
#include
#include
#include
#include
using namespace std; typedef char ElemType; typedef struct { ElemType elem; unsigned int weight; unsigned int parent, lchild, rchild, tag; }HTNode, * HuffmanTree; typedef char HuffmanCode; typedef int Status; typedef struct weight { char elem; unsigned int m_weight; }Weight; void Select(HuffmanTree HT, int n, int& s1, int& s2) { int i; s1 = s2 = 0; for (i = 1; i <= n; i++) { if (HT[i].weight < HT[s2].weight && HT[i].parent == 0 && s2 != 0) { if (HT[i].weight < HT[s1].weight) { s2 = s1; s1 = i; } else s2 = i; } if ((s1 == 0 || s2 == 0) && HT[i].parent == 0) { if (s1 == 0) s1 = i; else if (s2 == 0) { if (HT[i].weight < HT[s1].weight) { s2 = s1; s1 = i; } else s2 = i; } } } if (s1 > s2) { i = s1; s1 = s2; s2 = i; } } void HuffmanCoding(HuffmanTree& HT, HuffmanCode& HC, Weight*& w, int n) { // w存放n个字符的权值(均>0),构造哈夫曼树HT, // 并求出n个字符的哈夫曼编码HC //本函数实现选择方式:从左往右选择两个小权值结点,结点信息在前面的为左子树,其后为右子树 int i, j, m, s1, s2; char* cd; int p; int cdlen; if (n <= 1) return; m = 2 * n - 1; HT = (HuffmanTree)malloc((m + 1) * sizeof(HTNode)); // 0号单元未用 for (i = 1; i <= n; i++) { //初始化 HT[i].elem = w[i - 1].elem; HT[i].weight = w[i - 1].m_weight; HT[i].parent = 0; HT[i].lchild = 0; HT[i].rchild = 0; } for (i = n + 1; i <= m; i++) { //初始化 HT[i].weight = 0; HT[i].parent = 0; HT[i].lchild = 0; HT[i].rchild = 0; } printf("\n哈夫曼树的构造过程如下所示:\n"); printf("HT初态:\n 结点 weight parent lchild rchild"); for (i=1; i<=m; i++) printf("\n%4d%8d%8d%8d%8d",i,HT[i].weight, HT[i].parent,HT[i].lchild, HT[i].rchild); getchar(); for (i = n + 1; i <= m; i++) { // 建哈夫曼树 // 在HT[1..i-1]中选择parent为0且weight最小的两个结点, // 其序号分别为s1和s2。 Select(HT, i - 1, s1, s2); HT[s1].parent = i; HT[s2].parent = i; HT[i].lchild = s1; HT[i].rchild = s2; HT[i].weight = HT[s1].weight + HT[s2].weight; printf("\nselect: s1=%d s2=%d\n", s1, s2); printf(" 结点 weight parent lchild rchild"); for (j=1; j<=i; j++) printf("\n%4d%8d%8d%8d%8d",j,HT[j].weight, HT[j].parent,HT[j].lchild, HT[j].rchild); getchar(); } //------无栈非递归遍历哈夫曼树,求哈夫曼编码 HC = (HuffmanCode)malloc((n + 1) * sizeof(char*)); cd = (char*)malloc((n + 1) * sizeof(char)); // 分配求编码的工作空间 p = m; cdlen = 0; for (i = 1; i <= m; ++i) // 遍历哈夫曼树时用作结点状态标志 HT[i].tag = 0; while (p) { if (HT[p].tag == 0) { // 向左 HT[p].tag = 1; if (HT[p].lchild != 0) { p = HT[p].lchild; cd[cdlen++] = '0'; } else if (HT[p].rchild == 0) { HC[p] = (char*)malloc((cdlen + 1) * sizeof(char)); cd[cdlen] = '\0'; strcpy(HC[p], cd); } } else if (HT[p].tag == 1) { // 向右 HT[p].tag = 2; if (HT[p].rchild != 0) { p = HT[p].rchild; cd[cdlen++] = '1'; } } else { // HT[p].weight==2,退回退到父结点,编码长度减1 HT[p].tag = 0; p = HT[p].parent; --cdlen; } } } void OutputHuffmanCode(HuffmanTree HT, HuffmanCode HC, int n) { int i; printf("\nnumber---element---weight---huffman code\n"); for (i = 1; i <= n; i++) printf(" %d %c %d %s\n", i, HT[i].elem, HT[i].weight, HC[i]); } int main() { HuffmanTree HT; HuffmanCode HC; Weight* w; char c; // the symbolizes; int i, n; // the number of elements; int wei; // the weight of a element; printf("请输入准备构建哈夫曼树的结点数:"); cin >> n; //cout<
2.程序结果:
1)程序运行,我使用的测试数据如下所示:


2)首先按照要求完成了哈夫曼树的构建:
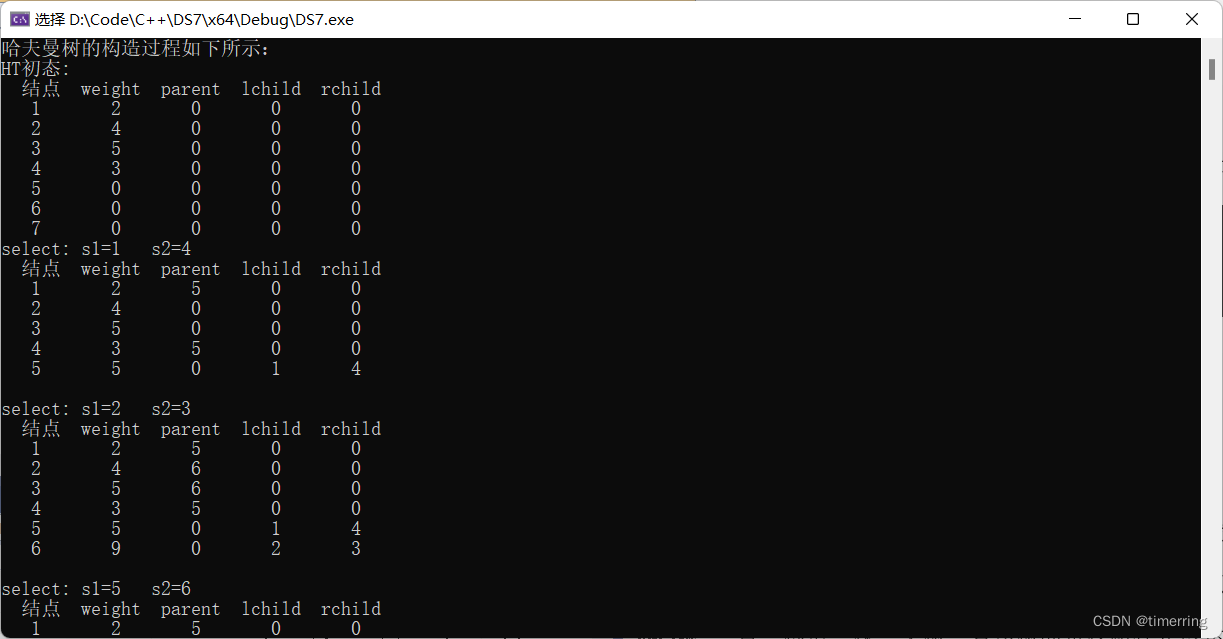
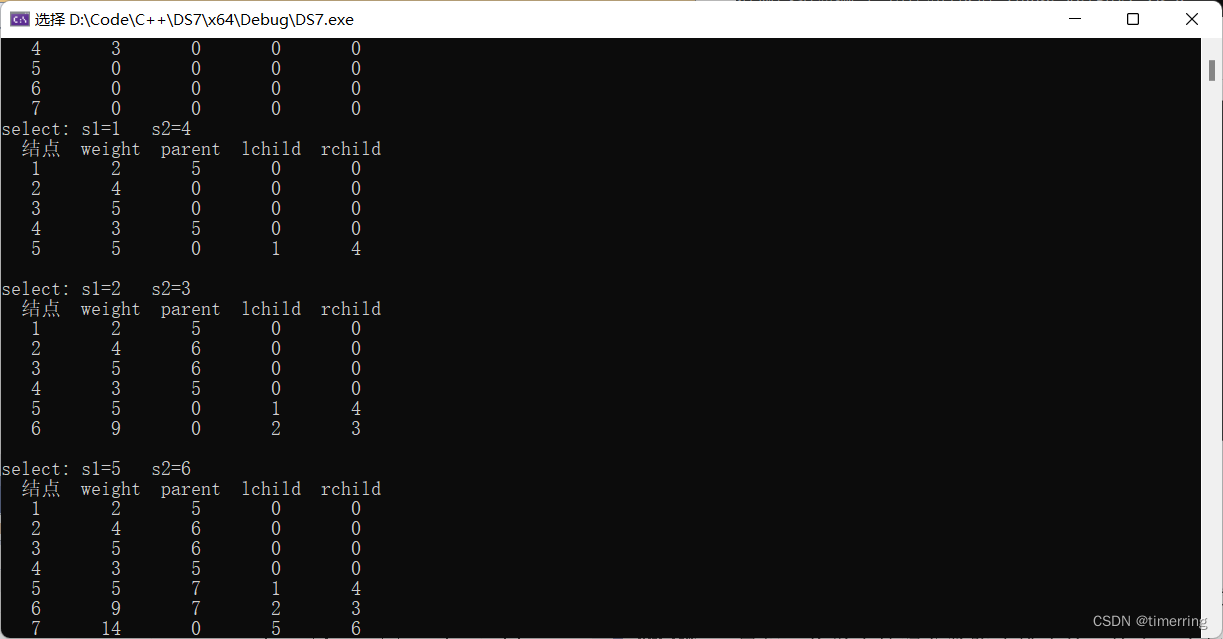
3)最终完成哈夫曼编码,结果与预期一致。

六 、小结:
此次是关于哈夫曼树的编程与实现,通常给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
我先输入了权值的 n 个结点,并且在构建哈夫曼树时我采用了如下办法:首先在 n 个权值中选出两个最小的权值,对应的两个结点组成一个新的二叉树,且新二叉树的根结点的权值为左右孩子权值的和;在原有的 n 个权值中删除那两个最小的权值,同时将新的权值加入到 n–2 个权值的行列中,以此类推;重复上述过程,直到所以的结点构建成了一棵二叉树为止,就得到了哈夫曼树。通常查找权重值最小的两个结点的思想是:从树组起始位置开始,首先找到两个无父结点的结点(说明还未使用其构建成树),然后和后续无父结点的结点依次做比较,有两种情况需要考虑:如果比两个结点中较小的那个还小,就保留这个结点,删除原来较大的结点;如果介于两个结点权重值之间,替换原来较大的结点。最终实现了描述的功能。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/199200.html原文链接:https://javaforall.net

![解决ubuntu16.04中codeblocks中文显示不全的问题[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
