
文章目录
很多论文都会用到K折交叉验证,但是我以前实验一直没有做这个步骤,最近整理了一下关于这个方面的资料,其实就是把看到的文字资料整理一下,有些文字自己进行了突出和调整,感谢所有博主,最后是我的matlab版的分层交叉验证,通过这一段的学习,最大的感受就是 python 好,python好,python 好,真是令人忧伤啊。。。
分层K折交叉验证是K折交叉验证的一个变种, 适用于不平衡的数据集,所以先介绍K折交叉验证,之后再介绍分层K折交叉验证。
K折交叉验证有什么用?
用法1:常用的精度测试方法主要是交叉验证,例如10折交叉验证(10-fold cross validation,CV),将数据集分成平均分成互斥的十份,轮流将其中9份做训练1份做验证,10次的结果的均值作为对算法精度的估计,一般还需要进行多次10折交叉验证求均值,例如:10次10折交叉验证,以求更精确一点。
来源——参考博客1: https://blog.csdn.net/Dream_angel_Z/article/details/47110077?utm_medium=distribute.pc_relevant.none-task-blog-OPENSEARCH-6.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-OPENSEARCH-6.channel_param
用法2:一般情况将K折交叉验证用于模型调优,找到使得模型泛化性能最优的超参值。找到后,在全部训练集上重新训练模型,并使用独立测试集对模型性能做出最终评价。
来源——参考博客2:https://blog.csdn.net/ChenVast/article/details/79257097?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522160249987519725222451761%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=160249987519725222451761&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogfirst_rank_v2~rank_blog_v1-1-79257097.pc_v2_rank_blog_v1&utm_term=k%E6%8A%98&spm=1018.2118.3001.4187
关于这两种用法,我目前看到的论文中,几乎都是第1种,我也是为了精度测试方法来学习k折交叉验证的,第2种用法没怎么看到过,所以记录一下啊,仅供参考。
如何实现K折交叉验证?
K折交叉验证的要点:(文字版)
1:数据集划分为K个相同大小的互斥子集。
2:每次用K-1个集合训练,剩下的1个做测试集,得到结果。
3:循环K次,得到K个结果,至此1次完整的K折交叉验证结束
来源——参考博客3(有改动):https://baijiahao.baidu.com/s?id=1677821446173455536&wfr=spider&for=pc
这个是博主:桔子的算法之路写的,,但是我觉得他原文比较像是分层K折交叉验证,所以我就改了一点点
如何实现K折交叉验证(图片版)
图片比文字直观,下面的图很清楚地告诉我们,大小相同、互斥、以及具体的过程,图片来源,依旧是参考博客2:https://blog.csdn.net/ChenVast/article/details/79257097?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522160249987519725222451761%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=160249987519725222451761&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogfirst_rank_v2~rank_blog_v1-1-79257097.pc_v2_rank_blog_v1&utm_term=k%E6%8A%98&spm=1018.2118.3001.4187



如何实现K折交叉验证(matlab版)
这个之前有特地整理过了,代码来自博主:野狗汪汪汪,这里再贴一下mattlab代码,博客地址:https://blog.csdn.net/weixin_/article/details/
data=double(xtrain'); label=double(ytrain'); %要求数据集每一行代表一个样本 ;label每行为标签 [M,N]=size(data); % M:总样本量; N:一个样本的元素总数 indices=crossvalind('Kfold',data(1:M,N),5); %进行随机分包 for k=1:5 %交叉验证k=10,10个包轮流作为测试集 test = (indices == k); %获得test集元素在数据集中对应的单元编号 train = ~test; %train集元素的编号为非test元素的编号 train_data=data(train,:);%从数据集中划分出train样本的数据 train_label=label(train,:); test_data=data(test,:); %test样本集 test_label=label(test,:); end 这个代码的具体原理可以参考这个博客,来源——参考博客7:https://blog.csdn.net/IT_flying625/article/details/
至此,k折交叉验证的内容全部介绍完毕,下面是分层交叉验证的内容
为啥我们需要分层K折交叉验证?
K折交叉验证和分层k折交叉验证的区别,字面上看就是多了个分层,那么为啥要分层呢,前面有说到,分层k折交叉验证是适用于不平衡的数据集的,依然是参考博客2写道:
K折交叉验证改进成的分层K折交叉验证:
获得偏差和方差都低的评估结果,特别是类别比例相差较大时。
那么为什么类别比例相差比较大的时候(就是数据集不平衡时),不分层的k折交叉验证得到的结果不准确呢?请参考这个回答http://sofasofa.io/forum_main_post.php?postid=1000505&:
对于非平衡分类,stratified CV(这里指分层的k折交叉验证)的优点就更加明显了。如果二元分类中分类A只占有0.01%,分类B占有99.99%,当你使用常规的交叉验证的时候,可能你的训练集里甚至都没有足够的A来训练,或者测试集里A的数量极少,严重影响了验证结果的可靠性。
怎么理解这个影响可靠性,换句话来说,假设整个数据集100张图,进行5折交叉验证,那么一折就有20张图,假设两个类A和B比例是1:9,运气非常差的情况下,某一折的过程中,所有的A(10个样本)全部分为测试集,训练集中一张都没有A,那么相当于老师讲课没有说这个类型题(训练),考试(测试)还考到了,考的差(评估结果差)就说你水平(这个模型效果不好),这个说法一看就知道不对劲。而越是不平衡的数据集,越有可能出现这种情况,所以我们要通过分层,来让每一折的——不管是训练集还是测试集——每个类的比例都尽量和原来的数据集保持一样,这就类似于,老师平时讲的多的东西,考试占的分也多,然后我们考很多次试,取评分,这个才能比较客观地体现出你的能力,如果是一个平衡的数据集,如果你某一次考试考的特别好或者特别差,这都不是你的真实水平,K折交叉验证通过让你考很多次,取平均分可以避免这种情况,但是不平衡的数据集,K折交叉就好像你参加的考试本身就有些问题,考很多次也不能体现你的真实水平,而分层K折交叉验证就可以解决这个问题。
如何实现分层k折交叉验证
如何实现分层k折交叉验证(文字版)
如何实现分层k折交叉验证(图片版)
这张图可以直观感受一下啥叫分层k折交叉验证,这是我找到的最好的一张图了,只看下面那个部分就好了,图片来源——参考博客4:https://blog.csdn.net/ssswill/article/details/
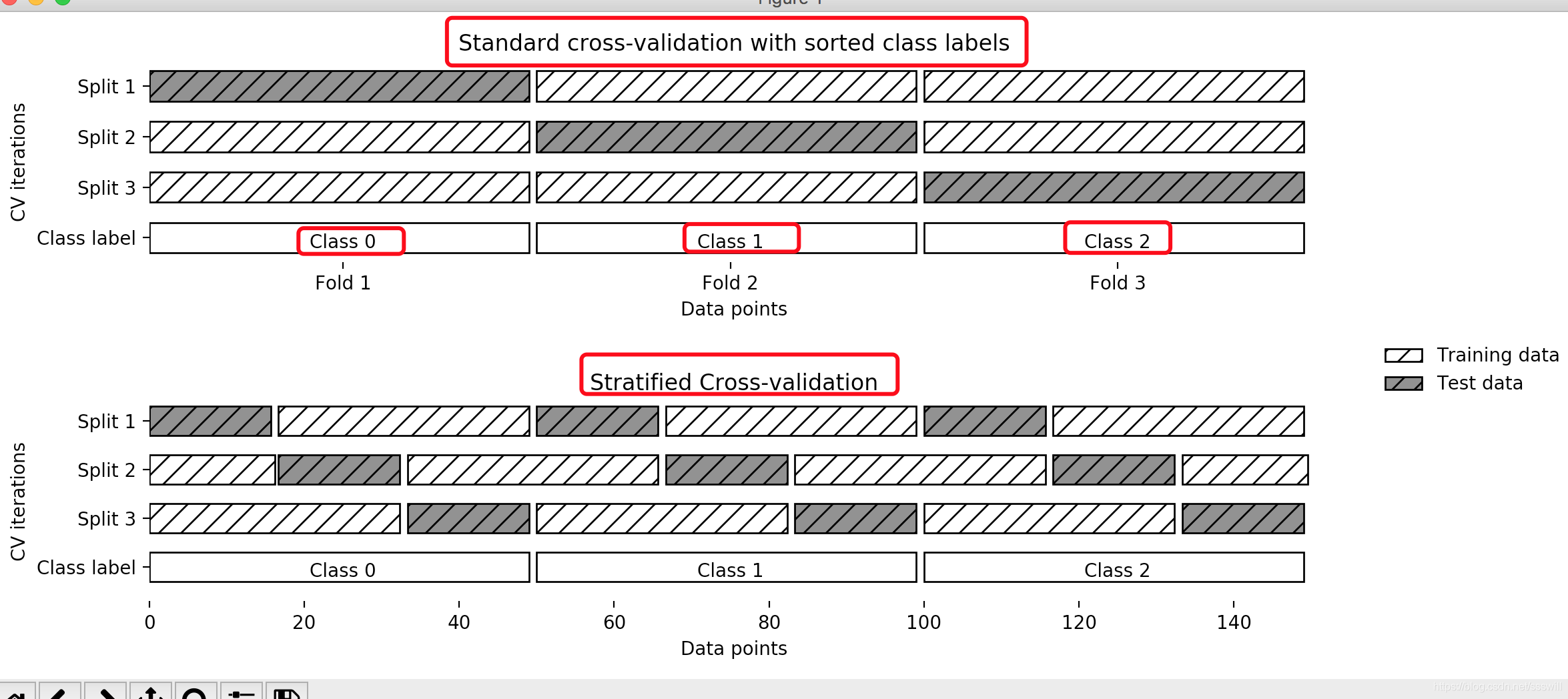
因此正如原博客所说的:分层保证了每个折中类别之间的比例与整个数据集中的比例相同。
如何实现分层K折交叉验证(matlab版)
下面这个是程序,我的是8分类,在k折交叉验证的基础上改的,原来的代码来源——参考博客6:https://blog.csdn.net/u010513327/article/details/80560750?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.channel_param
人家写得好工整啊,为啥我的就显得很乱呢…
程序中有一个num_in_class,我的是8分类问题,所以是这样一个东西,这个变量代表了每一类有多少个样本,前提是你的样本数据集要同一个类都放在一起,然后第1类,第2类,第3类这样一直排下去。

%需要先载入特征和标签,没有对应的mat文件的话会报错,所以要根据自己的情况改 clc clear all tic load features1%第一种特征 load features2%第2种特征 load Labels features=[features1,features2];%把两个矩阵横向拼起来起来,注意中间是逗号,不是分号 num_in_class=[713,1343,1165,728,1217,713,1378,795];%说明第一类有713张图片,第2类有1343张图片,以此类推,需要改成自己的数据。 classnums=length(num_in_class);%类别数为classnums,这一步是为了把每一类都取出来,注释掉的是手动的,下面是自动的,功能一样,我觉得我的自动的没有错...但是不敢打包票.... % features_lei1=features(1:713,:);%这个步骤不是自动化的,是自己把num_in_class的东西用excel累计求和,features矩阵第一行到第713行的所有数据数据是类别1 % features_lei2=features(713+1:2056,:);%features矩阵第713+1行到第2056行的所有数据数据是类别2,2026=713+1343 % features_lei3=features(2056+1:3221,:); % features_lei4=features(3221+1:3949,:); % features_lei5=features(3949+1:5166,:); % features_lei6=features(5166+1:5879,:); % features_lei7=features(5879+1:7257,:); % features_lei8=features(7257+1:8052,:); features_lei1=features(1:num_in_class(1),:);%这个步骤是自动化的,其实是确定上面的没问题后,改出来的 lei2_end=num_in_class(1)+num_in_class(2); features_lei2=features(num_in_class(1)+1:lei2_end,:); lei3_end=lei2_end+num_in_class(3); features_lei3=features(lei2_end+1:lei3_end,:); lei4_end=lei3_end+num_in_class(4); features_lei4=features(lei3_end+1:lei4_end,:); lei5_end=lei4_end+num_in_class(5); features_lei5=features(lei4_end+1:lei5_end,:); lei6_end=lei5_end+num_in_class(6); features_lei6=features(lei5_end+1:lei6_end,:); lei7_end=lei6_end+num_in_class(7); features_lei7=features(lei6_end+1:lei7_end,:); lei8_end=lei7_end+num_in_class(8); features_lei8=features(lei7_end+1:lei8_end,:); % Labels_lei1=Labels(1:713,:);%这个步骤不是自动化的,是自己把num_in_class的东西用excel累计求和 % Labels_lei2=Labels(713+1:2056,:); % Labels_lei3=Labels(2056+1:3221,:); % Labels_lei4=Labels(3221+1:3949,:); % Labels_lei5=Labels(3949+1:5166,:); % Labels_lei6=Labels(5166+1:5879,:); % Labels_lei7=Labels(5879+1:7257,:); % Labels_lei8=Labels(7257+1:8052,:); Labels_lei1=Labels(1:num_in_class(1),:);%这个步骤是自动化的,其实是确定上面的没问题后,改出来的 Labels_lei2=Labels(num_in_class(1)+1:lei2_end,:); Labels_lei3=Labels(lei2_end+1:lei3_end,:); Labels_lei4=Labels(lei3_end+1:lei4_end,:); Labels_lei5=Labels(lei4_end+1:lei5_end,:); Labels_lei6=Labels(lei5_end+1:lei6_end,:); Labels_lei7=Labels(lei6_end+1:lei7_end,:); Labels_lei8=Labels(lei7_end+1:lei8_end,:); %% k折交叉验证 %交叉验证 k =5;%预将数据分成5份 sum_accuracy_svm = 0; %% 类别1 [m,n] = size(features_lei1); %交叉验证,使用k折交叉验证 Kfold %indices为 m 行一列数据,表示每个训练样本属于k份数据的哪一份 indices_1 = crossvalind('Kfold',m,k); %% 类别2 [m,n] = size(features_lei2); %交叉验证,使用k折交叉验证 Kfold %indices为 m 行一列数据,表示每个训练样本属于k份数据的哪一份 indices_2 = crossvalind('Kfold',m,k); %% 类别3 [m,n] = size(features_lei3); %交叉验证,使用k折交叉验证 Kfold %indices为 m 行一列数据,表示每个训练样本属于k份数据的哪一份 indices_3 = crossvalind('Kfold',m,k); %% 类别4 [m,n] = size(features_lei4); %交叉验证,使用k折交叉验证 Kfold %indices为 m 行一列数据,表示每个训练样本属于k份数据的哪一份 indices_4 = crossvalind('Kfold',m,k); %% 类别5 [m,n] = size(features_lei5); %交叉验证,使用k折交叉验证 Kfold %indices为 m 行一列数据,表示每个训练样本属于k份数据的哪一份 indices_5 = crossvalind('Kfold',m,k); %% 类别6 [m,n] = size(features_lei6); %交叉验证,使用k折交叉验证 Kfold %indices为 m 行一列数据,表示每个训练样本属于k份数据的哪一份 indices_6 = crossvalind('Kfold',m,k); %% 类别7 [m,n] = size(features_lei7); %交叉验证,使用k折交叉验证 Kfold %indices为 m 行一列数据,表示每个训练样本属于k份数据的哪一份 indices_7 = crossvalind('Kfold',m,k); %% 类别8 [m,n] = size(features_lei8); %交叉验证,使用k折交叉验证 Kfold %indices为 m 行一列数据,表示每个训练样本属于k份数据的哪一份 indices_8 = crossvalind('Kfold',m,k); for i = 1:k % 针对第1类划分训练集和测试集 test_indic_1 = (indices_1 == i); train_indic_1 = ~test_indic_1; train_datas_1 = features_lei1(train_indic_1,:);%找出训练数据与标签 train_labels_1 = Labels_lei1(train_indic_1,:); test_datas_1 = features_lei1(test_indic_1,:);%找出测试数据与标签 test_labels_1 = Labels_lei1(test_indic_1,:); % 针对第2类划分训练集和测试集 test_indic_2 = (indices_2 == i); train_indic_2 = ~test_indic_2; train_datas_2 = features_lei2(train_indic_2,:);%找出训练数据与标签 train_labels_2 = Labels_lei2(train_indic_2,:); test_datas_2 = features_lei2(test_indic_2,:);%找出测试数据与标签 test_labels_2 = Labels_lei2(test_indic_2,:); % 针对第3类划分训练集和测试集 test_indic_3 = (indices_3 == i); train_indic_3 = ~test_indic_3; train_datas_3 = features_lei3(train_indic_3,:);%找出训练数据与标签 train_labels_3 = Labels_lei3(train_indic_3,:); test_datas_3 = features_lei3(test_indic_3,:);%找出测试数据与标签 test_labels_3 = Labels_lei3(test_indic_3,:); % 针对第4类划分训练集和测试集 test_indic_4 = (indices_4 == i); train_indic_4 = ~test_indic_4; train_datas_4 = features_lei4(train_indic_4,:);%找出训练数据与标签 train_labels_4 = Labels_lei4(train_indic_4,:); test_datas_4 = features_lei4(test_indic_4,:);%找出测试数据与标签 test_labels_4 = Labels_lei4(test_indic_4,:); % 针对第5类划分训练集和测试集 test_indic_5 = (indices_5 == i); train_indic_5 = ~test_indic_5; train_datas_5 = features_lei5(train_indic_5,:);%找出训练数据与标签 train_labels_5 = Labels_lei5(train_indic_5,:); test_datas_5 = features_lei5(test_indic_5,:);%找出测试数据与标签 test_labels_5 = Labels_lei5(test_indic_5,:); % 针对第6类划分训练集和测试集 test_indic_6 = (indices_6 == i); train_indic_6 = ~test_indic_6; train_datas_6 = features_lei6(train_indic_6,:);%找出训练数据与标签 train_labels_6 = Labels_lei6(train_indic_6,:); test_datas_6 = features_lei6(test_indic_6,:);%找出测试数据与标签 test_labels_6 = Labels_lei6(test_indic_6,:); % 针对第7类划分训练集和测试集 test_indic_7 = (indices_7 == i); train_indic_7 = ~test_indic_7; train_datas_7 = features_lei7(train_indic_7,:);%找出训练数据与标签 train_labels_7 = Labels_lei7(train_indic_7,:); test_datas_7 = features_lei7(test_indic_7,:);%找出测试数据与标签 test_labels_7 = Labels_lei7(test_indic_7,:); % 针对第8类划分训练集和测试集 test_indic_8 = (indices_8 == i); train_indic_8 = ~test_indic_8; train_datas_8 = features_lei8(train_indic_8,:);%找出训练数据与标签 train_labels_8 = Labels_lei8(train_indic_8,:); test_datas_8 = features_lei8(test_indic_8,:);%找出测试数据与标签 test_labels_8 = Labels_lei8(test_indic_8,:); % 合并 train_datas = [train_datas_1;train_datas_2;train_datas_3;train_datas_4;train_datas_5;train_datas_6;train_datas_7;train_datas_8]; train_labels =[train_labels_1;train_labels_2;train_labels_3;train_labels_4;train_labels_5;train_labels_6;train_labels_7;train_labels_8]; test_datas = [test_datas_1;test_datas_2;test_datas_3;test_datas_4;test_datas_5;test_datas_6;test_datas_7;test_datas_8]; test_labels =[test_labels_1;test_labels_2;test_labels_3;test_labels_4;test_labels_5;test_labels_6;test_labels_7;test_labels_8]; % 开始svm多分类训练,fitcsvm用于二分类,fitcecoc用于多分类, classifer = fitcecoc(train_datas,train_labels);%训练模型 predict_label = predict(classifer, test_datas);%测试 fprintf('第%d折\n',i) disp('分类正确率:'); accuracy_svm = length(find(predict_label == test_labels))/length(test_labels)%正确率 sum_accuracy_svm = sum_accuracy_svm + accuracy_svm; end mean_accuracy_svm = sum_accuracy_svm / k; disp('平均准确率:'); disp( mean_accuracy_svm); toc 再次感谢以上所有的博主们!!!
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/207232.html原文链接:https://javaforall.net


