
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
skip-gram是利用中间词预测邻近词
cbow是利用上下文词预测中间词
一、CBOW
1、continues bag of words。其本质是通过context来预测word。
CBOW之所以叫连续词袋模型,是因为在每个窗口内它也不考虑词序信息,因为它是直接把上下文的词向量相加了,自然就损失了词序信息。CBOW抛弃了词序信息,指的就是在每个窗口内部上下文直接相加而没有考虑词序。
2、CBOW过程
简单介绍如下(实际算法会用到哈夫曼编码等降维技巧,这里仅以理解为目的简介基本原理):
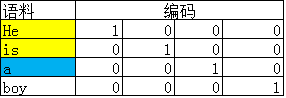

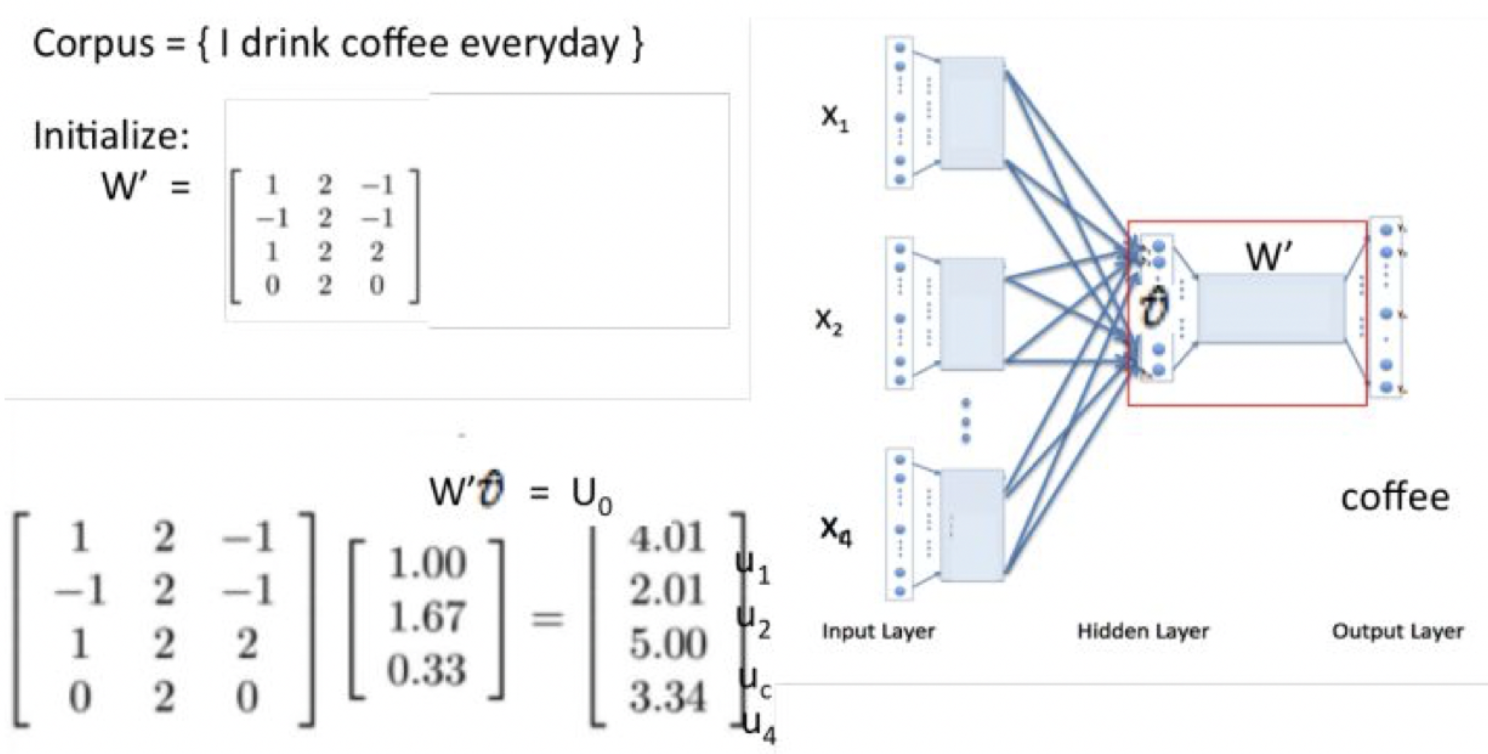
如上图所示,首先语料库内的每个word都可以用one-hot的方式编码。假设选取Context Window为2,那么模型中的一对input和target就是:
- input:He和is的one-hot编码
- target:a的one-hot编码
- 输入为C个V维的vector。其中C为上下文窗口的大小,V为原始编码空间的规模。例如,示例中的C=2,V=4.两个vector分别为4维的He和is的one-hot编码形式;
- 激活函数相当简单,在输入层和隐藏层之间,每个input vector分别乘以一个VxN维度的矩阵,得到后的向量各个维度做平均,得到隐藏层的权重。隐藏层乘以一个NxV维度的矩阵,得到output layer的权重;
- 隐藏层的维度设置为理想中压缩后的词向量维度。示例中假设我们想把原始的4维的原始one-hot编码维度压缩到2维,那么N=2;
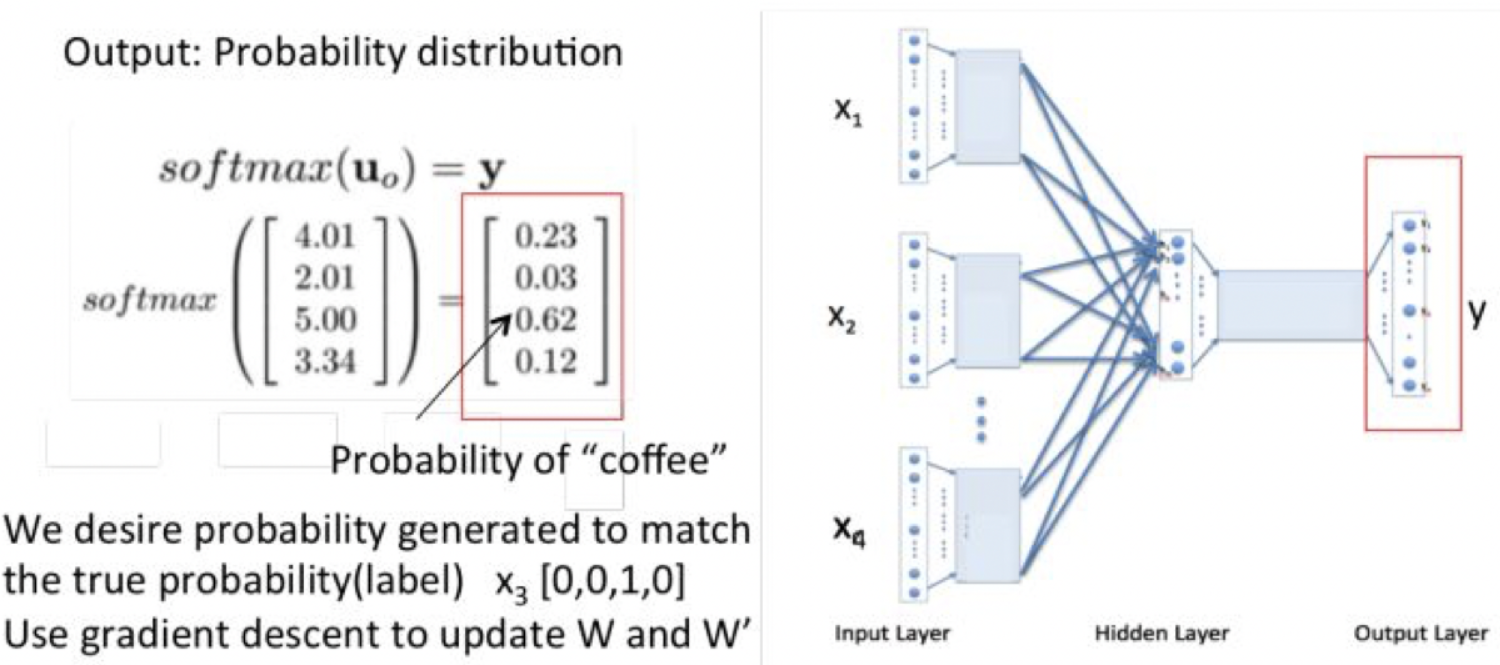
- 输出层是一个softmax层,用于组合输出概率。所谓的损失函数,就是这个output和target之间的的差(output的V维向量和input vector的one-hot编码向量的差),该神经网络的目的就是最小化这个loss;
- 优化结束后,隐藏层的N维向量就可以作为Word-Embedding的结果。
如此一来,便得到了既携带上下文信息,又经过压缩的稠密词向量(维度经过压缩便于运算)。
输入层(C × V)——> 输入*矩阵W(V × N)得到隐藏层——> 平均 ——> * W’ (N × V)——> 输出层 ——> softmax
3、
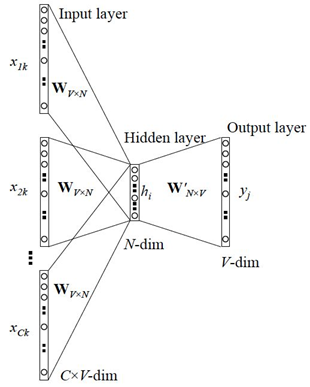
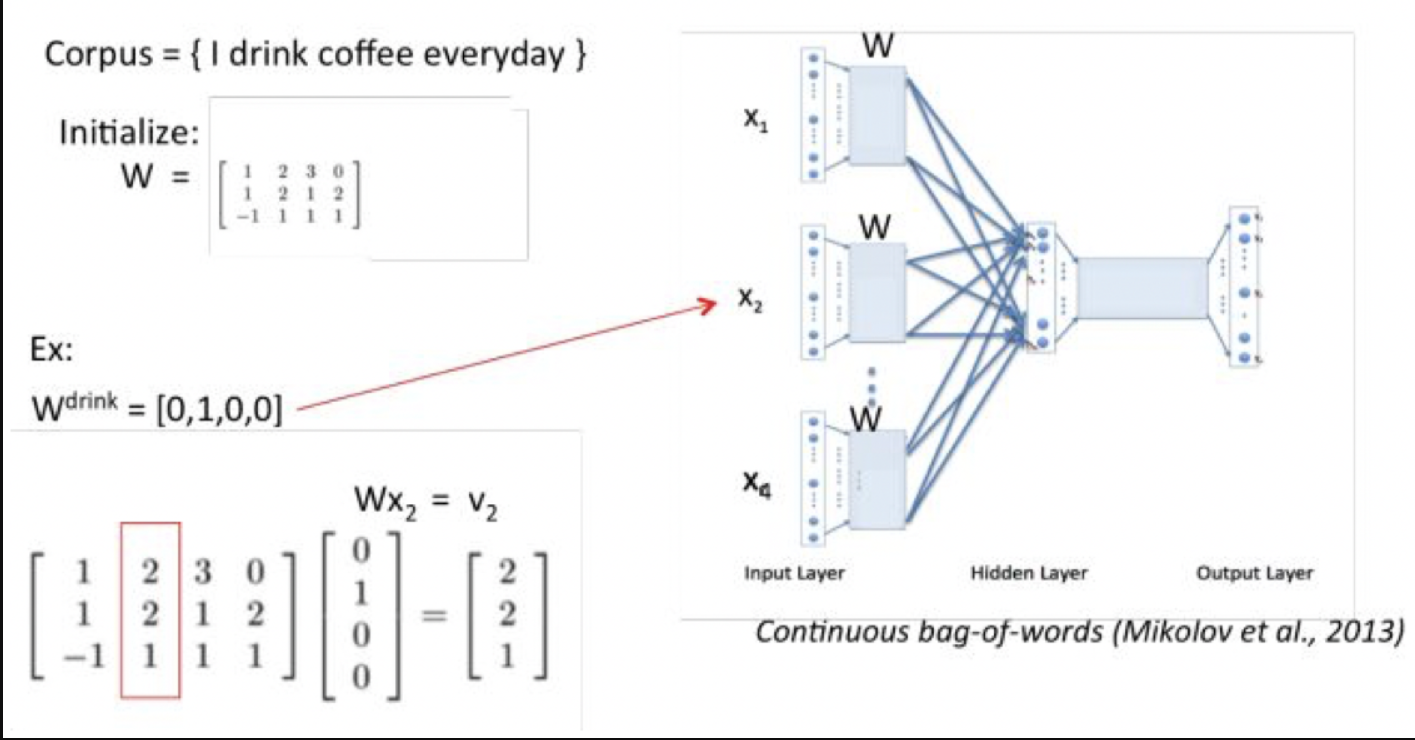
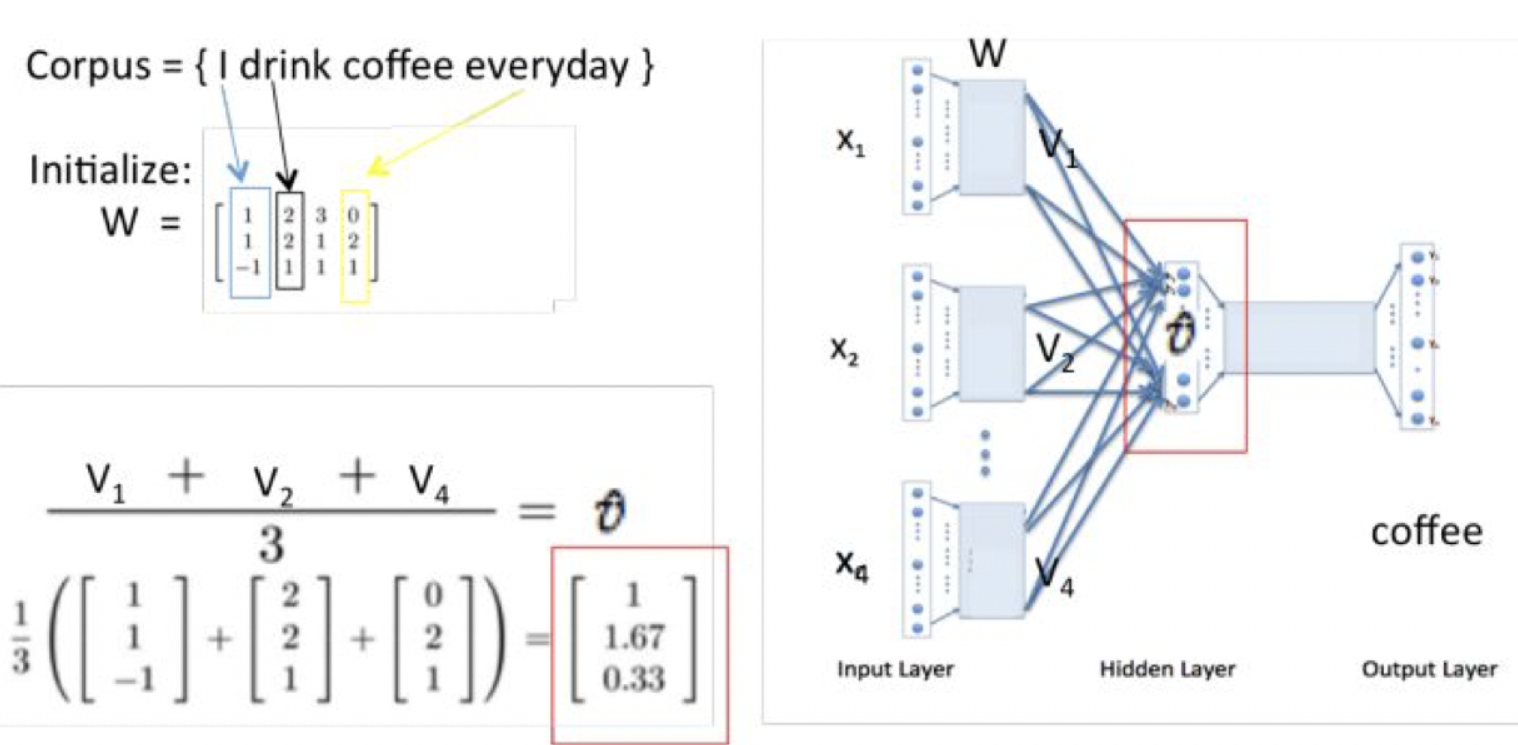
CBOW模型窗口内部抛弃了词序信息,对语言来说语序是很重要的,‘我爱你’的词袋特征是‘我’ ‘爱’ ‘你’ ,‘你爱我’的词袋特征是‘你’ ‘爱’ ‘我’,这两个句子的特征是完全相同的,但是这两个句子的语义是不一样的,如果在CBOW窗口内加入n-gram特征(比如2-gram)就会得到额外的信息,第一个句子的2gram特征是‘我爱’和‘爱你’,第二个句子的特征是‘你爱’ 和‘爱我’,这样就把上下文完全相同的两个句子区分开了,这种做法就是fastText的做法。
二、skip-gram
1、核心:
通过查看所有语料的词作为中心词时,其(中心词)与上下文的2m个词语的所有共现情况,这样就得到我们要逼近的中心词与上下文对应关系的条件概率分布(这个概率分布是忽视掉了上下文词语间的顺序的),我们通过模型去训练出词典中心词向量矩阵和词典上下文词向量矩阵(这两个矩阵就是存储了语料中中心词与其上下文的对应关系信息)。
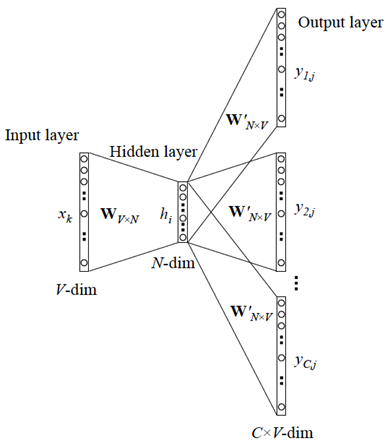
2、【窗口大小(上下文词语数量m)】
即指定中心词后我们关注的上下文数量定为该中心词前m个词和后m个词(一共2m个上下文词)。
3、【词典中心词向量矩阵(下图d×V维的 W 矩阵)】
通俗来说词典中心词向量矩阵是由词典中的一个单词的词向量组合而成的(每一列就是词典中的一个单词的词向量),而每一个词的词向量就是假设我们的词典包含了d个维度的抽象信息。
4、【词典上下文词向量矩阵(下图的V×d维的 W’ 矩阵)】
类似词典中心词向量矩阵,但这里的词向量中d个维度储存的抽象信息,是作为上下文的词而言,它与中心词之间的对应关系信息。
5、【最后Softmax归一化后输出的概率向量(下图p(x|c)】
就是词典中每个词成为当前指定中心词的上下文的概率。我们要让这个概率向量,逼近真实语料中基于指定中心词基础上这些上下文词语出现的条件概率分布。
6、举例
设 y 是 x 的上下文,所以 y 只取上下文里一个词语的时候,语言模型就变成:用当前词 x 预测它的下一个词 y
第一步:x的输入,one-hot encoder形式,本质上是用一个只含一个 1、其他都是 0 的向量来唯一表示词语。
假设全世界所有的词语总共有 V 个,则x1, x2, … xk … xv。
输出y 是在这 V 个词上输出的概率,y1,y2,… yj …yv。
第二步:Skip-gram 的网络结构
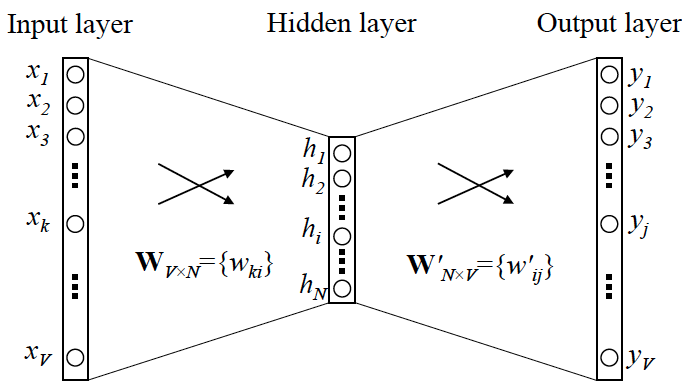
第三步:当模型训练完后,最后得到的其实是神经网络的权重
比如现在输入一个 x 的 one-hot encoder: [1,0,0,…,0],对应刚说的那个词语『吴彦祖』,则在输入层到隐含层的权重里,只有对应 1 这个位置的权重被激活,这些权重的个数,跟隐含层节点数(N)是一致的,从而这些权重组成一个向量 vx 来表示x,而因为每个词语的 one-hot encoder 里面 1 的位置是不同的,所以,这个向量 vx 就可以用来唯一表示 x。
7、总结:
输入是One-Hot Vector,Hidden Layer没有激活函数,也就是线性的单元。Output Layer维度跟Input Layer的维度一样,用的是Softmax回归。当这个模型训练好以后,我们并不会用这个训练好的模型处理新的任务,我们真正需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。
Skip-gram每一轮指定一个中心词的2m个上下文词语来训练该中心词词向量和词典上下文词向量,下一轮则指定语料中下一个中心词,查看其2m个上下文词语来训练。
参考资料:【原创】关于skip-gram的个人理解 – 海上流星 – 博客园
最终优化:https://www.jianshu.com/p/8e291e4ba0da
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/196557.html原文链接:https://javaforall.net


