
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
LISTAGG 函数介绍
listagg 函数是 Oracle 11.2 推出的新特性。
其主要功能类似于 wmsys.wm_concat 函数, 即将数据分组后, 把指定列的数据再通过指定符号合并。
LISTAGG 使用
listagg 函数有两个参数:
1、 要合并的列名
2、 自定义连接符号
☆LISTAGG 函数既是分析函数,也是聚合函数
所以,它有两种用法:
1、分析函数,如: row_number()、rank()、dense_rank() 等,用法相似
listagg(合并字段, 连接符) within group(order by 合并的字段的排序) over(partition by 分组字段)
2、聚合函数,如:sum()、count()、avg()等,用法相似
listagg(合并字段, 连接符) within group(order by 合并字段排序) --后面跟 group by 语句
(补充)分析函数和聚合函数
一部分聚合函数其实也可以写成分析函数的形式。
分析函数和聚合函数本质上都是对数据进行分组,二者最大的不同便是:
对数据进行分组分组之后,
聚合函数只会每组返回一条数据,
而分析函数会针对每条记录都返回,
一部分分析函数还会对同一组中的数据进行一些处理(比如:rank() 函数对每组中的数据进行编号);
还有一部分分析函数不会对同一组中的数据进行处理(比如:sum()、listagg()),这种情况下,分析函数返回的数据会有重复的,distinct 处理之后的结果与对应的聚合函数返回的结果一致。
LISTAGG 实例
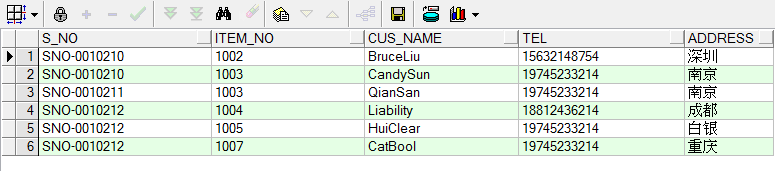
先构造几笔临时数据
with test as(
SELECT 'SNO-0010210' S_NO,'1002' ITEM_NO,'BruceLiu' CUS_NAME,'15632148754' TEL,'深圳' ADDRESS FROM DUAL
UNION
SELECT 'SNO-0010210' S_NO,'1003' ITEM_NO, 'CandySun' CUS_NAME,'19745233214' TEL, '南京' ADDRESS FROM DUAL
UNION
SELECT 'SNO-0010211' S_NO, '1003' ITEM_NO,'QianSan' CUS_NAME,'19745233214' TEL,'南京' ADDRESS FROM DUAL
UNION
SELECT 'SNO-0010212' S_NO,'1005' ITEM_NO,'HuiClear' CUS_NAME,'19745233214' TEL,'白银' ADDRESS FROM DUAL
UNION
SELECT 'SNO-0010212' S_NO,'1007' ITEM_NO,'CatBool' CUS_NAME,'19745233214' TEL,'重庆' ADDRESS FROM DUAL
UNION
SELECT 'SNO-0010212' S_NO,'1004' ITEM_NO,'Liability' CUS_NAME,'18812436214' TEL,'成都' ADDRESS FROM DUAL
)

LISTAGG 分析函数用法
SELECT T.S_NO,
LISTAGG(T.ITEM_NO, '/') WITHIN GROUP(ORDER BY T.S_NO, T.ITEM_NO) ITEM_NO,
LISTAGG(T.CUS_NAME, '/') WITHIN GROUP(ORDER BY T.S_NO, T.ITEM_NO) CUS_NAME,
LISTAGG(T.TEL, '/') WITHIN GROUP(ORDER BY T.S_NO, T.ITEM_NO) TEL,
LISTAGG(T.ADDRESS, '/') WITHIN GROUP(ORDER BY T.S_NO, T.ITEM_NO) ADDRESS
FROM test T
GROUP BY T.S_NO;

LISTAGG 聚合函数用法
SELECT T.S_NO,
LISTAGG(T.ITEM_NO, '/') WITHIN GROUP(ORDER BY T.S_NO, T.ITEM_NO) OVER(PARTITION BY T.S_NO) ITEM_NO,
LISTAGG(T.CUS_NAME, '/') WITHIN GROUP(ORDER BY T.S_NO, T.ITEM_NO) OVER(PARTITION BY T.S_NO) CUS_NAME,
LISTAGG(T.TEL, '/') WITHIN GROUP(ORDER BY T.S_NO, T.ITEM_NO) OVER(PARTITION BY T.S_NO) TEL,
LISTAGG(T.ADDRESS, '/') WITHIN GROUP(ORDER BY T.S_NO, T.ITEM_NO) OVER(PARTITION BY T.S_NO) ADDRESS
FROM test T;

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/196411.html原文链接:https://javaforall.net


