
说明
- 这是接前面【深度学习】基于Keras的Attention机制代码实现及剖析——Dense+Attention的后续。
参考的代码来源1:Attention mechanism Implementation for Keras.网上大部分代码都源于此,直接使用时注意Keras版本,若版本不对应,在merge处会报错,解决办法为:导入Multiply层并将merge改为Multiply()。
参考的代码来源2:Attention Model(注意力模型)思想初探,这篇也是运行了一下来源1,做对照。 - 在实验之前需要一些预备知识,如RNN、LSTM的基本结构,和Attention的大致原理,快速获得这方面知识可看RNN&Attention机制&LSTM 入门了解。
目录
实验目的
- 现实生活中有很多序列问题,对一个序列而言,其每个元素的“重要性”显然是不同的,即权重不同,这样一来就有使用Attention机制的空间,本次实验将在LSTM基础上实现Attention机制的运用。
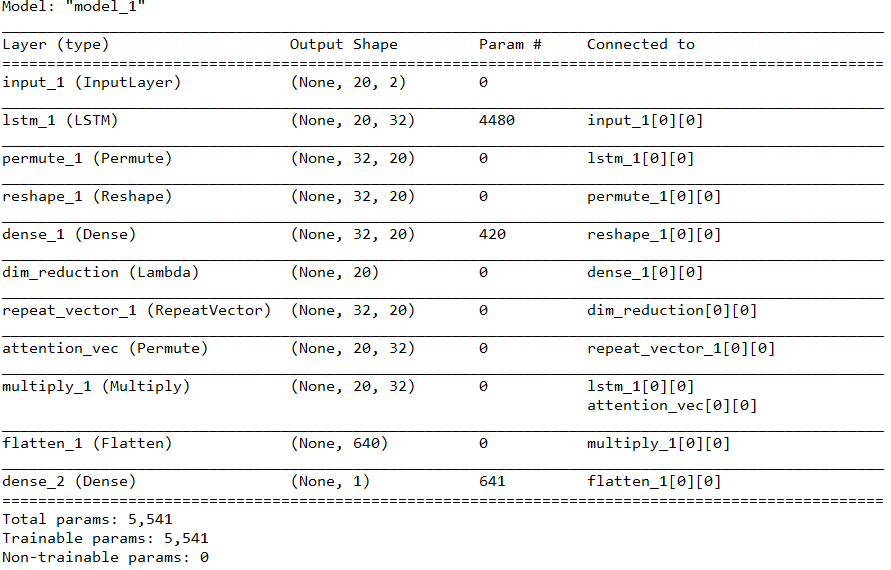
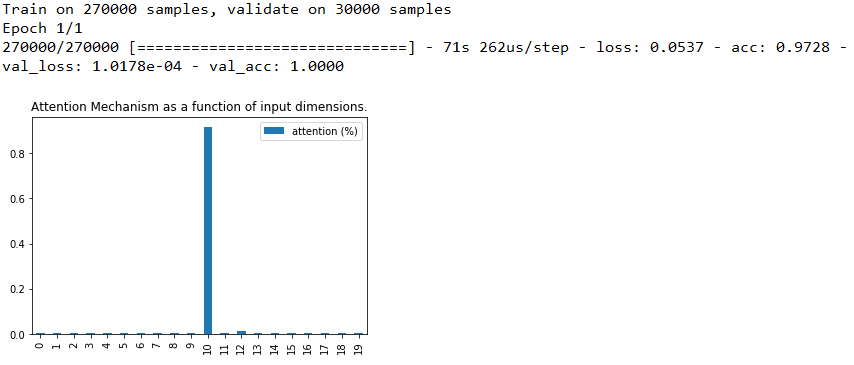
- 检验Attention是否真的捕捉到了关键特征,即被Attention分配的关键特征的权重是否更高。
实验设计
- 问题设计:同Dense+Attention一样,我们也设计成二分类问题,给定特征和标签进行训练。
- Attention聚焦测试:将特征的某一列与标签值设置成相同,这样就人为的造了一列关键特征,可视化Attention给每个特征分配的权重,观察关键特征的权重是否更高。
- Attention位置测试:在模型不同地方加上Attention会有不同的含义,那么是否每个地方Attention都能捕捉到关键信息呢?我们将变换Attention层的位置,分别放在整个分类模型的输入层(LSTM之前)和输出层(LSTM之后)进行比较。
数据集生成
数据集要为LSTM的输入做准备,而LSTM里面一个重要的参数就是time_steps,指的就是序列长度,而input_dim则指得是序列每一个单元的维度。
def get_data_recurrent(n, time_steps, input_dim, attention_column=10): """ Data generation. x is purely random except that it's first value equals the target y. In practice, the network should learn that the target = x[attention_column]. Therefore, most of its attention should be focused on the value addressed by attention_column. :param n: the number of samples to retrieve. :param time_steps: the number of time steps of your series. :param input_dim: the number of dimensions of each element in the series. :param attention_column: the column linked to the target. Everything else is purely random. :return: x: model inputs, y: model targets """ x = np.random.standard_normal(size=(n, time_steps, input_dim)) #标准正态分布随机特征值 y = np.random.randint(low=0, high=2, size=(n, 1)) #二分类,随机标签值 x[:, attention_column, :] = np.tile(y[:], (1, input_dim)) #将第attention_column个column的值置为标签值 return x, y 模型搭建
Attention层封装
上一章我们谈到Attention的实现可直接由一个激活函数为softmax的Dense层实现,Dense层的输出乘以Dense的输入即完成了Attention权重的分配。在这里的实现看上去比较复杂,但本质上仍是那两步操作,只是为了将问题更为泛化,把维度进行了扩展。
def attention_3d_block(inputs): # inputs.shape = (batch_size, time_steps, input_dim) input_dim = int(inputs.shape[2]) a = Permute((2, 1))(inputs) a = Reshape((input_dim, TIME_STEPS))(a) # this line is not useful. It's just to know which dimension is what. a = Dense(TIME_STEPS, activation='softmax')(a) if SINGLE_ATTENTION_VECTOR: a = Lambda(lambda x: K.mean(x, axis=1), name='dim_reduction')(a) a = RepeatVector(input_dim)(a) a_probs = Permute((2, 1), name='attention_vec')(a) output_attention_mul = Multiply()([inputs, a_probs]) return output_attention_mul 这里涉及到多个Keras的层,我们一个一个来看看它的功能。
- Permute层:索引从1开始,根据给定的模式(dim)置换输入的维度。(2,1)即置换输入的第1和第2个维度,可以理解成转置。
- Reshape层:将输出调整为特定形状,INPUT_DIM = 2,TIME_STEPS = 20,就将其调整为了2行,20列。
- Lambda层:本函数用以对上一层的输出施以任何Theano/TensorFlow表达式。这里的“表达式”指得就是K.mean,其原型为keras.backend.mean(x, axis=None, keepdims=False),指张量在某一指定轴的均值。
- RepeatVector层:作用为将输入重复n次。
LSTM之前使用Attention
def model_attention_applied_before_lstm(): K.clear_session() #清除之前的模型,省得压满内存 inputs = Input(shape=(TIME_STEPS, INPUT_DIM,)) attention_mul = attention_3d_block(inputs) lstm_units = 32 attention_mul = LSTM(lstm_units, return_sequences=False)(attention_mul) output = Dense(1, activation='sigmoid')(attention_mul) model = Model(input=[inputs], output=output) return model LSTM之后使用Attention
def model_attention_applied_after_lstm(): K.clear_session() #清除之前的模型,省得压满内存 inputs = Input(shape=(TIME_STEPS, INPUT_DIM,)) lstm_units = 32 lstm_out = LSTM(lstm_units, return_sequences=True)(inputs) attention_mul = attention_3d_block(lstm_out) attention_mul = Flatten()(attention_mul) output = Dense(1, activation='sigmoid')(attention_mul) model = Model(input=[inputs], output=output) return model 结果展示
注意权重共享+LSTM之前使用注意力
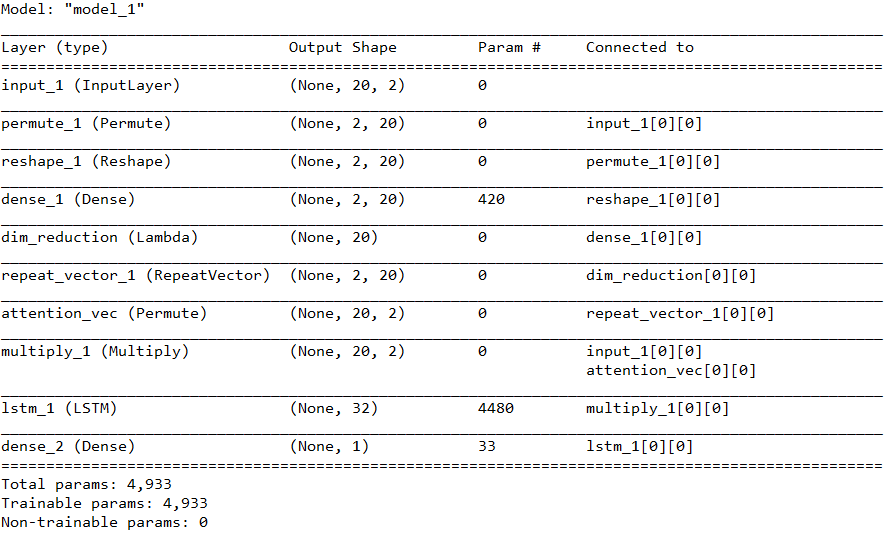

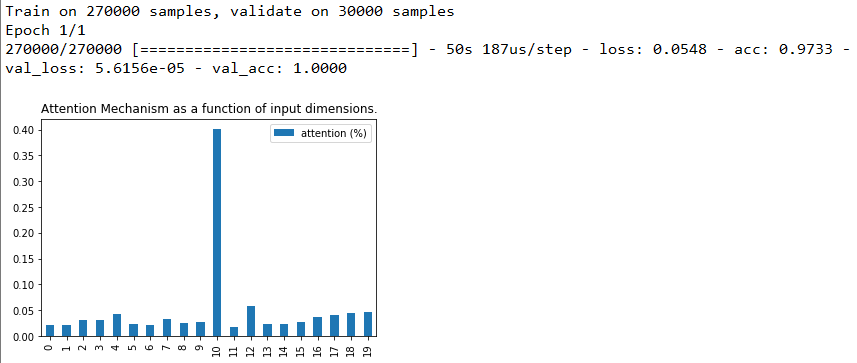
注意权重共享+LSTM之后使用注意力
注意权重不共享+LSTM之前使用注意力
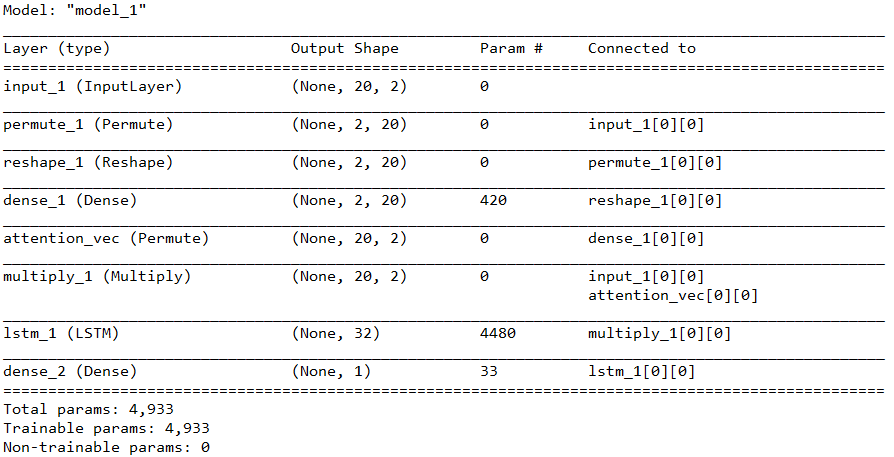
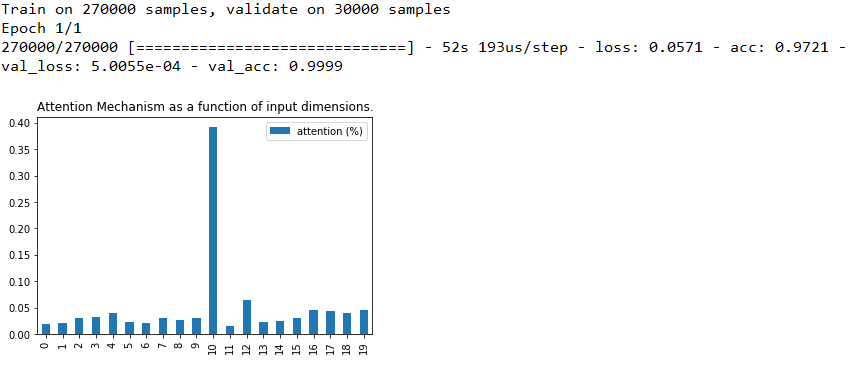
注意权重不共享+LSTM之后使用注意力

结果总结
完整代码(1个文件)
import keras.backend as K from keras.layers import Multiply from keras.layers.core import * from keras.layers.recurrent import LSTM from keras.models import * import matplotlib.pyplot as plt import pandas as pd import numpy as np def get_data_recurrent(n, time_steps, input_dim, attention_column=10): """ Data generation. x is purely random except that it's first value equals the target y. In practice, the network should learn that the target = x[attention_column]. Therefore, most of its attention should be focused on the value addressed by attention_column. :param n: the number of samples to retrieve. :param time_steps: the number of time steps of your series. :param input_dim: the number of dimensions of each element in the series. :param attention_column: the column linked to the target. Everything else is purely random. :return: x: model inputs, y: model targets """ x = np.random.standard_normal(size=(n, time_steps, input_dim)) #标准正态分布随机特征值 y = np.random.randint(low=0, high=2, size=(n, 1)) #二分类,随机标签值 x[:, attention_column, :] = np.tile(y[:], (1, input_dim)) #将第attention_column个column的值置为标签值 return x, y def get_activations(model, inputs, print_shape_only=False, layer_name=None): # Documentation is available online on Github at the address below. # From: https://github.com/philipperemy/keras-visualize-activations # print('----- activations -----') activations = [] inp = model.input if layer_name is None: outputs = [layer.output for layer in model.layers] else: outputs = [layer.output for layer in model.layers if layer.name == layer_name] # all layer outputs funcs = [K.function([inp] + [K.learning_phase()], [out]) for out in outputs] # evaluation functions layer_outputs = [func([inputs, 1.])[0] for func in funcs] for layer_activations in layer_outputs: activations.append(layer_activations) # if print_shape_only: # print(layer_activations.shape) # else: # print(layer_activations) return activations def attention_3d_block(inputs): # inputs.shape = (batch_size, time_steps, input_dim) input_dim = int(inputs.shape[2]) a = Permute((2, 1))(inputs) a = Reshape((input_dim, TIME_STEPS))(a) # this line is not useful. It's just to know which dimension is what. a = Dense(TIME_STEPS, activation='softmax')(a) if SINGLE_ATTENTION_VECTOR: a = Lambda(lambda x: K.mean(x, axis=1), name='dim_reduction')(a) a = RepeatVector(input_dim)(a) a_probs = Permute((2, 1), name='attention_vec')(a) output_attention_mul = Multiply()([inputs, a_probs]) return output_attention_mul def model_attention_applied_after_lstm(): K.clear_session() #清除之前的模型,省得压满内存 inputs = Input(shape=(TIME_STEPS, INPUT_DIM,)) lstm_units = 32 lstm_out = LSTM(lstm_units, return_sequences=True)(inputs) attention_mul = attention_3d_block(lstm_out) attention_mul = Flatten()(attention_mul) output = Dense(1, activation='sigmoid')(attention_mul) model = Model(input=[inputs], output=output) return model def model_attention_applied_before_lstm(): K.clear_session() #清除之前的模型,省得压满内存 inputs = Input(shape=(TIME_STEPS, INPUT_DIM,)) attention_mul = attention_3d_block(inputs) lstm_units = 32 attention_mul = LSTM(lstm_units, return_sequences=False)(attention_mul) output = Dense(1, activation='sigmoid')(attention_mul) model = Model(input=[inputs], output=output) return model SINGLE_ATTENTION_VECTOR = False APPLY_ATTENTION_BEFORE_LSTM = True INPUT_DIM = 2 TIME_STEPS = 20 if __name__ == '__main__': np.random.seed(1337) # for reproducibility # if True, the attention vector is shared across the input_dimensions where the attention is applied. N = # N = 300 -> too few = no training inputs_1, outputs = get_data_recurrent(N, TIME_STEPS, INPUT_DIM) # for i in range(0,3): # print(inputs_1[i]) # print(outputs[i]) if APPLY_ATTENTION_BEFORE_LSTM: m = model_attention_applied_before_lstm() else: m = model_attention_applied_after_lstm() m.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) m.summary() m.fit([inputs_1], outputs, epochs=1, batch_size=64, validation_split=0.1) attention_vectors = [] for i in range(300): testing_inputs_1, testing_outputs = get_data_recurrent(1, TIME_STEPS, INPUT_DIM) attention_vector = np.mean(get_activations(m, testing_inputs_1, print_shape_only=True, layer_name='attention_vec')[0], axis=2).squeeze() # print('attention =', attention_vector) assert (np.sum(attention_vector) - 1.0) < 1e-5 attention_vectors.append(attention_vector) attention_vector_final = np.mean(np.array(attention_vectors), axis=0) # plot part. pd.DataFrame(attention_vector_final, columns=['attention (%)']).plot(kind='bar', title='Attention Mechanism as ' 'a function of input' ' dimensions.') plt.show() 版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/205909.html原文链接:https://javaforall.net


