
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
因为本人是自学深度学习的,有什么说的不对的地方望大神指出
指数加权平均算法的原理
TensorFlow中的滑动平均模型使用的是滑动平均(Moving Average)算法,又称为指数加权移动平均算法(exponenentially weighted average),这也是ExponentialMovingAverage()函数的名称由来。
先来看一个简单的例子,这个例子来自吴恩达老师的DeepLearning课程,个人强烈推荐初学者都看一下。
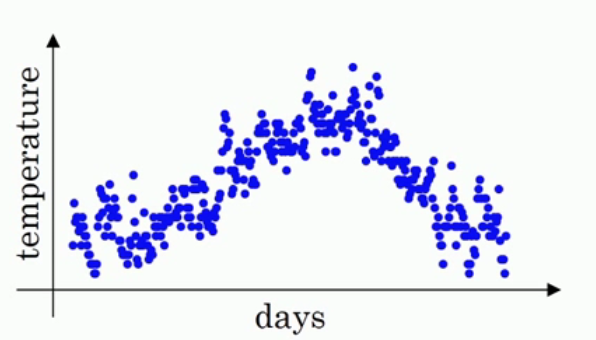
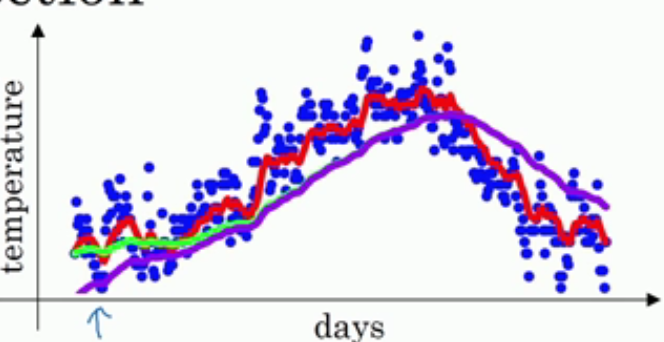
开始例子。首先这是一年365天的温度散点图,以天数为横坐标,温度为纵坐标,你可以看见各个小点分布在图上,有一定的曲线趋势,但是并不明显

接着,如果我们要看出这个温度的变化趋势,很明显需要做一点处理,也即是我们的主题,用滑动平均算法处理。
首先给定一个值v0,然后我们定义每一天的温度是a1,a2,a3·····
接着,我们计算出v1,v2,v3····来代替每一天的温度,也就是上面的a1,a2,a3
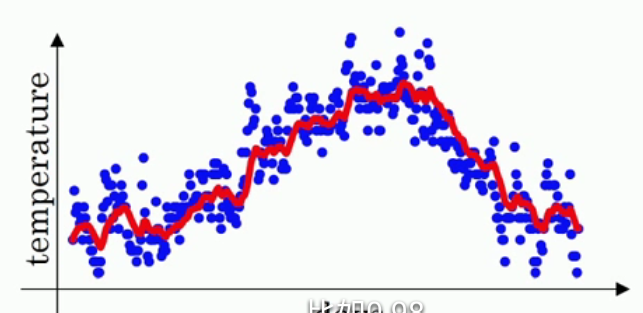
计算方法是:v1 = v0 * 0.9 + a1 (1-0.9),v2= v1 0.9 + a2 (1-0.9),v3= v2 0.9 + a3 (1-0.9)···,也就是说,每一天的温度改变为前一天的v值 0.9 + 当天的温度 * 0.1,vt = v(t-1) * 0.9 + at * 0.1,把所有的v计算完之后画图,红线就是v的曲线:
v值就是指数加权平均数,整个过程就是指数加权平均算法,它很好的把一年的温度曲线给拟合了出来。把0.9抽象为β,总结为vt = v(t-1) * β + at * (1-β)。
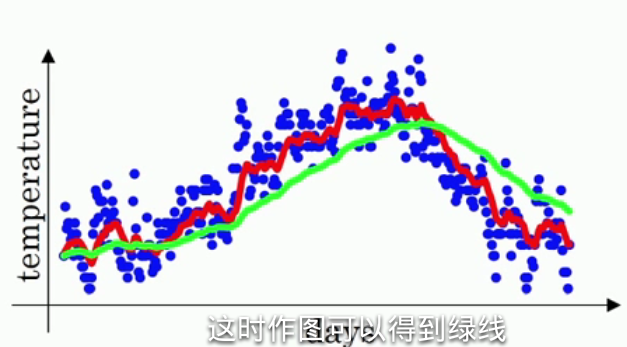
β这个值的意义是什么?实际上vt ≈ 1/(1 – β) 天的平均温度,例如:假设β等于0.9,1/(1 – β) 就等于10,也就是vt等于前十天的平均温度,这个说可能不太看得出来;假设把β值调大道接近1,例如,将β等于0.98,1/(1-β)=50,按照刚刚的说法也就是前50天的平均温度,然后求出v值画出曲线,如图所示:
绿线就是β等于0.98时候的曲线,可以明显看到绿线比红线的变化更迟,红线达到某一温度,绿线要过一阵子才能达到相同温度。因为绿线是前50天的平均温度,变化就会更加缓慢,而红线是最近十天的平均温度,只要最近十天的温度都是上升,红线很快就能跟着变化。所以直观的理解就是,vt是前1/(1-β)天的平均温度。
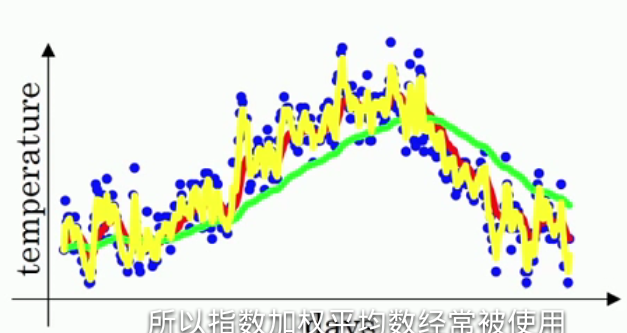
再看看另一个极端情况:β等于0.5,意味着vt≈最近两天的平均温度,曲线如下黄线:
和原本的温度很相似,但曲线的波动幅度也相当大!
然后说一下这个滑动平均模型和深度学习有什么关系:通常来说,我们的数据也会像上面的温度一样,具有不同的值,如果使用滑动平均模型,就可以使得整体数据变得更加平滑——这意味着数据的噪音会更少,而且不会出现异常值。但是同时β太大也会使得数据的曲线右移,和数据不拟合。需要不断尝试出一个β值,既可以拟合数据集,又可以减少噪音。
滑动平均模型在深度学习中还有另一个优点:它只占用极少的内存
当你在模型中计算最近十天(有些情况下远大于十天)的平均值的时候,你需要在内存中加载这十天的数据然后进行计算,但是指数加权平均值约等于最近十天的平均值,而且根据vt = v(t-1) * β + at * (1-β),你只需要提供at这一天的数据,再加上v(t-1)的值和β值,相比起十天的数据这是相当小的数据量,同时占用更少的内存。
偏差修正
指数加权平均值通常都需要偏差修正,TensorFlow中提供的ExponentialMovingAverage()函数也带有偏差修正。
首先看一下为什么会出现偏差,再来说怎么修正。当β等于0.98的时候,还是用回上面的温度例子,曲线实际上不是像绿线一样,而是像紫线:
你可以注意到在紫线刚刚开始的时候,曲线的值相当的低,这是因为在一开始的时候并没有50天(1/(1-β)为50)的数据,而是只有寥寥几天的数据,相当于少加了几十天的数据,所以vt的值很小,这和实际情况的差距是很大的,也就是出现的偏差。
而在TensorFlow中的ExponentialMovingAverage()采取的偏差修正方法是:使用num_updates来动态设置β的大小
在数据迭代的前期,数据量比较少的时候,(1+num_updates)/(10+num_updates)的值比较小,使用这个值作为β来进行vt的计算,所以在迭代前期就会像上面的红线一样,和原数据更加接近。举个例子,当天数是第五天,β为0.98,那么(1+num_updates)/(10+num_updates) = 6/15 = 0.4,相当于最近1.6天的平均温度,而不是β=0.98时候的50天,这样子就做到了偏差修正。
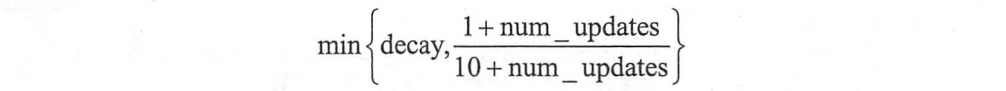
滑动平均模型的代码实现
看到这里你应该大概了解了滑动平均模型和偏差修正到底是怎么回事了,接下来把这个想法对应到TensorFlow的代码中。
首先明确一点,TensorFlow中的ExponentialMovingAverage()是针对权重weight和偏差bias的,而不是针对训练集的。如果你现在训练集中实现这个效果,需要自己设计代码。
为什么要对w和b使用滑动平均模型呢?因为在神经网络中,
更新的参数时候不能太大也不能太小,更新的参数跟你之前的参数有联系,不能发生突变。一旦训练的时候遇到个“疯狂”的参数,有了滑动平均模型,疯狂的参数就会被抑制下来,回到正常的队伍里。这种对于突变参数的抑制作用,用专业术语讲叫鲁棒性,鲁棒性就是对突变的抵抗能力,鲁棒性越好,这个模型对恶性参数的提抗能力就越强。
在TensorFlow中,ExponentialMovingAverage()可以传入两个参数:衰减率(decay)和数据的迭代次数(step),这里的decay和step分别对应我们的β和num_updates,所以在实现滑动平均模型的时候,步骤如下:
1、定义训练轮数step
2、然后定义滑动平均的类
3、给这个类指定需要用到滑动平均模型的变量(w和b)
4、执行操作,把变量变为指数加权平均值
# 1、定义训练的轮数,需要用trainable=False参数指定不训练这个变量,
# 避免这个变量被计算滑动平均值
global_step = tf.Variable(0, trainable=False)
# 2、给定滑动衰减率和训练轮数,初始化滑动平均类
# 定训练轮数的变量可以加快训练前期的迭代速度
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,
global_step)
# 3、用tf.trainable_variable()获取所有可以训练的变量列表,也就是所有的w和b
# 全部指定为使用滑动平均模型
variables_averages_op = variable_averages.apply(tf.trainable_variables())
# 反向传播更新参数之后,再更新每一个参数的滑动平均值,用下面的代码可以一次完成这两个操作
with tf.control_dependencies([train_step, variables_averages_op]):
train_op = tf.no_op(name="train")设置完使用滑动平均模型之后,只需要在每次使用反向传播的时候改为使用run.(train_op)就可以正常执行了。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/206863.html原文链接:https://javaforall.net


