
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
word2vec原理(一): CBOW与Skip-Gram模型基础
word2vec原理(二):基于Hierarchical Softmax的模型
word2vec原理(三): 基于Negative Sampling的模型
目录
word2vec是Google在2013年推出的一个NLP工具,它的特点是将所有的词向量化,这样词与词之间就可以定量的去度量他们之间的关系,挖掘词之间的联系。
word2vec工具主要包含两个模型:跳字模型(skip-gram)和连续词袋模型(continuous bag of words,简称CBOW),以及两种高效训练的方法:负采样(negative sampling)和层序softmax (hierarchical softmax)。值得一提的是,word2vec词向量可以较好地表达不同词之间的相似和类比关系。
Skip-gram和CBOW是Word2vec架构的两种类型,可以理解为两种实现方式,不是说,word2vec包含这两个模型。word2vec自提出后被广泛应用在自然语言处理任务中。它的模型和训练方法也启发了很多后续的词向量模型。
1. 词向量基础
向量空间模型长期以来一直被用于分布式语义的目的,它以向量的形式表示文本文档和查询语句。通过以向量空间模型在N维空间中来表示单词,可以帮助不同的NLP算法实现更好的结果,因此这使得相似的文本在新的向量空间中组合在一起。
自然语言是一套用来表达含义的复杂系统。在这套系统中,词是表义的基本单元。在机器学习中,如何使用向量表示词?顾名思义,词向量是用来表示词的向量,通常也被认为是词的特征向量。词向量,又名词嵌入(Word Embedding)。近年来,词向量已逐渐成为自然语言处理的基础知识。
用词向量来表示词并不是word2vec的首创,在很久之前就出现了,表示方式:
1.1 One-Hot 编码(独热编码)
一种最简单的词向量方式是one-hot representation,就是用一个很长的向量来表示一个词,向量的长度为词汇表的大小,向量的分量只有一个 1,其他全为 0,1 的位置对应该词在词典中的位置。比如:
‘中国’表示为: [00010000000……]
‘美国’表示为:[0000000010000…]
每个词都是茫茫 0 海中的一个 1。这种 One-hot Representation 采用稀疏向量方式存储,会是非常的简洁:也就是给每个词分配一个数字 ID。比如刚才的例子中,中国记为 3,美国记为 8(假设从 0 开始记)。如果要编程实现的话,用 Hash 表给每个词分配一个编号就可以了。这么简洁的表示方法配合上最大熵、SVM、CRF 等等算法已经很好地完成了 NLP 领域的各种主流任务。
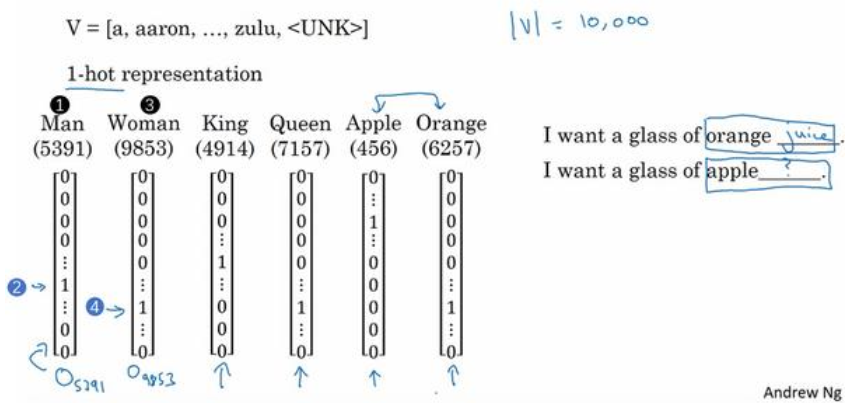

这种词表示有两个缺点:
(1)容易受维数灾难的困扰,尤其是将其用于 Deep Learning 的一些算法时:词汇表一般都非常大,比如达到百万级别,这样每个词都用百万维的向量来表示简直是内存的灾难。这样的向量其实除了一个位置是1,其余的位置全部都是0,表达的效率不高,能不能把词向量的维度变小呢?
(2)不能很好地刻画词与词之间的相似性(术语好像叫做“词汇鸿沟”):任意两个词之间都是孤立的,这样使得算法对相关词的泛化能力不强。因为任何两个one-hot向量之间的内积都是0,很难区分他们之间的差别。光从这两个向量中看不出两个词是否有关系,哪怕是丈夫和老公这样的同义词也不能幸免于难。
(个人认为,主要原因在于one-hot编码是把不适合欧式距离度量的类别数据,转换到欧式空间,适合距离度量,而文本分析中,更常用的是余弦距离,此时one-hot编码体现不出角度概念,因为余弦距离将距离归一化了)
1.2 分布式表示:词向量/词嵌入
Distributed representation可以解决One hot representation的问题,它最早是 Hinton 于 1986 年提出的。它的思路是通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。这就是word embedding,即指的是将词转化成一种分布式表示,又称词向量。分布式表示将词表示成一个定长的连续的稠密向量,这个较短的词向量维度是多大呢?这个一般需要我们在训练时自己来指定。
Distributed Representation 可以创建多个层次结构或分段,其中可以为每个单词显示的信息分配不同的权重。这些分段或维度的选择可以是我们决定的,并且每个单词将由这些段中的权重分布表示。
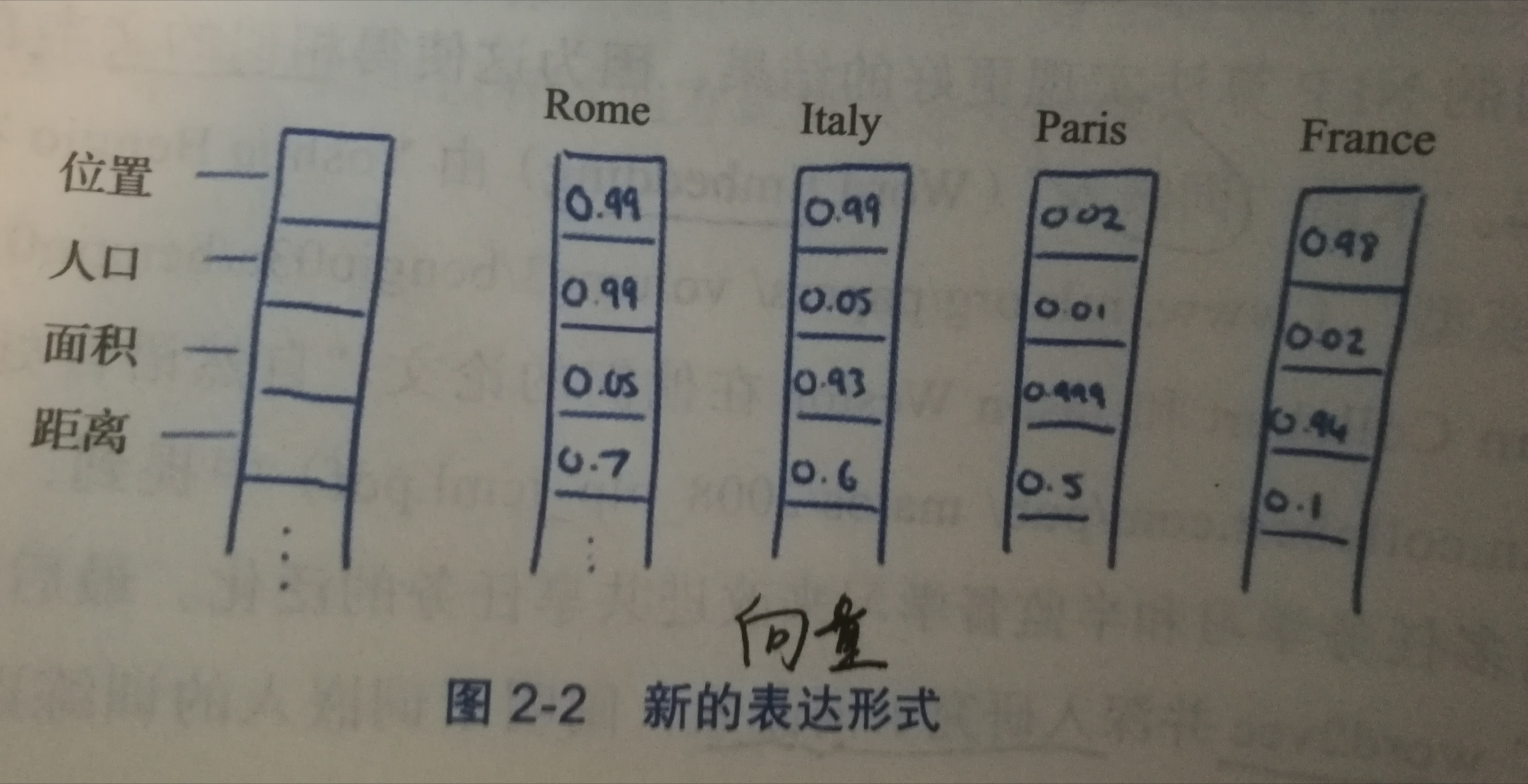

比如上图我们将词汇表里的词用”位置”,”人口”, “面积”和”距离”4个维度来表示,Rome这个词对应的词向量可能是(0.99,0.99,0.05,0.7),也就是普通的向量表示形式。维度以 50 维和 100 维比较常见。当然在实际情况中,我们并不能对词向量的每个维度做一个很好的解释。
有了用Distributed Representation表示的较短的词向量,我们就可以较容易的分析词之间的关系了,比如我们将词的维度降维到2维,有一个有趣的研究表明,用下图的词向量表示我们的词时,我们可以发现:
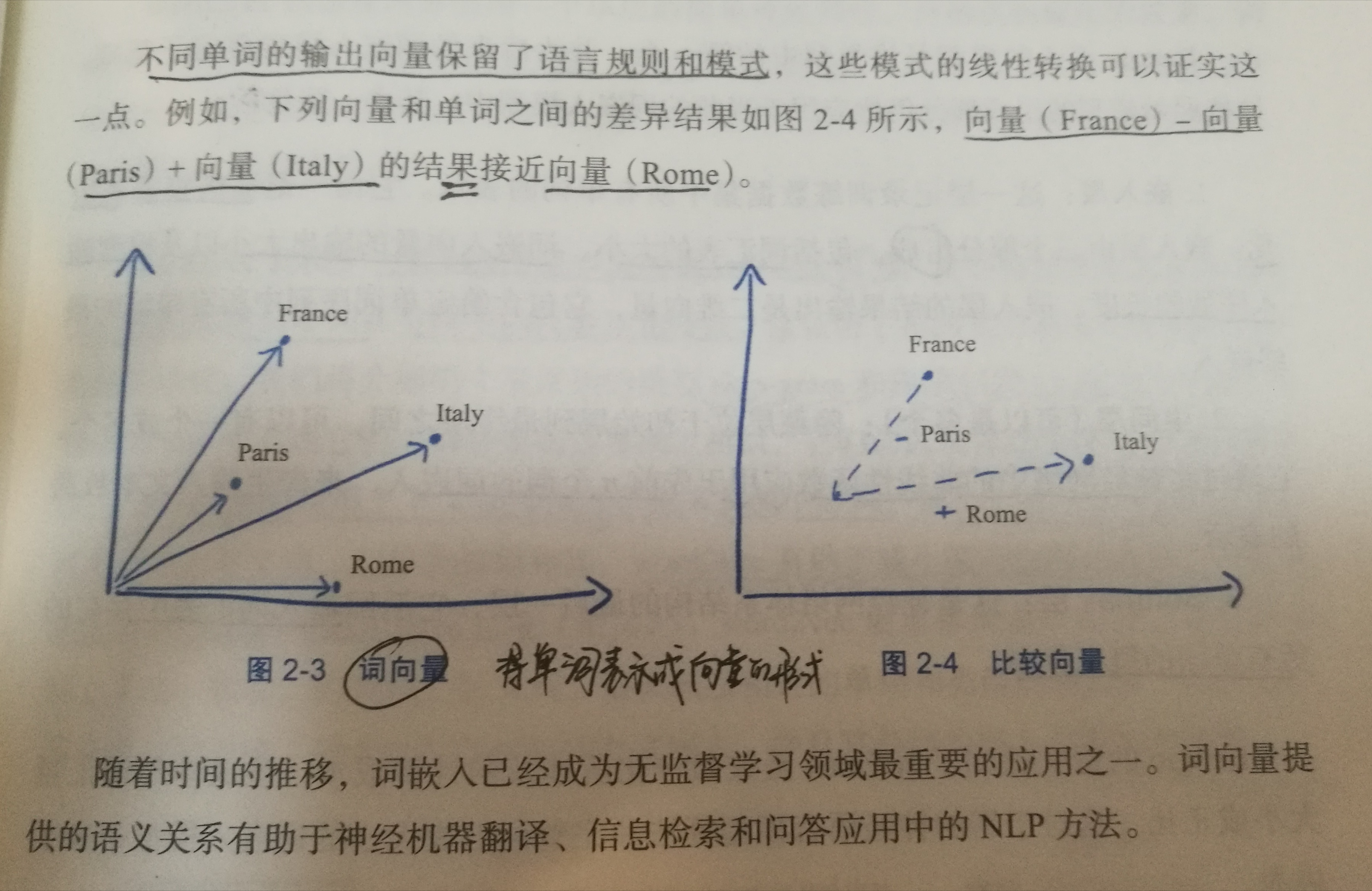
分布式表示优点:
(1) 词之间存在相似关系: 是词之间存在“距离”概念,这对很多自然语言处理的任务非常有帮助。
(2) 包含更多信息: 词向量能够包含更多信息,并且每一维都有特定的含义。在采用one-hot特征时,可以对特征向量进行删减,词向量则不能。
可见我们只要得到了词汇表里所有词对应的词向量,那么我们就可以做很多有趣的事情了。不过,怎么训练得到合适的词向量呢?一个很常见的方法是使用神经网络语言模型。
当然一个词怎么表示成这么样的一个向量是要经过一番训练的,训练方法较多,word2vec是其中一种,在后面会提到,这里先说它的意义。还要注意的是每个词在不同的语料库和不同的训练方法下,得到的词向量可能是不一样的。
由于是用向量表示,而且用较好的训练算法得到的词向量的向量一般是有空间上的意义的,也就是说,将所有这些向量放在一起形成一个词向量空间,而每一向量则为该空间中的一个点,在这个空间上的词向量之间的距离度量也可以表示对应的两个词之间的“距离”。所谓两个词之间的“距离”,就是这两个词之间的语法,语义之间的相似性。
一个比较实用的场景是找同义词,得到词向量后,假如对于词老婆来说,想找出与这个词相似的词,这个场景对人来说都不轻松,毕竟比较主观,但是对于建立好词向量后的情况,对计算机来说,只要拿这个词的词向量跟其他词的词向量一一计算欧式距离或者cos距离,得到距离小于某个值那些词,就是它的同义词。这个特性使词向量很有意义,自然会吸引很多人去研究,google的word2vec模型也是基于这个做出来的。
1.3 词向量可视化
如果我们能够学习到一个 300 维的特征向量,或者说 300 维的词嵌入,通常我们可以做一件事,把这 300 维的数据嵌入到一个二维空间里,这样就可以可视化了。常用的可视化算法是 t-SNE 算法,来自于 Laurens van der Maaten 和 Geoff Hinton 的论文。
t-SNE 算法:所做的就是把这些 300 维的数据用一种非线性的方式映射到 2 维平面上,可以得知 t-SNE 中这种映射很复杂而且很非线性。
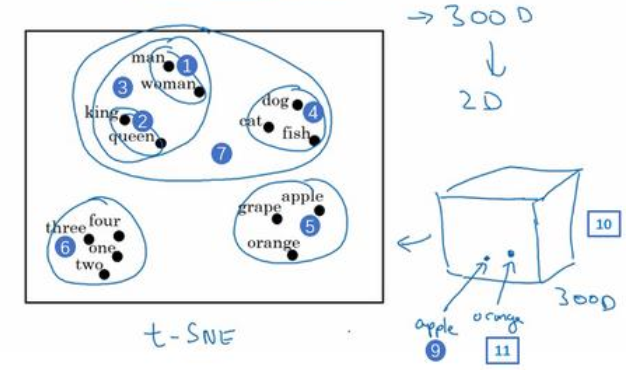
如果观察这种词嵌入的表示方法,会发现 man 和 woman 这些词聚集在一块(上图编号 1 所示), king 和queen 聚集在一块(上图编号 2 所示),这些都是人,也都聚集在一起(上图编号 3 所示)。动物都聚集在一起(上图编号 4 所示),水果也都聚集在一起(上图编号 5 所示),像 1、2、 3、 4 这些数字也聚集在一起(上图编号 6 所示)。如果把这些生物看成一个整体,他们也聚集在一起(上图编号 7 所示)。
词嵌入算法对于相近的概念,学到的特征也比较类似,在对这些概念可视化的时候,这些概念就比较相似,最终把它们映射为相似的特征向量。
这种表示方式用的是在 300 维空间里的特征表示,这叫做嵌入( embeddings)。之所以叫嵌入的原因是,你可以想象一个 300 维的空间,这里用个 3 维的代替(上图编号 8 所示)。现在取每一个单词比如 orange,它对应一个 3 维的特征向量,所以这个词就被嵌在这个 300 维空间里的一个点上了(上图编号 9 所示), apple 这个词就被嵌在这个 300 维空间的另一个点上了(上图编号 10 所示)。为了可视化, t-SNE 算法把这个空间映射到低维空间,你可以画出一个 2 维图像然后观察,这就是这个术语嵌入的来源。
1.4 词嵌入用做迁移学习
如果对于一个命名实体识别任务,只有一个很小的标记的训练集,训练集里可能没有某些词,但是如果有一个已经学好的词嵌入,就可以用迁移学习,把从互联网上免费获得的大量的无标签文本中学习到的知识迁移到一个命名实体识别任务中。
如果从某一任务 A 迁移到某个任务 B,只有 A 中有大量数据,而 B 中数据少时,迁移的过程才有用。
用词嵌入做迁移学习的步骤:
(1)先从大量的文本集中学习词嵌入,或者可以下载网上预训练好的词嵌入模型,网上可以找到不少,词嵌入模型并且都有许可。
(2)把这些词嵌入模型迁移到新的只有少量标注训练集的任务中。
(3)考虑是否微调,用新的数据调整词嵌入。当在新的任务上训练模型时,如命名实体识别任务上,只有少量的标记数据集上,可以自己选择要不要继续微调,用新的数据调整词嵌入。实际中,只有第二步中有很大的数据集时才会这样做,如果你标记的数据集不是很大,通常不建议在微调词嵌入上费力气。
当任务的训练集相对较小时,词嵌入的作用最明显。词嵌入在语言模型、机器翻译领域用的少一些,尤其是做语言模型或者机器翻译任务时,这些任务有大量的数据。
1.4 词嵌入用做类比推理
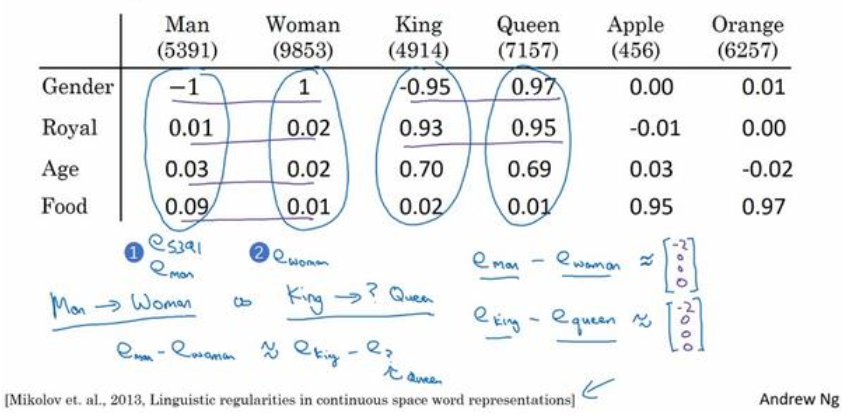
我们用一个四维向量来表示 man,称为,woman 的嵌入向量称为,对 king 和 queen 也是用一样的表示方法。在该例中,假设你用的是4维的嵌入向量,而不是比较典型的 50 到 1000 维的向量。这些向量有一个有趣的特性,就是假如
你有向量和,将它们进行减法运算,即

类似的,假如用和,最后也会得到一样的结果,即
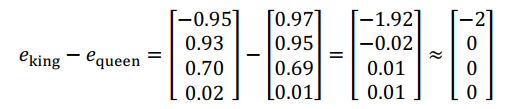
这个结果表示, man 和 woman 主要的差异是 gender ( 性别)上的差异,而 king 和 queen之间的主要差异,根据向量的表示,也是 gender( 性别)上的差异,这就是为什么与结果是相同的。所以得出这种类比推理的结论的方法就是,当算法被问及 man 对 woman 相当于 king 对什么时,算法所做的就是计算,然后找出一个向量也就是找出一个词,使得,也就是说,当这个新词是 queen时,式子的左边会近似地等于右边。
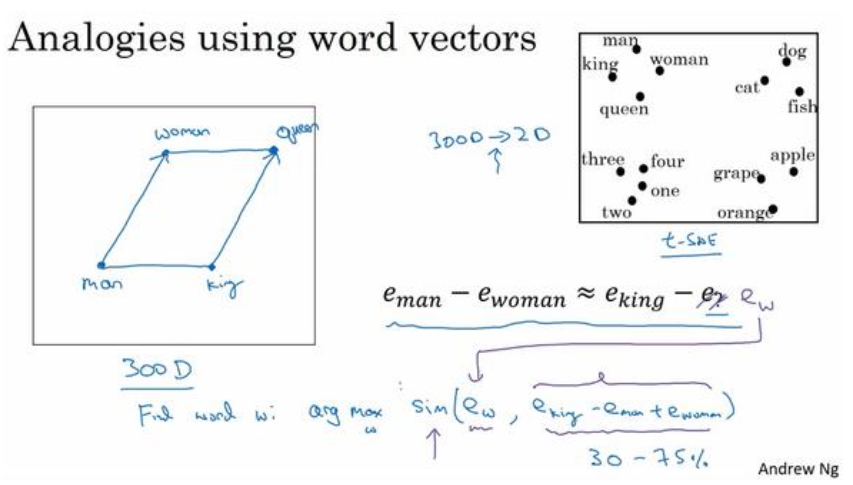
计算当 man 对于 woman,那么 king 对于什么,能做的就是找到单词 w 来使得这个等式成立,就是找到单词 w 来最大化与的相似度,即
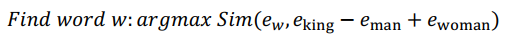
测算 与的相似度,我们最常用的相似度函数叫做余弦相似度。


2. 生成词向量的方式
2.1. 基于统计方法
1. 共现矩阵
通过统计一个事先指定大小的窗口内的word共现次数,以word周边的共现词的次数做为当前word的vector。具体来说,我们通过从大量的语料文本中构建一个共现矩阵来定义word representation。
例如,有语料如下:
I like deep learning.
I like NLP.
I enjoy flying.
则其共现矩阵如下: 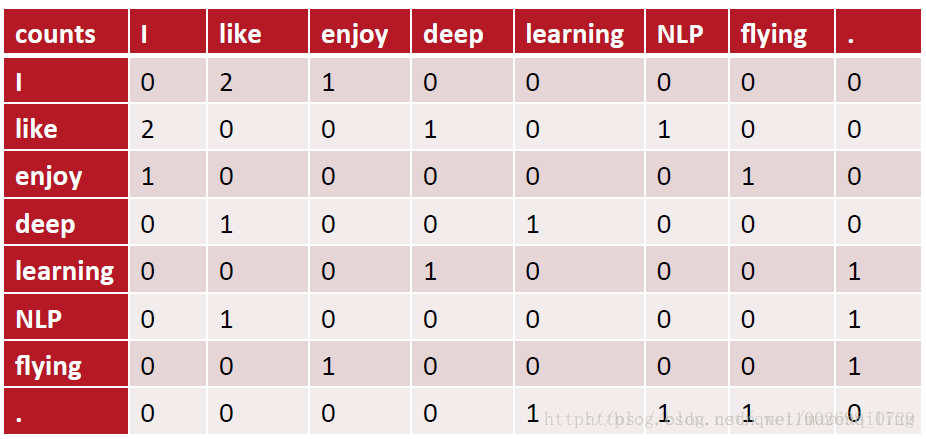
矩阵定义的词向量在一定程度上缓解了one-hot向量相似度为0的问题,但没有解决数据稀疏性和维度灾难的问题。
2. SVD(奇异值分解)
既然基于co-occurrence矩阵得到的离散词向量存在着高维和稀疏性的问题,一个自然而然的解决思路是对原始词向量进行降维,从而得到一个稠密的连续词向量。 对1中矩阵进行SVD分解,得到正交矩阵U,对U进行归一化得到矩阵如下: 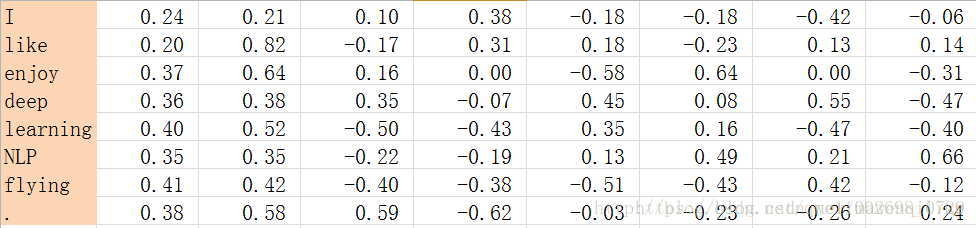
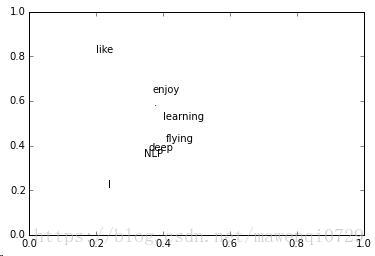
SVD得到了word的稠密(dense)矩阵,该矩阵具有很多良好的性质:语义相近的词在向量空间相近,甚至可以一定程度反映word间的线性关系。
2.2 基于语言模型(language model)
语言模型生成词向量是通过训练神经网络语言模型NNLM(neural network language model),词向量作为语言模型的附带产出。NNLM背后的基本思想是对出现在上下文环境里的词进行预测,这种对上下文环境的预测本质上也是一种对共现统计特征的学习。 较著名的采用neural network language model生成词向量的方法有:Skip-gram、CBOW、LBL、NNLM、C&W、GloVe等。接下来,以word2vec为例,讲解基于神经网络语言模型的词向量生成。

3. CBOW与Skip-Gram
3.1 CBOW与Skip-Gram用于神经网络语言模型
在word2vec出现之前,已经有用神经网络DNN来用训练词向量进而处理词与词之间的关系了。采用的方法一般是一个三层的神经网络结构(当然也可以多层),分为输入层,隐藏层和输出层(softmax层)。
这个模型是如何定义数据的输入和输出呢?一般分为CBOW(Continuous Bag-of-Words 与Skip-Gram两种模型。
1. CBOW模型
CBOW模型,利用上下文或周围的单词来预测中心词。
输入:某一个特征词的上下文相关对应的词向量(单词的one-hot编码);输出:这特定的一个词的词向量(单词的one-hot编码)。
比如下面这段话,我们的上下文大小取值为4,特定的这个词是”Learning”,也就是我们需要的输出词向量(单词Learning的one-hot编码),上下文对应的词有8个,前后各4个,这8个词是我们模型的输入(8个单词的one-hot编码)。由于CBOW使用的是词袋模型,因此这8个词都是平等的,也就是不考虑他们和我们关注的词之间的距离大小,只要在我们上下文之内即可。
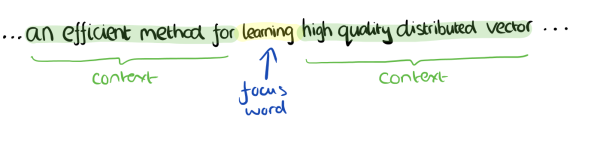
这样我们这个CBOW的例子里,我们的输入是8个词向量(8个单词的one-hot编码),输出是所有词的softmax概率(训练的目标是期望训练样本中心词对应的softmax概率最大);对应的CBOW神经网络模型输入层有8个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。通过DNN的反向传播算法,我们可以求出DNN模型的参数,同时得到所有的词对应的词向量。这样当我们有新的需求,要求出某8个词对应的最可能的输出中心词时,我们可以通过一次DNN前向传播算法并通过softmax激活函数找到概率最大的词对应的神经元即可。
2. Skip-gram模型
Skip-gram模型,使用中心词来预测上下文词。
Skip-Gram模型和CBOW的思路是反着来的(互为镜像),即输入是特定的一个词的词向量(单词的one-hot编码),而输出是特定词对应的上下文词向量(所有上下文单词的one-hot编码)。还是上面的例子,我们的上下文大小取值为4, 特定的这个词”Learning”是我们的输入,而这8个上下文词是我们的输出。
这样我们这个Skip-Gram的例子里,我们的输入是特定词, 输出是softmax概率排前8的8个词,对应的Skip-Gram神经网络模型输入层有1个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。通过DNN的反向传播算法,我们可以求出DNN模型的参数,同时得到所有的词对应的词向量。这样当我们有新的需求,要求出某1个词对应的最可能的8个上下文词时,我们可以通过一次DNN前向传播算法得到概率大小排前8的softmax概率对应的神经元所对应的词即可。
所以,只要简单理解为CBOW与Skip-Gram互为镜像,输入/输出都是词的one-hot编码,训练上下文->中心词/中心词->上下文词的关系权重就可以了。
以上就是神经网络语言模型中如何用CBOW与Skip-Gram来训练模型与得到词向量的大概过程。但是这和word2vec中用CBOW与Skip-Gram来训练模型与得到词向量的过程有很多的不同。
word2vec为什么不用现成的DNN模型,要继续优化出新方法呢?最主要的问题:DNN模型的这个处理过程非常耗时。我们的词汇表一般在百万级别以上,这意味着我们DNN的输出层需要进行softmax计算各个词的输出概率,计算量很大。有没有简化一点点的方法呢?
3.2 word2vec中的CBOW与Skip-Gram
word2vec也使用了CBOW与Skip-Gram来训练模型与得到词向量,但是并没有使用传统的DNN模型,而是对其进行了改进。最先优化使用的数据结构是用霍夫曼树来代替隐藏层和输出层的神经元。
叶子节点:起到输出层神经元的作用,叶子节点的个数即为词汇表的大小。
内部节点:起到隐藏层神经元的作用。
霍夫曼树编码方式:一般对于一个霍夫曼树的节点(根节点除外),可以约定左子树编码为0,右子树编码为1。
Word2vec中,约定编码方式和霍夫曼相反,即约定左子树编码为1,右子树编码为0,同时约定左子树的权重不小于右子树的权重。
1. CBOW模型
连续词袋模型(Continuous Bag-of-Word Model, CBOW)是一个三层神经网络,输入已知上下文,输出对下个单词的预测:
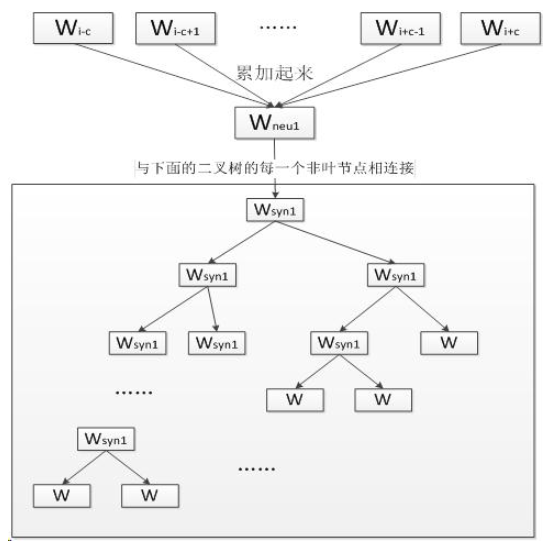
CBOW模型的第一层是输入层, 输入已知上下文的词向量;
中间一层称为线性隐含层, 它将所有输入的词向量累加求和(或累加求和取平均);
第三层是一棵哈夫曼树, 树的的叶节点与语料库中的单词一一对应, 而树的每个非叶节点是一个二分类器(一般是softmax感知机等), 树的每个非叶节点都直接与隐含层相连.
将上下文的词向量输入CBOW模型, 由隐含层累加得到中间向量,将中间向量输入哈夫曼树的根节点, 根节点会将其分到左子树或右子树。每个非叶节点都会对中间向量进行分类, 直到达到某个叶节点,该叶节点对应的单词就是对下个单词的预测。
训练过程:
首先根据预料库建立词汇表, 词汇表中所有单词拥有一个随机的词向量。我们从语料库选择一段文本进行训练;
将单词W的上下文的词向量输入CBOW, 由隐含层累加, 在第三层的哈夫曼树中沿着某个特定的路径到达某个叶节点, 从给出对单词W的预测。
训练过程中我们已经知道了单词W, 根据W的哈夫曼编码我们可以确定从根节点到叶节点的正确路径, 也确定了路径上所有分类器应该作出的预测.
我们采用梯度下降法调整输入的词向量, 使得实际路径向正确路径靠拢。在训练结束后我们可以从词汇表中得到每个单词对应的词向量。
2. Skip-gram
Skip-gram模型同样是一个三层神经网络,skip-gram模型的结构与CBOW模型正好相反,skip-gram模型输入某个单词,输出对它上下文词向量的预测。
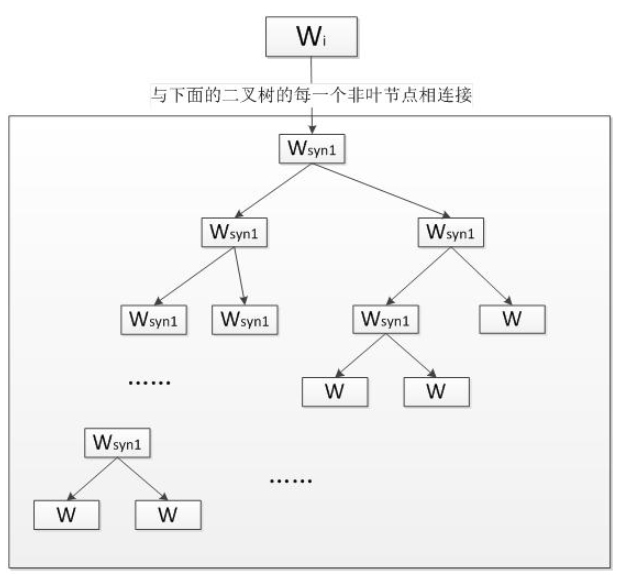
Skip-gram的核心同样是一个哈夫曼树, 每一个单词从树根开始到达叶节点,可以预测出它上下文中的一个单词。对每个单词进行N-1次迭代,得到对它上下文中所有单词的预测, 根据训练数据调整词向量得到足够精确的结果。
模型实现代码:NeuralNetDemo: Neural Network Demo powered by tensorflow – Gitee.com
word2vec有两种改进方法,一种是基于Hierarchical Softmax的,另一种是基于Negative Sampling(负采样)。两种改进方式细节请跳转:word2vec的两种改进方法:Hierarchical Softmax(层序softmax)和Negative Sampling(负采样)
Hierarchical Softmax:对CBOW和Skip-Gram的损失结构进行了改进,
Negative Sampling:改进了模型训练,之前模型输出是每个单词的得分值,使用负采样之后输出是0(非临近词)和1(临近词),所以效率提高。
参考:
1. NLP系列(10)_词向量之图解Word2vec:图解
处理向量时,计算相似度得分的常用方法是余弦相似度
one-hot编码——(维度灾难)——>分布式编码————>神经网络语言模型:CBOW、skipgram——(输出softmax,耗时)——>逻辑回归模型(标签值:值为0或1的新列,0=“不是邻居”,1=“邻居”)——>负采样——(在数据集中引入负样本:不是邻居的单词样本)——>
未完待续。。。。。。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/196372.html原文链接:https://javaforall.net

![STM32F4(用SysTick实现Delay函数)[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
