
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
原文链接:https://blog.csdn.net/weixin_37895339/article/details/82863379
前文是一些针对IRL,IL综述性的解释,后文是针对《Generative adversarial imitation learning》文章的理解及公式的推导。
- 通过深度强化学习,我们能够让机器人针对一个任务实现从0到1的学习,但是需要我们定义出reward函数,在很多复杂任务,例如无人驾驶中,很难根据状态特征来建立一个科学合理的reward。
- 人类学习新东西有一个重要的方法就是模仿学习,通过观察别人的动作来模仿学习,不需要知道任务的reward函数。模仿学习就是希望机器能够通过观察模仿专家的行为来进行学习。
- OpenAI,DeepMind,Google Brain目前都在向这方面发展。
[1] Model-Free Imitation Learning with Policy Optimization, OpenAI, 2016
[2] Generative Adversarial Imitation Learning, OpenAI, 2016
[3] One-Shot Imitation Learning, OpenAI, 2017
[4] Third-Person Imitation Learning, OpenAI, 2017
[5] Learning human behaviors from motion capture by adversarial imitation, DeepMind, 2017
[6] Robust Imitation of Diverse Behaviors, DeepMind, 2017
[7] Unsupervised Perceptual Rewards for Imitation Learning, Google Brain, 2017
[8] Time-Contrastive Networks: Self-Supervised Learning from Multi-View Observation, Google Brain, 2017
[9] Imitation from Observation/ Learning to Imitate Behaviors from Raw Video via Context Translation, OpenAI, 2017
[10] One Shot Visual Imitation Learning, OpenAI, 2017
模仿学习
- 从给定的专家轨迹中进行学习。
- 机器在学习过程中能够跟环境交互,到那时不能直接获得reward。
- 在任务中很难定义合理的reward(自动驾驶中撞人reward,撞车reward,红绿灯reward),人工定义的reward可能会导致失控行为(让agent考试,目标为考100分,但是reward可能通过作弊的方式)。
- 三种方法:
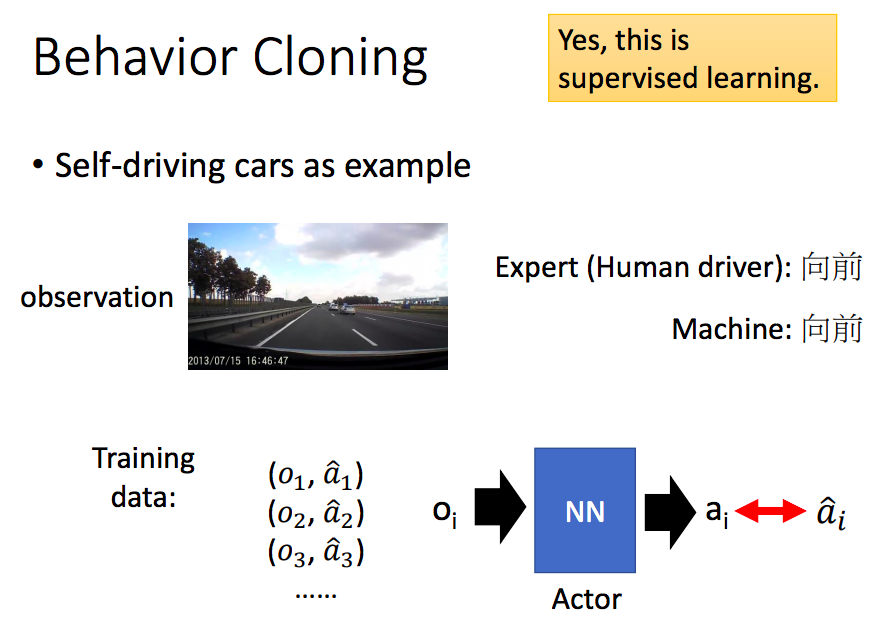
a. 行为克隆(Behavior Cloning)
b. 逆向强化学习(Inverse Reinforcement Learning)
c. GAN引入IL(Generative Adversarial Imitation Learning) - 行为克隆
有监督的学习,通过大量数据,学习一个状态s到动作a的映射。

但是专家轨迹给定的数据集是有限的,无法覆盖所有可能的情况。如果更换数据集可能效果会不好。则只能不断增加训练数据集,尽量覆盖所有可能发生的状态。但是并不实际,在很多危险状态采集数据成本非常高。 - 逆向强化学习
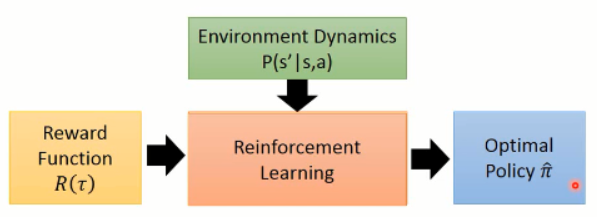
RL是通过agent不断与environment交互获取reward来进行策略的调整,最终得到一个optimal policy。但IRL计算量较大,在每一个内循环中都跑了一遍RL算法。
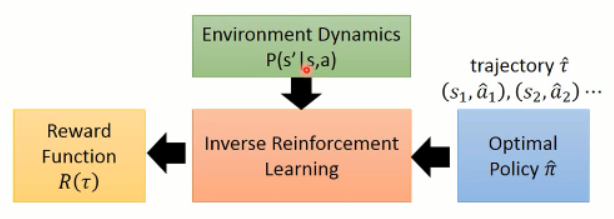
IRL不同之处在于,无法获取真实的reward函数,但是具有根据专家策略得到的一系列轨迹。假设专家策略是真实reward函数下的最优策略,IRL学习专家轨迹,反推出reward函数。
得到复原的reward函数后,再进行策略函数的估计。
RL算法:
IRL算法:
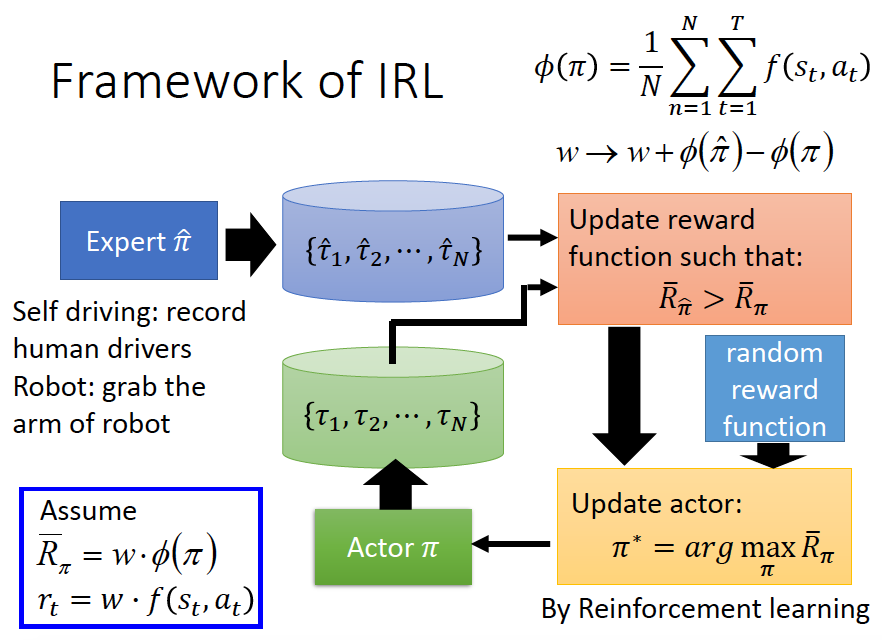
在给定的专家策略后(expert policy),不断寻找reward function来使专家策略是最优的。(解释专家行为,explaining expert behaviors)。具体流程图如下:
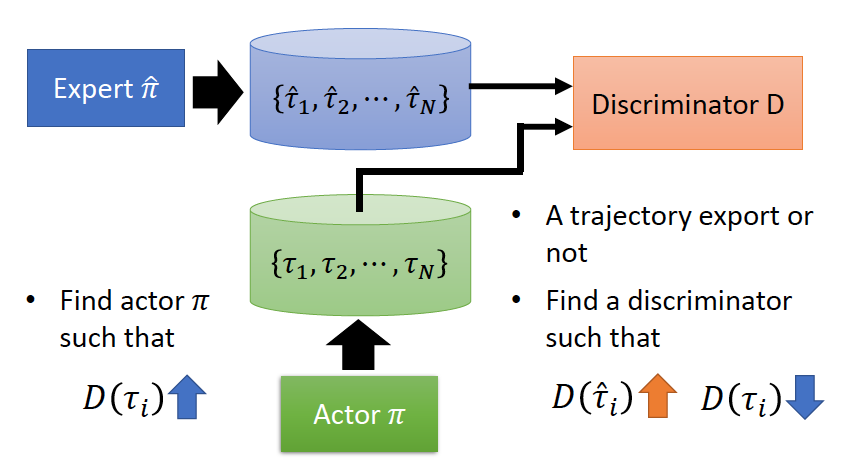
- 生成对抗模仿学习(GAN for Imitation Learning)
我们可以假设专家轨迹是属于某一分布(distribution),我们想让我们的模型也去预测一个分布,并且使这两个分布尽可能的接近。
算法流程如下:
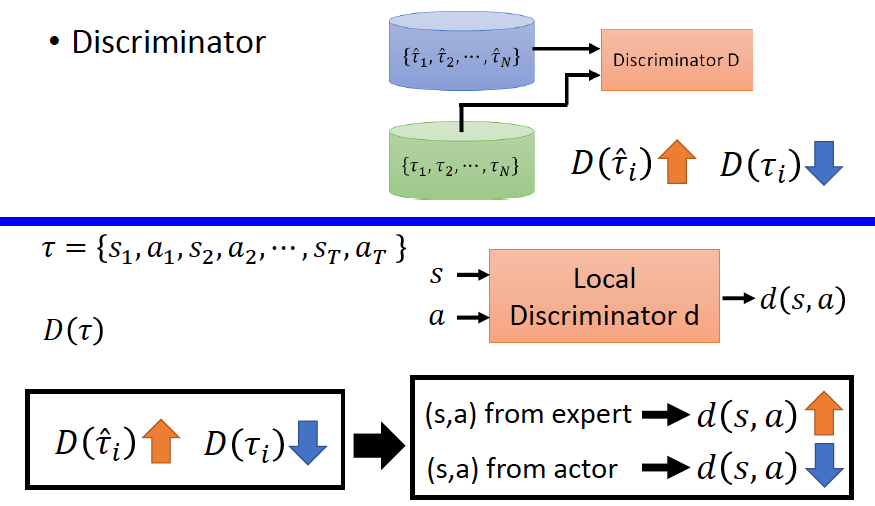
Discriminator:尽可能的区分轨迹是由expert生成还是Generator生成。
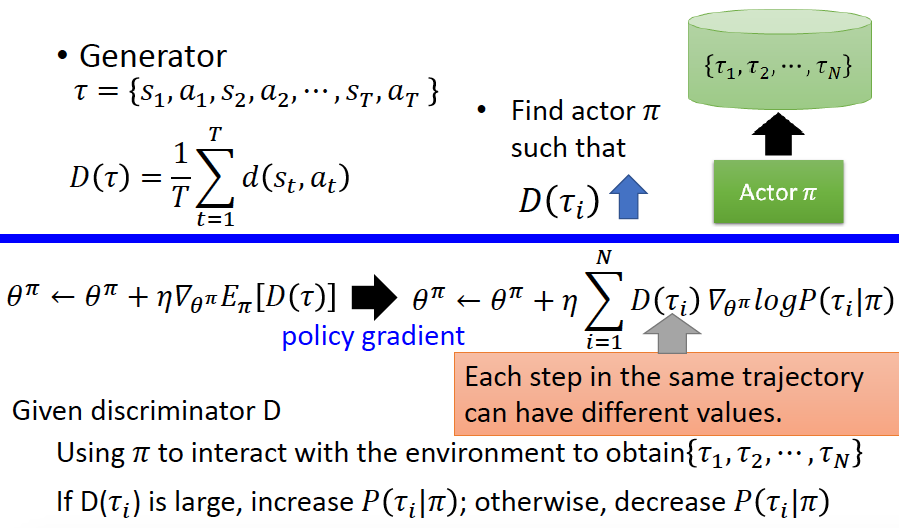
Generator(Actor):产生出一个轨迹,使其与专家轨迹尽可能相近,使Discriminator无法区分轨迹是expert生成的还是Generator生成的。
其算法可以写为:




生成对抗模仿学习(Generative Adversarial Imitation Learning)
GAIL能够直接从专家轨迹中学得策略,绕过很多IRL的中间步骤。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/191738.html原文链接:https://javaforall.net


