
文章目录
简介
Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库,Requests它会比urllib更加方便,可以节约我们大量的工作。
安装
pip快速安装pip install requests
使用
先上一串代码
import requests response = requests.get("https://www.baidu.com") print(type(response)) print(response.status_code) print(type(response.text)) #获得响应头内容 print(response.headers) print(response.headers['content-type']) #还可以用这种方式获取请求头内容 print(response.request.headers) response.enconding = "utf-8' print(response.text) print(response.cookies) print(response.content) print(response.content.decode("utf-8")) response.text返回的是Unicode格式,通常需要转换为utf-8格式,否则就是乱码。response.content是二进制模式,可以下载视频之类的,如果想看的话需要decode成utf-8格式。
不管是通过response.content.decode(“utf-8)的方式还是通过response.encoding=”utf-8″的方式都可以避免乱码的问题发生
一大推请求方式
import requests requests.post("http://httpbin.org/post") requests.put("http://httpbin.org/put") requests.delete("http://httpbin.org/delete") requests.head("http://httpbin.org/get") requests.options("http://httpbin.org/get") 基本GET
import requests url = 'https://www.baidu.com/' response = requests.get(url) print(response.text) 带参数的GET请求
如果想查询http://httpbin.org/get页面的具体参数,需要在url里面加上,例如我想看有没有Host=httpbin.org这条数据,url形式应该是http://httpbin.org/get?Host=httpbin.org
下面提交的数据是往这个地址传送data里面的数据。
import requests url = 'http://httpbin.org/get' data = { 'name':'zhangsan', 'age':'25' } response = requests.get(url,params=data) print(response.url) print(response.text) Json数据
从下面的数据中我们可以得出,如果结果:
1、requests中response.json()方法等同于json.loads(response.text)方法
import requests import json response = requests.get("http://httpbin.org/get") print(type(response.text)) print(response.json()) print(json.loads(response.text)) print(type(response.json()) print(response.json()['data']) 获取二进制数据
在上面提到了response.content,这样获取的数据是二进制数据,同样的这个方法也可以用于下载图片以及视频资源
添加header
首先说,为什么要加header(头部信息)呢?例如下面,我们试图访问知乎的登录页面(当然大家都你要是不登录知乎,就看不到里面的内容),我们试试不加header信息会报什么错。
import requests url = 'https://www.zhihu.com/' response = requests.get(url) response.encoding = "utf-8" print(response.text) 结果:
提示发生内部服务器错误(也就说你连知乎登录页面的html都下载不下来)。
500 Server Error
An internal server error occured. import requests url = 'https://www.zhihu.com/' headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36' } response = requests.get(url,headers=headers) print(response.text) 基本post请求:
通过post把数据提交到url地址,等同于一字典的形式提交form表单里面的数据
import requests url = 'http://httpbin.org/post' data = { 'name':'jack', 'age':'23' } response = requests.post(url,data=data) print(response.text) 结果:
{ "args": {}, "data": "", "files": {}, "form": { "age": "23", "name": "jack" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Connection": "close", "Content-Length": "16", "Content-Type": "application/x-www-form-urlencoded", "Host": "httpbin.org", "User-Agent": "python-requests/2.13.0" }, "json": null, "origin": "118.144.137.95", "url": "http://httpbin.org/post" } 响应:
import requests #allow_redirects=False#设置这个属性为False则是不允许重定向,反之可以重定向 response = requests.get("http://www.baidu.com",allow_redirects=False) #打印请求页面的状态(状态码) print(type(response.status_code),response.status_code) #打印请求网址的headers所有信息 print(type(response.headers),response.headers) #打印请求网址的cookies信息 print(type(response.cookies),response.cookies) #打印请求网址的地址 print(type(response.url),response.url) #打印请求的历史记录(以列表的形式显示) print(type(response.history),response.history) 
内置的状态码:
100: ('continue',), 101: ('switching_protocols',), 102: ('processing',), 103: ('checkpoint',), 122: ('uri_too_long', 'request_uri_too_long'), 200: ('ok', 'okay', 'all_ok', 'all_okay', 'all_good', '\\o/', '✓'), 201: ('created',), 202: ('accepted',), 203: ('non_authoritative_info', 'non_authoritative_information'), 204: ('no_content',), 205: ('reset_content', 'reset'), 206: ('partial_content', 'partial'), 207: ('multi_status', 'multiple_status', 'multi_stati', 'multiple_stati'), 208: ('already_reported',), 226: ('im_used',), # Redirection. 300: ('multiple_choices',), 301: ('moved_permanently', 'moved', '\\o-'), 302: ('found',), 303: ('see_other', 'other'), 304: ('not_modified',), 305: ('use_proxy',), 306: ('switch_proxy',), 307: ('temporary_redirect', 'temporary_moved', 'temporary'), 308: ('permanent_redirect', 'resume_incomplete', 'resume',), # These 2 to be removed in 3.0 # Client Error. 400: ('bad_request', 'bad'), 401: ('unauthorized',), 402: ('payment_required', 'payment'), 403: ('forbidden',), 404: ('not_found', '-o-'), 405: ('method_not_allowed', 'not_allowed'), 406: ('not_acceptable',), 407: ('proxy_authentication_required', 'proxy_auth', 'proxy_authentication'), 408: ('request_timeout', 'timeout'), 409: ('conflict',), 410: ('gone',), 411: ('length_required',), 412: ('precondition_failed', 'precondition'), 413: ('request_entity_too_large',), 414: ('request_uri_too_large',), 415: ('unsupported_media_type', 'unsupported_media', 'media_type'), 416: ('requested_range_not_satisfiable', 'requested_range', 'range_not_satisfiable'), 417: ('expectation_failed',), 418: ('im_a_teapot', 'teapot', 'i_am_a_teapot'), 421: ('misdirected_request',), 422: ('unprocessable_entity', 'unprocessable'), 423: ('locked',), 424: ('failed_dependency', 'dependency'), 425: ('unordered_collection', 'unordered'), 426: ('upgrade_required', 'upgrade'), 428: ('precondition_required', 'precondition'), 429: ('too_many_requests', 'too_many'), 431: ('header_fields_too_large', 'fields_too_large'), 444: ('no_response', 'none'), 449: ('retry_with', 'retry'), 450: ('blocked_by_windows_parental_controls', 'parental_controls'), 451: ('unavailable_for_legal_reasons', 'legal_reasons'), 499: ('client_closed_request',), # Server Error. 500: ('internal_server_error', 'server_error', '/o\\', '✗'), 501: ('not_implemented',), 502: ('bad_gateway',), 503: ('service_unavailable', 'unavailable'), 504: ('gateway_timeout',), 505: ('http_version_not_supported', 'http_version'), 506: ('variant_also_negotiates',), 507: ('insufficient_storage',), 509: ('bandwidth_limit_exceeded', 'bandwidth'), 510: ('not_extended',), 511: ('network_authentication_required', 'network_auth', 'network_authentication'), import requests
response = requests.get('http://www.jianshu.com/404.html')
# 使用request内置的字母判断状态码
#如果response返回的状态码是非正常的就返回404错误
if response.status_code != requests.codes.ok:
print('404')
#如果页面返回的状态码是200,就打印下面的状态
response = requests.get('http://www.jianshu.com')
if response.status_code == 200:
print('200')
request的高级操作
文件上传
import requests url = "http://httpbin.org/post" files= {"files":open("test.jpg","rb")} response = requests.post(url,files=files) print(response.text) 获取cookie
import requests response = requests.get('https://www.baidu.com') print(response.cookies) for key,value in response.cookies.items(): print(key,'==',value) 会话维持
cookie的一个作用就是可以用于模拟登陆,做会话维持
import requests session = requests.session() session.get('http://httpbin.org/cookies/set/number/12456') response = session.get('http://httpbin.org/cookies') print(response.text) cookie和session区别
- cookie数据存放在客户的浏览器上,session数据放在服务器上
- cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗
- session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能
- 单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie
证书验证
1、无证书访问
import requests response = requests.get('https://www.12306.cn') # 在请求https时,request会进行证书的验证,如果验证失败则会抛出异常 print(response.status_code) 关闭证书验证
import requests # 关闭验证,但是仍然会报出证书警告 response = requests.get('https://www.12306.cn',verify=False) print(response.status_code) 为了避免这种情况的发生可以通过verify=False,但是这样是可以访问到页面结果
消除验证证书的警报
from requests.packages import urllib3 import requests urllib3.disable_warnings() response = requests.get('https://www.12306.cn',verify=False) print(response.status_code) - 其它操作
#把cookie对象转化为字典 requests.utils.dict_from_cookiejar #把字典转化为cookie对象 requests.utils.cookiejar_from_dict #url解码 requests.utils.unquote() #url编码 requests.utils.quote() 手动设置证书
import requests response = requests.get('https://www.12306.cn', cert=('/path/server.crt', '/path/key')) print(response.status_code) 代理设置
代理的基本原理
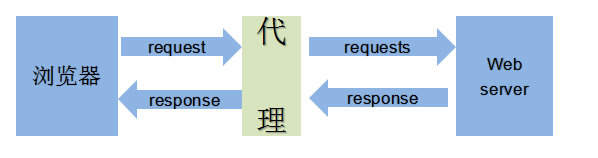
正向代理与反向代理
正向代理:浏览器明确知道要访问的是什么服务器,只不过目前无法达到,需要通过代理来帮助完成这个请求操作。
反向代理:浏览器不知道任何关于要请求的服务器的信息,需要通过Nginx请求。

设置普通代理
import requests proxies = { "http": "http://127.0.0.1:9743", "https": "https://127.0.0.1:9743", } response = requests.get("https://www.taobao.com", proxies=proxies) print(response.status_code) 2、设置用户名和密码代理
- 设置socks代理
安装socks模块 pip3 install 'requests[socks]'
import requests proxies = { 'http': 'socks5://127.0.0.1:9742', 'https': 'socks5://127.0.0.1:9742' } response = requests.get("https://www.taobao.com", proxies=proxies) print(response.status_code) 超时设置
通过timeout参数可以设置超时的时间
import requests from requests.exceptions import ReadTimeout try: # 设置必须在500ms内收到响应,不然或抛出ReadTimeout异常 response = requests.get("http://httpbin.org/get", timeout=0.5) print(response.status_code) except ReadTimeout: print('Timeout') 认证设置
如果碰到需要认证的网站可以通过requests.auth模块实现
import requests from requests.auth import HTTPBasicAuth
#方法一 r = requests.get('http://120.27.34.24:9001', auth=HTTPBasicAuth('user', '123'))
#方法二
r = requests.get('http://120.27.34.24:9001', auth=('user', '123')) print(r.status_code)
异常处理
关于reqeusts的异常在这里可以看到详细内容: http://www.python-requests.org/en/master/api/#exceptions
所有的异常都是在requests.excepitons中
这里列举了一些常用的异常继承关系,详细的可以看:http://cn.python-requests.org/zh_CN/latest/_modules/requests/exceptions.html#RequestException
通过下面的例子进行简单的演示
import requests from requests.exceptions import ReadTimeout, ConnectionError, RequestException try: response = requests.get("http://httpbin.org/get", timeout = 0.5) print(response.status_code) except ReadTimeout: print('Timeout') except ConnectionError: print('Connection error') except RequestException: print('Error') 首先被捕捉的异常是timeout,当把网络断掉的haul就会捕捉到ConnectionError,如果前面异常都没有捕捉到,最后也可以通过RequestExctption捕捉到
python中Requests的重试机制
requests原生支持
import requests from requests.adapters import HTTPAdapter s = requests.Session() # 重试次数为3 s.mount('http://', HTTPAdapter(max_retries=3)) s.mount('https://', HTTPAdapter(max_retries=3)) # 超时时间为5s s.get('http://example.com', timeout=5) 附加
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/205919.html原文链接:https://javaforall.net


