
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
1 模仿学习
- 模仿学习 (Imitation Learning) 不是强化学习,而是强化学习的一种替代品。
- 模仿学习与强化学习有相同的目的:
- 两者的目的都是学习策略网络,从而控制智能体。
- 模仿学习与强化学习又有不同的原理:
- 模仿学习向人类专家学习,目标是让策略网络做出的决策与人类专家相同;
- 强化学习利用环境反馈的奖励改进策略,目标是让累计奖励(即回报)最大化。
2 行为克隆概述
- 行为克隆 (Behavior Cloning) 是最简单的模仿学习。
- 行为克隆的目的是模仿人的动作,学出一个随机策略网络 π(a|s; θ) 或者确定策略网络 µ(s; θ)。
- 虽然行为克隆的目的与强化学习中的策略学习类似,但是行为克隆的本质是监督学习(分类或者回归),而不是强化学习。
- 行为克隆通过模仿人类专家的动作来学习策略,而强化学习则是从奖励中学习策略。
模仿学习需要一个事先准备好的数据集,由(状态,动作)这样的二元组构成,记作:
其中 sj 是一个状态,而对应的 aj 是人类专家基于状态 sj 做出的动作。(aj就是行为克隆遇到状态sj时,应该做出的动作)
可以把 sj 和 aj 分别视作监督学习中的输入和标签。
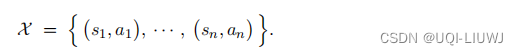
3 连续控制问题+行为克隆 【类比:有监督回归问题】
强化学习笔记:连续控制 & 确定策略梯度DPG_UQI-LIUWJ的博客-CSDN博客中的DPG策略网络是一样的
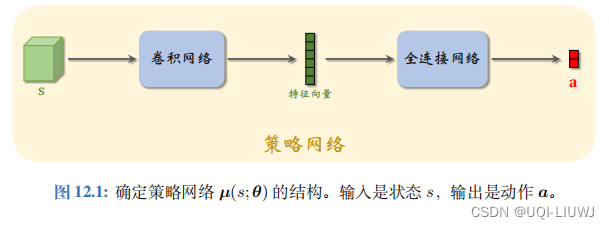

行为克隆用回归的方法训练确定策略网络。训练数据集 X 中的二元组 (s, a) 的意思
s
,人做出动作
a
。行为克隆鼓励策略网络的决策
µ
(
s
;
θ
)
接近人做出的动作
。
于是我们定义损失函数
损失函数越小,说明策略网络的决策越接近人的动作。【相比于DPG,这里时有了一个ground truth的动作,所以就和监督学习一样直接可以计算loss;而DPG这类强化学习的任务则是需要将决策网络的输出送到value network中,才会有可以判断好坏的奖励】使用梯度下降更新θ
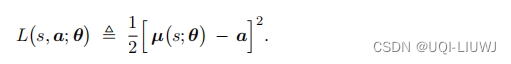

3.1 训练流程

4 离散控制问题+行为克隆【类比:有监督分类问题】
此时的策略网络和强化学习笔记:policy learning_UQI-LIUWJ的博客-CSDN博客中的类似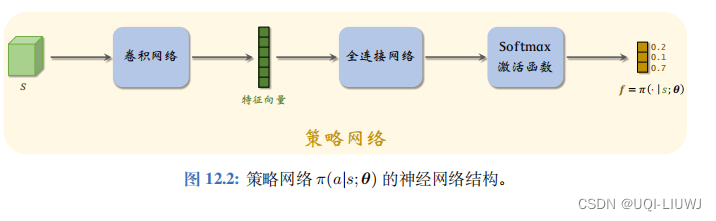
行为克隆把策略网络 π(a|s; θ) 看做一个多类别分类器,用监督学习的方法训练这个分类器。
把训练数据集 X 中的动作 a 看做类别标签,用于训练分类器。需要对类别标签 a 做 One-Hot 编码,得到 |A| 维的向量,记作粗体字母 a¯。
和有监督学习中的分类问题一样,我们用交叉熵来衡量策略网络输出和ground truth分布之间的区别
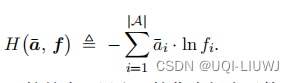
我们同样用梯度下降更新参数
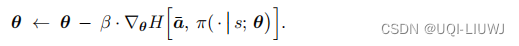
4.1 训练流程

5 强化学习 VS 行为克隆
| 行为克隆 | 强化学习 |
|
不需要与环境交互,而是利用事先准备好的数据集,用人类的动作指导策略网络的改进,目的是让策略网络的决策更像人类的决策。
|
让智能体与环境交互,用环境反馈的奖励指导策略网络的改进,目的是最大化回报的期望。
|
|
本质上是监督学习,不是强化学习 ——>离散动作:分类 ——>连续动作:回归 |
|
|
隆训练出的策略网络通常效果不佳。
——>人类不会探索奇怪的状态和动作,因此数据集上的状态和动作缺乏多样性。
——>
在数据集上做完行为克隆之后,智能体面对真实的
环境,可能会见到陌生的状态,智能体的决策可能会很糟糕。
|
|
|
行为克隆存在“错误累加” 的缺陷。
假如当前智能体的决策
不够好
——>那么下一时刻的状态
可能会比较罕见
——>于是智能体的决策
会很差
——>这又导致状态
非常奇怪
——>使得决策
更糟糕
行 为克隆训练出的策略常会进入这种恶性循环。
|
强化学习效果通常优于行为克隆。
如果用强化学习,那么智能体探索过各种各样的 状态,尝试过各种各样的动作,知道面对各种状态时应该做什么决策。
智能体通过探索, 各种状态都见过,比行为克隆有更多的“人生经验”,因此表现会更好。
|
|
行为克隆的优势在于离线训练,可以避免与真实环境的交互,不会对环境产生影响。
可以先用行为克隆初始化策略网络,而不是随机初始化,然后再做
强化学习,这样可以减小对物理世界的有害影响。
|
强化学习的一个缺点在于需要与环境交互,需要探索,而且会改变环境。
如果在真实物理世界应用强化学习,要考虑初始化和探索带来的成 本。
|
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/193581.html原文链接:https://javaforall.net

![idea 2021激活码[在线序列号][通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
