
LDA(Latent Dirichlet Allocation)中文翻译为:潜在狄利克雷分布。LDA主题模型是一种文档生成模型,是一种非监督机器学习技术。它认为一篇文档是有多个主题的,而每个主题又对应着不同的词。一篇文档的构造过程,首先是以一定的概率选择某个主题,然后再在这个主题下以一定的概率选出某一个词,这样就生成了这篇文档的第一个词。不断重复这个过程,就生成了整篇文章(当然这里假定词与词之间是没有顺序的,即所有词无序的堆放在一个大袋子中,称之为词袋,这种方式可以使算法相对简化一些)。
LDA的使用是上述文档生成过程的逆过程,即根据一篇得到的文档,去寻找出这篇文档的主题,以及这些主题所对应的词。LDA是NLP领域一个非常重要的非监督算法。
1 LDA主题模型
假设我们有 M M M篇文档,对应第 d d d个文档中有有 N d N_d Nd个词。即输入为如下图:
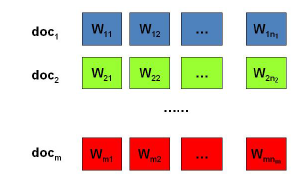

我们的目标是找到每一篇文档的主题分布和每一个主题中词的分布。
在LDA模型中,我们需要先假定一个主题数 K K K,这样所有的分布就都基于 K K K个主题展开。那么具体LDA模型是怎么样的呢?具体如下图:
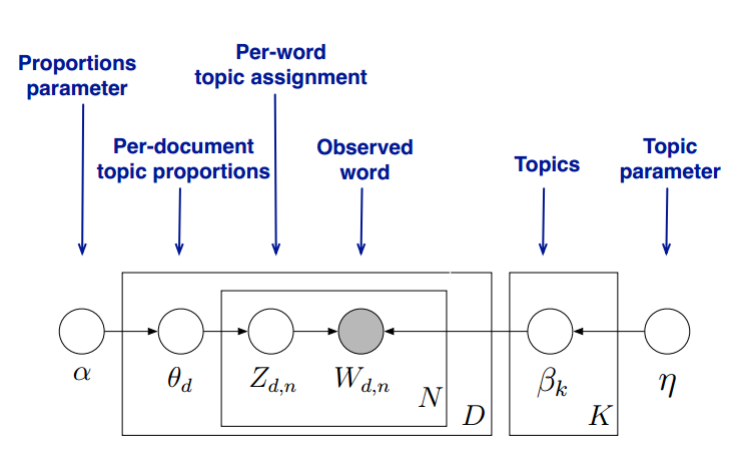
LDA假设文档主题的先验分布是Dirichlet分布,即对于任一文档 d d d, 其主题分布 θ d θ_d θd为:
θ d = D i r i c h l e t ( α ⃗ ) \theta_d = Dirichlet(\vec \alpha) θd=Dirichlet(α)
其中, α α α为分布的超参数,是一个 K K K维向量。
LDA假设主题中词的先验分布是Dirichlet分布,即对于任一主题 k k k, 其词分布 β k β_k βk为:
β k = D i r i c h l e t ( η ⃗ ) \beta_k= Dirichlet(\vec \eta) βk=Dirichlet(η)
其中, η η η为分布的超参数,是一个 V V V维向量。 V V V代表词汇表里所有词的个数。
对于数据中任意一篇文档 d d d中的第 n n n个词,我们可以从主题分布 θ d θ_d θd中得到它的主题编号 z d n z_{dn} zdn的分布为:
z d n = m u l t i ( θ d ) z_{dn} = multi(\theta_d) zdn=multi(θd)
而对于该主题编号,得到我们看到的词 w d n w_{dn} wdn的概率分布为:
w d n = m u l t i ( β z d n ) w_{dn} = multi(\beta_{z_{dn}}) wdn=multi(βzdn)
理解LDA主题模型的主要任务就是理解上面的这个模型。这个模型里,我们有 M M M个文档主题的Dirichlet分布,而对应的数据有 M M M个主题编号的多项分布,这样( α → θ d → z ⃗ d \alpha \to \theta_d \to \vec z_{d} α→θd→zd)就组成了Dirichlet-multi共轭,可以使用贝叶斯推断的方法得到基于Dirichlet分布的文档主题后验分布。
如果在第 d d d个文档中,第 k k k个主题的词的个数为: n d ( k ) n_d^{(k)} nd(k), 则对应的多项分布的计数可以表示为:
n ⃗ d = ( n d ( 1 ) , n d ( 2 ) , . . . n d ( K ) ) \vec n_d = (n_d^{(1)}, n_d^{(2)},…n_d^{(K)}) nd=(nd(1),nd(2),...nd(K))
利用Dirichlet-multi共轭,得到 θ d θ_d θd的后验分布为:
D i r i c h l e t ( θ d ∣ α ⃗ + n ⃗ d ) Dirichlet(\theta_d | \vec \alpha + \vec n_d) Dirichlet(θd∣α+nd)
同样的道理,对于主题与词的分布,我们有KK个主题与词的Dirichlet分布,而对应的数据有 K K K个主题编号的多项分布,这样( η → β k → w ⃗ ( k ) \eta \to \beta_k \to \vec w_{(k)} η→βk→w(k))就组成了Dirichlet-multi共轭,可以使用贝叶斯推断的方法得到基于Dirichlet分布的主题词的后验分布。
如果在第 k k k个主题中,第 v v v个词的个数为: n k ( v ) n_k^{(v)} nk(v), 则对应的多项分布的计数可以表示为
n ⃗ k = ( n k ( 1 ) , n k ( 2 ) , . . . n k ( V ) ) \vec n_k = (n_k^{(1)}, n_k^{(2)},…n_k^{(V)}) nk=(nk(1),nk(2),...nk(V))
利用Dirichlet-multi共轭,得到 β k β_k βk的后验分布为:
D i r i c h l e t ( β k ∣ η ⃗ + n ⃗ k ) Dirichlet(\beta_k | \vec \eta+ \vec n_k) Dirichlet(βk∣η+nk)
由于主题产生词不依赖具体某一个文档,因此文档主题分布和主题词分布是独立的。理解了上面这 M + K M+K M+K组Dirichlet-multi共轭,就理解了LDA的基本原理了。
2 Sklearn实现LDA模型
sklearn.decomposition.LatentDirichletAllocation包中,其算法实现基于EM算法。
11个参数,在实际的应用中,我们需要对 K K K, α α α, η η η 进行调参。
如果learning_method使用”batch”算法,则需要注意的参数较少。
如果用”online”,注意”learning_decay”, “learning_offset”,“total_samples”和“batch_size”等参数。
无论是”batch”还是”online”, n_topics( K K K), doc_topic_prior( α α α), topic_word_prior( η η η)都要注意。如果没有先验知识,则主要关注与主题数 K K K。可以说,主题数 K K K是LDA主题模型最重要的超参数。
1) n_topics: 即我们的隐含主题数K,需要调参。KK的大小取决于我们对主题划分的需求,比如我们只需要类似区分是动物,植物,还是非生物这样的粗粒度需求,那么K值可以取的很小,个位数即可。如果我们的目标是类似区分不同的动物以及不同的植物,不同的非生物这样的细粒度需求,则KK值需要取的很大,比如上千上万。此时要求我们的训练文档数量要非常的多。 2) doc_topic_prior:即我们的文档主题先验Dirichlet分布θd的参数α。一般如果我们没有主题分布的先验知识,可以使用默认值1/K。 3) topic_word_prior:即我们的主题词先验Dirichlet分布βk的参数η。一般如果我们没有主题分布的先验知识,可以使用默认值1/K。 4) learning_method: 即LDA的求解算法。有 ‘batch’ 和 ‘online’两种选择。 ‘batch’即我们在原理篇讲的变分推断EM算法,而"online"即在线变分推断EM算法,在"batch"的基础上引入了分步训练,将训练样本分批,逐步一批批的用样本更新主题词分布的算法。默认是"online"。选择了‘online’则我们可以在训练时使用partial_fit函数分布训练。不过在scikit-learn 0.20版本中默认算法会改回到"batch"。建议样本量不大只是用来学习的话用"batch"比较好,这样可以少很多参数要调。而样本太多太大的话,"online"则是首先了。 5)learning_decay:仅仅在算法使用"online"时有意义,取值最好在(0.5, 1.0],以保证"online"算法渐进的收敛。主要控制"online"算法的学习率,默认是0.7。一般不用修改这个参数。 6)learning_offset:仅仅在算法使用"online"时有意义,取值要大于1。用来减小前面训练样本批次对最终模型的影响。 7) max_iter :EM算法的最大迭代次数。 8)total_samples:仅仅在算法使用"online"时有意义, 即分步训练时每一批文档样本的数量。在使用partial_fit函数时需要。 9)batch_size: 仅仅在算法使用"online"时有意义, 即每次EM算法迭代时使用的文档样本的数量。 10)mean_change_tol :即E步更新变分参数的阈值,所有变分参数更新小于阈值则E步结束,转入M步。一般不用修改默认值。 11) max_doc_update_iter: 即E步更新变分参数的最大迭代次数,如果E步迭代次数达到阈值,则转入M步。 # 沙瑞金不分开 jieba.suggest_freq('沙瑞金', True) # -*- coding: utf-8 -*- import jieba for i in range(3): with open('./doc%d.txt'%(i+1), 'r', encoding="utf-8") as f1: document = f1.read() document_cut = jieba.cut(document) result = ' '.join(document_cut) print(result) f1.close() with open('./result%d.txt'%(i+1), 'w', encoding="utf-8") as f2: f2.write(result) f2.close() # 处理停用词 with open('./ChineseStopWords.txt', 'r', encoding="utf-8") as f: line = f.read() line = line.split('","') f.close() file_object = open('./stopwords.txt', 'w', encoding="utf-8") for i in range(len(line)): file_object.write(line[i] + '\n') file_object.close() with open('./stopwords.txt', 'r', encoding="utf-8") as f: lines = f.readlines() f.close() stopwords = [] for l in lines: stopwords.append(l.strip()) print(stopwords) # 加载三个文件 with open('./result1.txt', 'r', encoding="utf-8") as f: res1 = f.read() f.close() with open('./result2.txt', 'r', encoding="utf-8") as f: res2 = f.read() f.close() with open('./result3.txt', 'r', encoding="utf-8") as f: res3 = f.read() f.close() # 接着我们要把词转化为词频向量,注意由于LDA是基于词频统计的,因此一般不用TF-IDF来做文档特征。 from sklearn.feature_extraction.text import CountVectorizer corpus = [res1,res2,res3] cntVector = CountVectorizer(stop_words=stopwords) cntTf = cntVector.fit_transform(corpus) print(cntTf) # 输出即为所有文档中各个词的词频向量。有了这个词频向量,我们就可以来做LDA主题模型了,选择主题数K=3 from sklearn.decomposition import LatentDirichletAllocation lda = LatentDirichletAllocation(n_topics=3, max_iter=5, learning_method='online', learning_offset=50., random_state=0) docres = lda.fit_transform(cntTf) # 通过fit_transform函数,我们就可以得到文档的主题模型分布在docres中。而主题词分布则在lda.components_中。 print(docres)# 文档一属于主题三,文档二属于主题一,文档三属于主题二 print(lda.components_) # 注意由于LDA是基于词频统计的,因此一般不用TF-IDF来做文档特征。 from sklearn.feature_extraction.text import TfidfVectorizer with open('./result1.txt', 'r', encoding="utf-8") as f: res1 = f.read() f.close() with open('./result2.txt', 'r', encoding="utf-8") as f: res2 = f.read() f.close() with open('./result3.txt', 'r', encoding="utf-8") as f: res3 = f.read() f.close() vector = TfidfVectorizer(stop_words=stopwords) tfidf = vector.fit_transform([res1,res2,res3]) print(tfidf) wordlist = vector.get_feature_names()#获取词袋模型中的所有词 #print(wordlist) # tf-idf矩阵 元素a[i][j]表示j词在i类文本中的tf-idf权重 weightlist = tfidf.toarray() #print(len(weightlist[0])) #print(len(weightlist[0])) #print(len(weightlist[0])) #print(weightlist) #打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重 print("-------第res1段文本的词语tf-idf权重------" ) for j in range(len(wordlist)): if wordlist[j] in res1: print(wordlist[j],weightlist[0][j]) print("-------第res2段文本的词语tf-idf权重------" ) for j in range(len(wordlist)): if wordlist[j] in res2: print(wordlist[j],weightlist[1][j]) print("-------第res3段文本的词语tf-idf权重------" ) for j in range(len(wordlist)): if wordlist[j] in res3: print(wordlist[j],weightlist[2][j]) from sklearn.decomposition import LatentDirichletAllocation lda = LatentDirichletAllocation(n_topics=3, max_iter=5, learning_method='online', learning_offset=50., random_state=0) docres = lda.fit_transform(tfidf) print(docres) 代码和数据可以去我的资源页下载
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/210290.html原文链接:https://javaforall.net


