
- 引言
隐马尔可夫模型(Hidden Markov model, HMM)是用于序列标注的概率图模型,描述一个隐藏的马尔科夫链生成不可观测的状态序列,再由每个状态生成一个观测而产生一个观测序列的过程,是一个生成模型。隐马尔可夫模型在自然语言处理、语音识别、模式识别等领域都应用广泛。在自然语言处理中,基于字标注的分词、词性标注、句法分析、命名实体识别等领域都可以应用隐马尔可夫模型。
虽然现在深度学习大行其道,HMM(在训练数据充足的情况下)也不如条件随机场(Conditional Random Field,CRF)强大,但是HMM依然是经典的统计分析模型,HMM包含的一些基本原理和概念,是学习其他算法的基础,比如随机采样中的马尔可夫-蒙特卡洛方法(Markov Chain Monte Carlo)用马尔科夫链产生样本序列,CRF中的随机场即马尔可夫随机场。因此,接下去我们简单的学习一下隐马尔科夫模型。
2. 隐马尔科夫模型的框架
隐马尔可夫模型的基础内容其实非常简单,总结起来只需要记住“1、2、3”,即1个元组,2个假设,3个问题。
2.1 一个元组
1个元组就是隐马尔可夫模型的参数元组,即组成隐马尔科夫模型的要素。一般来说是一个三元组 或者一个五元组 。五元组比三元组多了一个可能的状态集合Q和可能的观测集合V。Q和V是模型预设而不需要训练的参数(可认为是两个超参数),A,B, 是隐马尔可夫模型需要训练的参数。
A表示状态转移概率矩阵。假设可能的状态集合Q总共有N个状态,则A是一个N*N的方阵,即![A=[a_{ij}]_{N\times N}](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450.jpg) ,表示t时刻从状态i转移到t+1时刻状态j的概率:
,表示t时刻从状态i转移到t+1时刻状态j的概率:
注意这里包含了一个隐含的约束,从状态i转移到所有状态(包括他自己)的概率和为1即。
B表示符号发射概率(仿射概率)矩阵。假设可能的状态集合Q共N个状态,可能的观测集合总共由M个观测,则B是一个N*M的矩阵,即,其中表示t时刻从状态j生成观测k的概率:
同样这里包含一个隐含约束条件。
是初始状态概率分布向量,即在初始时刻(t=1)状态的概率分布,其中。
2.2 两个假设
三元组决定了隐马尔可夫模型,和A决定了如何从隐藏的马尔可夫链生成状态序列I,B决定了如何从状态序列生成观测序列O。在这个过程中隐马尔可夫模型做了两个基本假设:
(1)齐次马尔可夫性假设。
假设隐藏的马尔科夫链在时刻t的状态只依赖于其前一刻(t-1时刻)的状态而与其他时刻的状态及观测无关,也与时刻t无关:
(2)观测独立性假设。
假设任意时刻的观测只依赖于该时刻的马尔科夫链的状态,与其他观测以及状态无关:
2.3 三个基本问题
隐马尔科夫模型基于以上两个基本假设,生成一个长度为T的观测序列的过程如下:
1)按照初始状态产生状态 ;
2)令t=1
3)按照状态的仿射概率分布生成观测;
4)按照状态的状态转移概率分布产生状态;
5)令t=t+1,如果t小于T转到(3),否则终止;
隐马尔可夫模型的生成如下图所示:
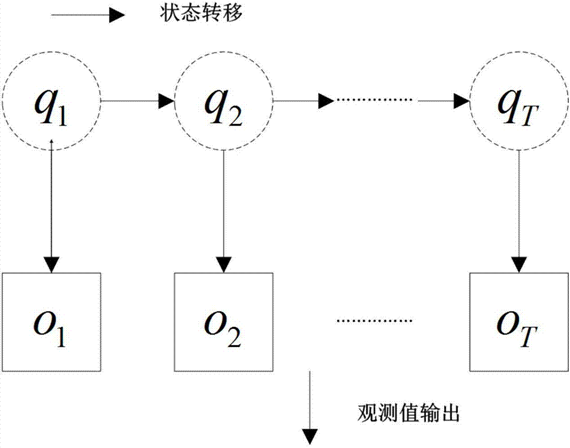
在生成观测序列时我们需要考虑全局最优策略,而且我们更多的时候关心的不是生成的观测而是生成观测的最佳状态序列,所以隐马尔可夫模型有三个基本问题:(1)评估问题;(2)学习问题;(3)解码问题。
2.3.1 评估问题
评估问题是给定模型μ=(A, B, π)和观测序列,计算在模型μ下观测序列O出现的概率P(O | μ)。评估问题是学习问题和解码问题的基础,它为学习问题和解码问题提供了基本要素。先看下面的示意图:
最直接计算概率P(O | μ)的方式是计算每个时刻可能状态的转移概率和生成观测的概率并将所有可能路径的概率相加得到概率P(O | μ)。但是显而易见这种暴力计算的方式计算代价极为高昂,一个包含N个可能状态的HMM模型生成一个长度为T的状态序列的计算复杂度为。
(1)前向概率
给定隐马尔科夫模型μ,定义到时刻t部分观测序列为且状态为的概率为前向概率,记作
前向概率的计算方式如下图所示:
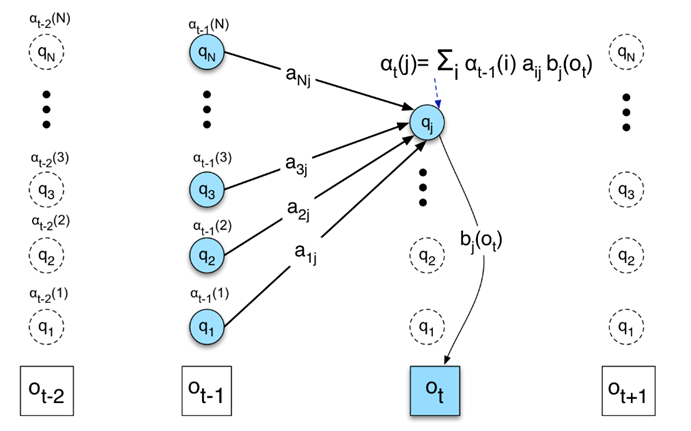
t=1时刻状态i的前向概率为 ,t时刻状态i的前向概率为t-1时刻所有状态的前向概率转移到t时刻状态i的概率之和:
于是可得概率。
(2)后向概率
给定隐马尔科夫模型μ,定义在时刻t状态为的条件下,从t+1到T的部分观测序列为的概率为后向概率,记作
初始化后向概率时,模型规定T时刻的,与前向概率相似,t时刻状态i的后向概率的递推公式为:
递推公式如下图所示:
最终概率。
利用前向概率和后向概率的定义可以将观测序列概率P(O|μ)统一写成:
前向概率和后向概率运用动态规划算法降低了概率计算的复杂度,从暴力计算的降低到了,当T很大时,这个差别将非常大。
2.3.2 学习问题
已知观测序列,学习模型μ=(A, B, π)的参数,使得该模型下观测序列概率P(O | μ)最大。学习问题解决的是隐马尔科夫模型的训练问题,通过训练数据得到模型的参数A,B,π。根据训练数据是否包含观测序列相应的状态序列,学习问题可以用监督学习和无监督学习的方式训练。
监督学习的方式,是给定训练数据包含S个长度相同的观测序列和对应的状态序列,利用极大似然估计来估计隐马尔科夫模型的参数:
(1)转移概率的估计
设样本中时刻t处于状态i时刻t+1转移到状态j的频数为,那么状态转移概率的估计是:
(2)观测概率的估计
设样本中状态为j并观测为k的频数,那么状态为j观测为k的概率的估计是:
(3)初始状态概率πi的估计为S个样本中初始状态为的频率。
当 给定训练数据只包含S个长度为T的观测序列而没有对应的状态序列时,那么隐马尔科夫模型是一个以观测序列数据为观测数据O,以状态序列数据为不可观测隐数据I的概率模型:
此时参数的学习可以使用Baum-Welch算法实现,这是一种期望最大化算法(EM算法)。Baum-Welch算法的输入输如下:
输入:观测数据
输出:隐马尔科夫模型参数 μ = (A, B, π)
令则算法步骤如下:
(1)初始化
对 n=0,选取,得到模型。
(2)递推。对n=1,2,……,
上面几式等号右边以观测和模型计算。式中
其中是前向概率,是后向概率。
(3)终止。得到模型参数。
Baum-Welch算法也叫前向-后向算法,因为其中的参数计算用到了前向概率和后向概率。第二步递推公式在李航博士的《统计学习方法论》的隐马尔可夫模型一章给出了详细的推导,有兴趣的读者可以仔细阅读。
2.3.3 解码问题:
已知模型μ=(A, B, π)和观测序列,求对给定观测序列条件概率P(I | O)最大的状态序列,即给定观测序列,求最有可能的对应的状态序列。在参数学习完成之后,解码问题是隐马尔科夫模型模型实际应用过程中的预测问题。比如在词性标注中给定由单词组成的句子(观测序列),输出句子单词相应词性的序列(状态序列)。
解决解码问题最直觉的方式,是在每个时刻t选择在该时刻最优可能出现的状态,从而得到一个状态序列,将它作为预测的结果。例如,给定隐马尔科夫模型μ和观测序列O,在时刻t处于状态的概率 γ 如上文的等式所定义,在每一时刻t最有可能的状态是:
从而得到状态序列。这种直接计算的近似算法,计算简单,但是一种典型的贪心算法,没有考虑全局最优,所以缺点是不能保证预测的状态序列整体是最有可能的状态序列。
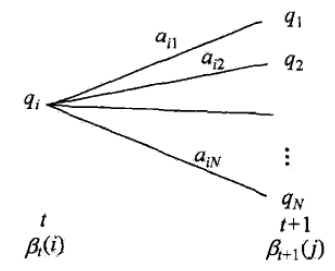
解决解码问题最经典的算法是维特比算法。维特比算法也是动态规划的典型应用。它基于最优路径的这样一个特性:如果最优路径在时刻t通过节点,那么这一路径从节点到终点的部分路径,对于从到的所有可能的部分路径来说,必须是最优的。(至于原因,非常简单,读者可以自行思考一下)
在说明维特比算法之前,我们首先定义维特比变量,为在t时刻状态为i的所有单个路径中概率最大值:
维特比变量的递推公式为:
细心的读者可能已经发现了,维特比变量的递推公式和前向概率(变量)的递推公式十分相似,实际上,前向变量是t时刻状态为i的所有路径的概率之和,维特比变量是t时刻状态为i的单个路径的概率最大值,如下图所示:
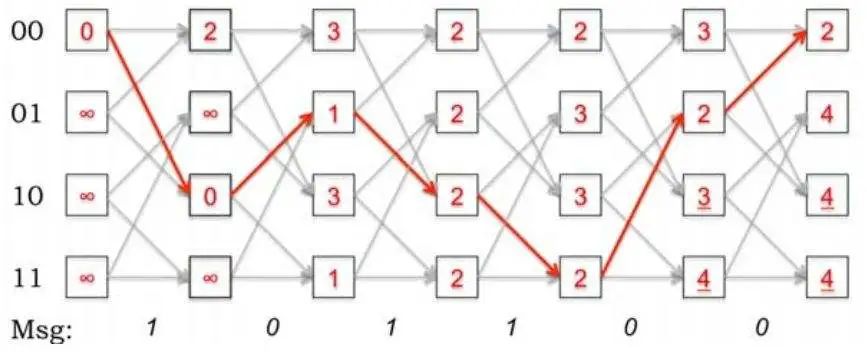
由上图可以看出(实际上上图不是隐马尔科夫模型,但是比较契合维特比变量和前向概率的直观比较,我实在找不到合适的图了),红色的路径代表维特比变量的路径,前向概率的路径是所以路径的加和。除了维特比变量,维特比算法定义了在时刻t状态为i的所有单个路径中概率最大的路径的第t-1个节点的变量:
于是维特比算法流程如下:
输入:模型 μ=(A, B, π) 和观测;
输出:最优路径。
(1)初始化
(2)递推。对t = 2, 3, …… , T
(3)终止
(4)最优路径回溯。对t = T-1, T-2, ……, 1
求得最优路径。
3. 总结
以上就是马尔可夫模型的基本内容,作为一种简单的概率图模型,隐马尔可夫模型有着广泛的应用,例如概率上下文文法可以认为是隐马尔科夫模型模型的一种推广,动态贝叶斯网络(dynamic Bayesian network)包含了隐马尔科夫模型。虽然隐马尔可夫模型也有着一些缺点,比如过强的独立性假设以及标记偏置问题,使得隐马尔可夫模型不像条件随机场那么强大。
同时,在具体的实现过程中,前向概率等应用了动态规划,可以用递归算法实现,但是递归实现的简单性往往会掩盖算法本身的复杂性,当观测序列很长时,尤其是隐马尔科夫模型训练用的是观测序列的总长度,用递归算法往往可能会出现栈溢出的情况,尤其像python这种没有尾递归优化的语言,在实现的时候必须考虑这个问题。总之,隐马尔科夫模型模型是一个相对简单的序列标注模型,有兴趣的读者可以自己实现一下。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/199759.html原文链接:https://javaforall.net


