在直接继承自InputStream的所有子类中,必须重写这个方法。下面我们来看看这个方法的介绍:
这里有两点需要注意:一是这个方法的返回值是int类型;二是在这个方法每次从数据源中读取一个byte并返回。很多初次接触Java的读者在看到这里时都会产生下面的疑问,就是这个方法读取的byte是如何以int的形式返回的。
在计算机中,所有的文件都是以二进制的形式存储的,换句话说,每个文件不管是什么类型,在计算机中的形式都是一串0和1。而read()方法在读的时候是每次读取8个二进制位,这8个0或1就是我们所谓的一个byte(字节)。在这里通常容易产生的疑问就是将字节和字符混为一谈。无论在什么语言什么系统中,只要它符合当今世界对于计算机技术的主流定义,那么一个byte就是8个二进制位。而字符则不同,字符是与人为定义的编码规则相关的,一个字符的大小(也就是其所占的二进制位)是由编码规则决定的,比如在GBK编码中一个汉字用两个字节表示,而在utf-8中,一个汉字由3到4个字节表示。言归正传,既然一个byte表示8个二进制位,那么这8个二进制位就是一个0-255之间的十进制数字,实际上在Java中,byte就是一个0-255之间的整数,而将从文件中读取的二进制转化成十进制这一过程是由read()方法完成的。
也就是说,read()这个方法完成的事情就是从数据源中读取8个二进制位,并将这8个0或1转换成十进制的整数,然后将其返回。
下面再来看read(byte[] b)这个方法,这个方法的介绍如下:
这个方法使用一个byte的数组作为一个缓冲区,每次从数据源中读取和缓冲区大小(二进制位)相同的数据并将其存在缓冲区中。当然byte数组中存放的仍然是0-255的整数,将二进制转换为十进制这个过程仍然是read方法实现的。
需要注意的是,虽然我们可以指定缓冲区的大小,但是read方法在读取数据的时候仍然是按照字节来读取的。在utf-8等变长编码中,一个复杂字符(比如汉字)所占字节往往大于1,并且长度往往是不固定的。(参照UTF-8编码规则)按照字节读取数据会将字符割裂,这就导致我们在使用read(byte[] b)方法读取文件时,虽然指定了缓冲区的大小,但是仍然会出现乱码。下面这段代码可以很好地解释这一点


public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
InputStream in = null;
File f = new File("D:/test.txt");
byte[] b = new byte[2];
in = new FileInputStream(f);
int i = 0;
while ((i = in.read(b)) != -1) {
String str = new String(b);
System.out.print(str);
}
}文件如下(采用ANSI编码):
运行结果如下:
补充一点:在调用new String(byte[] b)这个构造方法时,java会根据传入的数据按照当前编码规则创建String,如果将编码方式改为GBK,则可以正常输出中文:
这是因为,GBK编码每个汉字占两个字节,缓冲区大小设为2就可以避免字符编码割裂的情况。


发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/191140.html原文链接:https://javaforall.net


