
Spark大数据分析与实战:基于Spark MLlib 实现音乐推荐
基于Spark MLlib 实现音乐推荐
一、实验背景:
熟悉 Audioscrobbler 数据集
基于该数据集选择合适的 MLlib 库算法进行数据处理
进行音乐推荐(或用户推荐)
二、实验目的:
计算AUC评分最高的参数
利用AUC评分最高的参数,给用户推荐艺术家
对多个用户进行艺术家推荐
利用AUC评分最高的参数,给艺术家推荐喜欢他的用户
三、实验步骤:
- 安装Hadoop和Spark
- 启动Hadoop与Spark
- 将文件上传到 HDFS
- 实现音乐推荐
四、实验过程:
1、安装Hadoop和Spark
具体的安装过程在我以前的博客里面有,大家可以通过以下链接进入操作:
提示:如果IDEA未构建Spark项目,可以转接到以下的博客:
IDEA使用Maven构建Spark项目:https://blog.csdn.net/weixin_/article/details/
2、启动Hadoop与Spark
查看3个节点的进程
master

slave1
slave2
3、将文件上传到 HDFS
Shell命令:
[root@master ~]# cd /opt/data/profiledata_06-May-2005/ [root@master profiledata_06-May-2005]# ls [root@master profiledata_06-May-2005]# hadoop dfs -put artist_alias.txt artist_data.txt user_artist_data.txt /spark/input 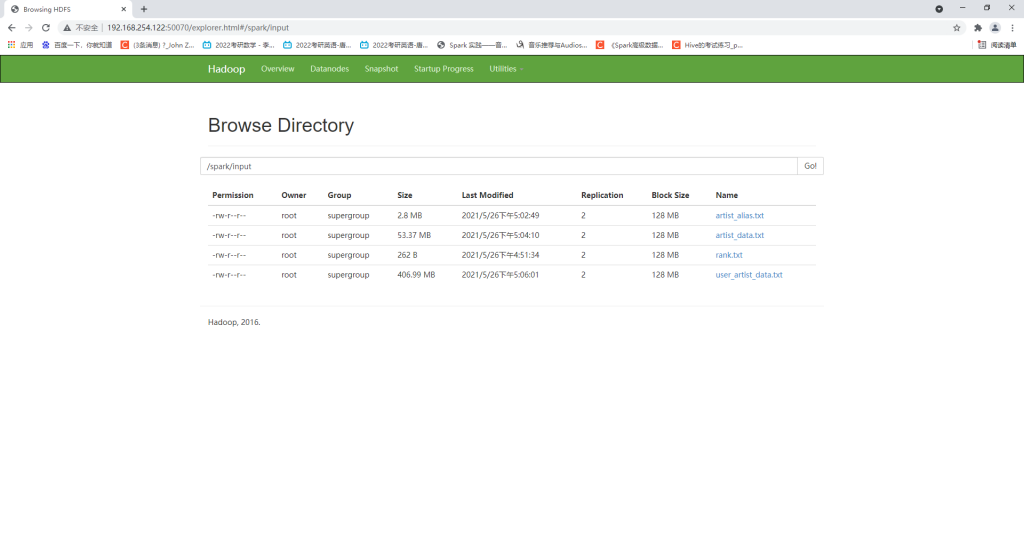
4、实现音乐推荐
源代码:
package com.John.SparkProject import org.apache.spark.SparkConf import org.apache.spark.broadcast.Broadcast import org.apache.spark.ml.recommendation.{
ALS, ALSModel} import org.apache.spark.sql.functions._ import org.apache.spark.sql.{
DataFrame, Dataset, SparkSession} import scala.collection.mutable.ArrayBuffer import scala.util.Random / * @author John * @Date 2021/5/25 12:49 */ object project02 {
def main(args: Array[String]): Unit = {
/ * 前期环境配置以及数据准备 */ // 创建一个SparkSession对象 val conf = new SparkConf() .setMaster("local[2]") .setAppName("Project02_RecommenderApp") .set("spark.sql.crossJoin.enabled", "true") val spark = new SparkSession.Builder() .config(conf) .getOrCreate() import spark.implicits._ // 导入 artist_data.txt 文件 (每个艺术家的 ID 和对应的名字) // 字段名分别是: artistid artist_name val rawArtistData = spark.read.textFile("hdfs://192.168.254.122:9000/spark/input/artist_data.txt") val artistIdDF = transformArtistData(rawArtistData) val artistIdDFtest = transformArtistData1(rawArtistData) // 导入 artist_alias.txt 文件 (将拼写错误的艺术家 ID 或ID 变体对应到该艺术家的规范 ID) // 字段名分别是: badid goodid val rawAliasData = spark.read.textFile("hdfs://192.168.254.122:9000/spark/input/artist_alias.txt") val artistAlias = transformAliasData(rawAliasData).collect().toMap // 导入 user_artist_data.txt 文件 (用户音乐收听数据) // 字段名分别是 userid artistid playcount val rawUserArtistData = spark.read.textFile("hdfs://192.168.254.122:9000/spark/input/user_artist_data.txt") // 整合数据 val allDF = transformUserArtistData(spark, rawUserArtistData, artistAlias) allDF.persist() // 拆分训练集和测试集 val Array(trainDF, testDF) = allDF.randomSplit(Array(0.9, 0.1)) trainDF.persist() // 查看一下指定 user 听过的艺术家 allDF.join(artistIdDFtest,"artist").select("name").filter("user=''").show(5) / * 根据题目要求参数 * 给用户推荐艺术家 */ // // 根据题目要求构建模型 // val als = new ALS() // .setSeed(Random.nextLong()) // .setImplicitPrefs(true) // .setRank(10) // 模型潜在因素个数 // .setRegParam(0.01) // 正则化参数 // .setAlpha(1.0) // 管理偏好观察值的 基线置信度 // .setMaxIter(5) // 最大迭代次数 // .setUserCol("user") // .setItemCol("artist") // .setRatingCol("count") // .setPredictionCol("prediction") // // 用训练数据训练模型 // val model = als.fit(trainDF) // // 释放缓存资源 // trainDF.unpersist() // // 开始推荐 // val userID = // val artistNum = 5 // val recommendDF = recommend(model, userID, artistNum, artistIdDF) // // val strings = recommendDF.map(_.mkString("|")).collect() // println(strings.toBuffer) / * 计算AUC评分最高的参数 * 原理:循环指定参数暴力计算,根据AUC计算出评分最高的参数进行建模 */ // // 艺术家id数据,用于AUC评分 // val allArtistIds = allDF.select("artist").as[Int].distinct().collect() // val bAllArtistIds = spark.sparkContext.broadcast(allArtistIds) // // // 网格搜索 // val evaluations = // // 利用for循环,生成不同的超参数配置 // for (rank <- Seq(5, 30); // regParam <- Seq(4.0, 0.0001); // alpha <- Seq(1.0, 40.0)) // yield {
// // 构建模型 // val als = new ALS() // .setSeed(Random.nextLong()) // .setImplicitPrefs(true) // .setRank(rank) // .setRegParam(regParam) // .setAlpha(alpha) // .setMaxIter(5) // .setUserCol("user") // .setItemCol("artist") // .setRatingCol("count") // .setPredictionCol("prediction") // val model = als.fit(trainDF) // val auc = areaUnderCurve(testDF, bAllArtistIds, model.transform) // // 释放资源 // model.userFactors.unpersist() // model.itemFactors.unpersist() // (auc, (rank, regParam, alpha)) // } // // 按评分降序输出各参数信息 // evaluations.sorted.reverse.foreach(println) // (0.77203,(30,4.0,40.0)) // 最优参数 // (0.63009,(30,4.0,1.0)) // (0.62062,(30,1.0E-4,40.0)) // (0.82363,(5,4.0,40.0)) // (0.29872,(5,1.0E-4,40.0)) // (0.71897,(5,4.0,1.0)) // (0.45514,(5,1.0E-4,1.0)) // (0.45603,(30,1.0E-4,1.0)) / * 利用AUC评分最高的参数 * 给用户推荐艺术家 */ // // 利用AUC评分最高的参数进行模型构建 // val als = new ALS() // .setSeed(Random.nextLong()) // .setImplicitPrefs(true) // .setRank(30) // 模型潜在因素个数 // .setRegParam(4.0) // 正则化参数 // .setAlpha(40.0) // 管理偏好观察值的 基线置信度 // .setMaxIter(5) // 最大迭代次数 // .setUserCol("user") // .setItemCol("artist") // .setRatingCol("count") // .setPredictionCol("prediction") // // 训练模型 // val model = als.fit(trainDF) // // 释放缓存资源 // trainDF.unpersist() // // 开始推荐 // val userID = // val artistNum = 5 // val recommendDF = recommend(model, userID, artistNum, artistIdDF) // recommendDF.show() // // val strings = recommendDF.map(_.mkString("|")).collect() // println(strings.toBuffer) / * 用测试数据对10个用户进行推荐 */ // // 利用AUC评分最高的参数进行模型构建 // val als = new ALS() // .setSeed(Random.nextLong()) // .setImplicitPrefs(true) // .setRank(30) // 模型潜在因素个数 // .setRegParam(4.0) // 正则化参数 // .setAlpha(40.0) // 管理偏好观察值的 基线置信度 // .setMaxIter(5) // 最大迭代次数 // .setUserCol("user") // .setItemCol("artist") // .setRatingCol("count") // .setPredictionCol("prediction") // // 训练模型 // val model = als.fit(trainDF) // //用测试数据对100个用户进行推荐 // val someUsers = testDF.select("user").as[Int].distinct.take(10) // // 推荐 // someUsers.map { user => // val recommendDF = recommend(model, user, 5, artistIdDF) // val strings = recommendDF.map(_.mkString("|")).collect() // (user, strings.toBuffer) // }.foreach(println) / * 利用AUC评分最高的参数 * 给艺术家推荐喜欢他的用户 */ // //利用AUC评分最高的参数进行模型构建 // val als = new ALS() // .setSeed(Random.nextLong()) // .setImplicitPrefs(true) // .setRank(30) // 模型潜在因素个数 // .setRegParam(4.0) // 正则化参数 // .setAlpha(40.0) // 管理偏好观察值的 基线置信度 // .setMaxIter(5) // 最大迭代次数 // .setUserCol("artist") // .setItemCol("user") // .setRatingCol("count") // .setPredictionCol("prediction") // // 训练模型 // val model = als.fit(trainDF) // // 释放缓存资源 // trainDF.unpersist() // // 开始推荐 // val artistID = 930 // val userNum = 100 // val recommendDF = recommendArtist(model, artistID, userNum, allDF) // val strings = recommendDF.select("user").map(_.mkString("|")).collect() // println(strings.toBuffer) // 关闭spark spark.stop() } / * 规范艺术家的ID,合并数据,创建一个总的数据集 * * @param spark SparkSession * @param rawUserArtistDS 用户和艺术家的关系数据集 * @param artistAlias 艺术家别名id,用于补全 * @return */ def transformUserArtistData(spark: SparkSession, rawUserArtistDS: Dataset[String], artistAlias: Map[Int, Int]): DataFrame = {
import spark.implicits._ // 广播变量 // 广播变量主要用于在迭代中一直需要被访问的只读变量 // 它将此变量缓存在每个 executor 里,以减少集群网络传输消耗 val bArtistAlias = spark.sparkContext.broadcast(artistAlias) rawUserArtistDS.map(line => {
val Array(userId, artistId, count) = line.split(' ').map(_.toInt) //以空格分隔每一行,并将数据转换为int类型 val finalArtistId = bArtistAlias.value.getOrElse(artistId, artistId) // 如果有值,那就可以得到这个值,如果没有就会得到一个默认值 (userId, finalArtistId, count) }).toDF("user", "artist", "count").cache() // 设置字段名称, cache() 以指示 Spark 在 RDD 计算好后将其暂时存储在集群的内存里 } / * 将 artist_data.txt 文件的数据转化为dataframe * * @param rawArtistData Dataset类型的artist_data数据 * @return */ def transformArtistData(rawArtistData: Dataset[String]): DataFrame = {
// 一个隐式implicit的转换方法,转换出正确的类型,完成编译。 import rawArtistData.sparkSession.implicits._ // 将每一行数据以tap分隔开,最后将数据类型转换为dataframe rawArtistData.flatMap(line => {
val (id, name) = line.span(_ != '\t') try {
if (name.nonEmpty) Some(id.toInt, name.trim) else None } catch {
case _: Exception => None } }).toDF("id", "name").cache() } / * 将 artist_data.txt 文件的数据转化为dataframe * * @param rawArtistData Dataset类型的artist_data数据 * @return */ def transformArtistData1(rawArtistData: Dataset[String]): DataFrame = {
// 一个隐式implicit的转换方法,转换出正确的类型,完成编译。 import rawArtistData.sparkSession.implicits._ // 将每一行数据以tap分隔开,最后将数据类型转换为dataframe rawArtistData.flatMap(line => {
val (id, name) = line.span(_ != '\t') try {
if (name.nonEmpty) Some(id.toInt, name.trim) else None } catch {
case _: Exception => None } }).toDF("artist", "name").cache() } / * 将 artist_alias.txt 文件的数据转化为dataframe * * @param rawAliasData Dataset类型的artist_alias数据 * @return */ def transformAliasData(rawAliasData: Dataset[String]): Dataset[(Int, Int)] = {
// 一个隐式implicit的转换方法,转换出正确的类型,完成编译。 import rawAliasData.sparkSession.implicits._ // 将每一行数据以tap分隔开,最后将数据类型转换为dataframe rawAliasData.flatMap(line => {
val Array(artist, alias) = line.split('\t') try {
if (artist.nonEmpty) Some(artist.toInt, alias.toInt) else None } catch {
case _: Exception => None } }) } / * 为指定用户推荐艺术家 * * @param model 训练好的ALS模型 * @param userId 用户id * @param howMany 推荐多少个艺术家 * @param artistIdDF 艺术家id和名称的关系映射 * @return */ def recommend(model: ALSModel, userId: Int, howMany: Int, artistIdDF: DataFrame): DataFrame = {
import artistIdDF.sparkSession.implicits._ // 推荐操作 // 根据 userId 推荐 artistId val toRecommend = model.itemFactors .select($"id".as("artist")) // .withColumn("user", lit(userId)) // 增加一列 userId // 根据 prediction 排序,得到输入推荐艺术家的个数 val topRecommendtions = model.transform(toRecommend) .select("artist", "prediction") .orderBy($"prediction".desc) .limit(howMany) // 将artistid转换为int,并将其放入数组 val recommendedArtistIds = topRecommendtions.select("artist").as[Int].collect() // 根据 id 得到指定的那一行数据,并将数据返回 artistIdDF.filter($"id" isin (recommendedArtistIds: _*)) } / * 为指定艺术家推荐用户 * * @param model 训练好的ALS模型 * @param artistId 艺术家id * @param howMany 推荐多少个艺术家 * @param userIdDF 用户id和名称的关系映射 * @return */ def recommendArtist(model: ALSModel, artistId: Int, howMany: Int, userIdDF: DataFrame): DataFrame = {
import userIdDF.sparkSession.implicits._ // 推荐操作 // 根据 artistId 推荐 userId val toRecommend = model.itemFactors .select($"id".as("user")) // .withColumn("artist", lit(artistId)) // 根据 prediction 排序,得到输入推荐用户的个数 val topRecommendtions = model.transform(toRecommend) .select("user", "prediction") .orderBy($"prediction".desc) .limit(howMany) // 将userid转换为int,并将其放入数组 val recommendedArtistIds = topRecommendtions.select("user").as[Int].collect() // 根据 id 得到指定的那一行数据,并将数据返回 userIdDF.filter($"user" isin (recommendedArtistIds: _*)).dropDuplicates(Seq("user")) } / * 计算AUC评分 * * @param positiveData 测试数据 * @param bAllArtistIDs 所有的艺术家ID * @param predictFunction model.transform * @return 评分 0-1 */ def areaUnderCurve(positiveData: DataFrame, bAllArtistIDs: Broadcast[Array[Int]], predictFunction: DataFrame => DataFrame): Double = {
import positiveData.sparkSession.implicits._ // What this actually computes is AUC, per user. The result is actually something // that might be called "mean AUC". // Take held-out data as the "positive". // Make predictions for each of them, including a numeric score val positivePredictions = predictFunction(positiveData.select("user", "artist")). withColumnRenamed("prediction", "positivePrediction") // BinaryClassificationMetrics.areaUnderROC is not used here since there are really lots of // small AUC problems, and it would be inefficient, when a direct computation is available. // Create a set of "negative" products for each user. These are randomly chosen // from among all of the other artists, excluding those that are "positive" for the user. val negativeData = positiveData.select("user", "artist").as[(Int, Int)]. groupByKey {
case (user, _) => user }. flatMapGroups {
case (userID, userIDAndPosArtistIDs) => val random = new Random() val posItemIDSet = userIDAndPosArtistIDs.map {
case (_, artist) => artist }.toSet val negative = new ArrayBuffer[Int]() val allArtistIDs = bAllArtistIDs.value var i = 0 // Make at most one pass over all artists to avoid an infinite loop. // Also stop when number of negative equals positive set size while (i < allArtistIDs.length && negative.size < posItemIDSet.size) {
val artistID = allArtistIDs(random.nextInt(allArtistIDs.length)) // Only add new distinct IDs if (!posItemIDSet.contains(artistID)) {
negative += artistID } i += 1 } // Return the set with user ID added back negative.map(artistID => (userID, artistID)) }.toDF("user", "artist") // Make predictions on the rest: val negativePredictions = predictFunction(negativeData). withColumnRenamed("prediction", "negativePrediction") // Join positive predictions to negative predictions by user, only. // This will result in a row for every possible pairing of positive and negative // predictions within each user. val joinedPredictions = positivePredictions.join(negativePredictions, "user"). select("user", "positivePrediction", "negativePrediction").cache() // Count the number of pairs per user val allCounts = joinedPredictions. groupBy("user").agg(count(lit("1")).as("total")). select("user", "total") // Count the number of correctly ordered pairs per user val correctCounts = joinedPredictions. filter($"positivePrediction" > $"negativePrediction"). groupBy("user").agg(count("user").as("correct")). select("user", "correct") // Combine these, compute their ratio, and average over all users val meanAUC = allCounts.join(correctCounts, Seq("user"), "left_outer"). select($"user", (coalesce($"correct", lit(0)) / $"total").as("auc")). agg(mean("auc")). as[Double].first() joinedPredictions.unpersist() meanAUC } } / * 规范艺术家的ID,合并数据,创建一个总的数据集 * * @param spark SparkSession * @param rawUserArtistDS 用户和艺术家的关系数据集 * @param artistAlias 艺术家别名id,用于补全 * @return */ def transformUserArtistData(spark: SparkSession, rawUserArtistDS: Dataset[String], artistAlias: Map[Int, Int]): DataFrame = {
import spark.implicits._ // 广播变量 // 广播变量主要用于在迭代中一直需要被访问的只读变量 // 它将此变量缓存在每个 executor 里,以减少集群网络传输消耗 val bArtistAlias = spark.sparkContext.broadcast(artistAlias) rawUserArtistDS.map(line => {
val Array(userId, artistId, count) = line.split(' ').map(_.toInt) //以空格分隔每一行,并将数据转换为int类型 val finalArtistId = bArtistAlias.value.getOrElse(artistId, artistId) // 如果有值,那就可以得到这个值,如果没有就会得到一个默认值 (userId, finalArtistId, count) }).toDF("user", "artist", "count").cache() // 设置字段名称, cache() 以指示 Spark 在 RDD 计算好后将其暂时存储在集群的内存里 } / * 将 artist_data.txt 文件的数据转化为dataframe * * @param rawArtistData Dataset类型的artist_data数据 * @return */ def transformArtistData(rawArtistData: Dataset[String]): DataFrame = {
// 一个隐式implicit的转换方法,转换出正确的类型,完成编译。 import rawArtistData.sparkSession.implicits._ // 将每一行数据以tap分隔开,最后将数据类型转换为dataframe rawArtistData.flatMap(line => {
val (id, name) = line.span(_ != '\t') try {
if (name.nonEmpty) Some(id.toInt, name.trim) else None } catch {
case _: Exception => None } }).toDF("id", "name").cache() } / * 将 artist_data.txt 文件的数据转化为dataframe * * @param rawArtistData Dataset类型的artist_data数据 * @return */ def transformArtistData1(rawArtistData: Dataset[String]): DataFrame = {
// 一个隐式implicit的转换方法,转换出正确的类型,完成编译。 import rawArtistData.sparkSession.implicits._ // 将每一行数据以tap分隔开,最后将数据类型转换为dataframe rawArtistData.flatMap(line => {
val (id, name) = line.span(_ != '\t') try {
if (name.nonEmpty) Some(id.toInt, name.trim) else None } catch {
case _: Exception => None } }).toDF("artist", "name").cache() } / * 将 artist_alias.txt 文件的数据转化为dataframe * * @param rawAliasData Dataset类型的artist_alias数据 * @return */ def transformAliasData(rawAliasData: Dataset[String]): Dataset[(Int, Int)] = {
// 一个隐式implicit的转换方法,转换出正确的类型,完成编译。 import rawAliasData.sparkSession.implicits._ // 将每一行数据以tap分隔开,最后将数据类型转换为dataframe rawAliasData.flatMap(line => {
val Array(artist, alias) = line.split('\t') try {
if (artist.nonEmpty) Some(artist.toInt, alias.toInt) else None } catch {
case _: Exception => None } }) } / * 为指定用户推荐艺术家 * * @param model 训练好的ALS模型 * @param userId 用户id * @param howMany 推荐多少个艺术家 * @param artistIdDF 艺术家id和名称的关系映射 * @return */ def recommend(model: ALSModel, userId: Int, howMany: Int, artistIdDF: DataFrame): DataFrame = {
import artistIdDF.sparkSession.implicits._ // 推荐操作 // 查询指定用户ID的推荐艺术家所有信息 val toRecommend = model.itemFactors .select($"id".as("artist")) // .withColumn("user", lit(userId)) // 增加一列 userId // 根据 prediction 排序,得到输入推荐艺术家的个数 val topRecommendtions = model.transform(toRecommend) .select("artist", "prediction") .orderBy($"prediction".desc) .limit(howMany) // 得到需要推荐艺术家的用户id val recommendedArtistIds = topRecommendtions.select("artist").as[Int].collect() // 根据 id 得到指定的那一行数据,并将数据返回 artistIdDF.filter($"id" isin (recommendedArtistIds: _*)) } / * 为指定艺术家推荐用户 * * @param model 训练好的ALS模型 * @param artistId 艺术家id * @param howMany 推荐多少个艺术家 * @param userIdDF 用户id和名称的关系映射 * @return */ def recommendArtist(model: ALSModel, artistId: Int, howMany: Int, userIdDF: DataFrame): DataFrame = {
import userIdDF.sparkSession.implicits._ // 推荐操作 // 根据 userId 推荐艺术家 val toRecommend = model.itemFactors .select($"id".as("user")) // .withColumn("artist", lit(artistId)) // 根据 prediction 排序,得到输入推荐艺术家的个数 val topRecommendtions = model.transform(toRecommend) .select("user", "prediction") .orderBy($"prediction".desc) .limit(howMany) // 得到需要推荐的艺术家的id val recommendedArtistIds = topRecommendtions.select("user").as[Int].collect() // 根据 id 得到指定的那一行数据,并将数据返回 userIdDF.filter($"user" isin (recommendedArtistIds: _*)).dropDuplicates(Seq("user")) } / * 计算AUC评分 * * @param positiveData 测试数据 * @param bAllArtistIDs 所有的艺术家ID * @param predictFunction model.transform * @return 评分 0-1 */ def areaUnderCurve(positiveData: DataFrame, bAllArtistIDs: Broadcast[Array[Int]], predictFunction: DataFrame => DataFrame): Double = {
import positiveData.sparkSession.implicits._ // What this actually computes is AUC, per user. The result is actually something // that might be called "mean AUC". // Take held-out data as the "positive". // Make predictions for each of them, including a numeric score val positivePredictions = predictFunction(positiveData.select("user", "artist")). withColumnRenamed("prediction", "positivePrediction") // BinaryClassificationMetrics.areaUnderROC is not used here since there are really lots of // small AUC problems, and it would be inefficient, when a direct computation is available. // Create a set of "negative" products for each user. These are randomly chosen // from among all of the other artists, excluding those that are "positive" for the user. val negativeData = positiveData.select("user", "artist").as[(Int, Int)]. groupByKey {
case (user, _) => user }. flatMapGroups {
case (userID, userIDAndPosArtistIDs) => val random = new Random() val posItemIDSet = userIDAndPosArtistIDs.map {
case (_, artist) => artist }.toSet val negative = new ArrayBuffer[Int]() val allArtistIDs = bAllArtistIDs.value var i = 0 // Make at most one pass over all artists to avoid an infinite loop. // Also stop when number of negative equals positive set size while (i < allArtistIDs.length && negative.size < posItemIDSet.size) {
val artistID = allArtistIDs(random.nextInt(allArtistIDs.length)) // Only add new distinct IDs if (!posItemIDSet.contains(artistID)) {
negative += artistID } i += 1 } // Return the set with user ID added back negative.map(artistID => (userID, artistID)) }.toDF("user", "artist") // Make predictions on the rest: val negativePredictions = predictFunction(negativeData). withColumnRenamed("prediction", "negativePrediction") // Join positive predictions to negative predictions by user, only. // This will result in a row for every possible pairing of positive and negative // predictions within each user. val joinedPredictions = positivePredictions.join(negativePredictions, "user"). select("user", "positivePrediction", "negativePrediction").cache() // Count the number of pairs per user val allCounts = joinedPredictions. groupBy("user").agg(count(lit("1")).as("total")). select("user", "total") // Count the number of correctly ordered pairs per user val correctCounts = joinedPredictions. filter($"positivePrediction" > $"negativePrediction"). groupBy("user").agg(count("user").as("correct")). select("user", "correct") // Combine these, compute their ratio, and average over all users val meanAUC = allCounts.join(correctCounts, Seq("user"), "left_outer"). select($"user", (coalesce($"correct", lit(0)) / $"total").as("auc")). agg(mean("auc")). as[Double].first() joinedPredictions.unpersist() meanAUC } } 查看一下听过的艺术家
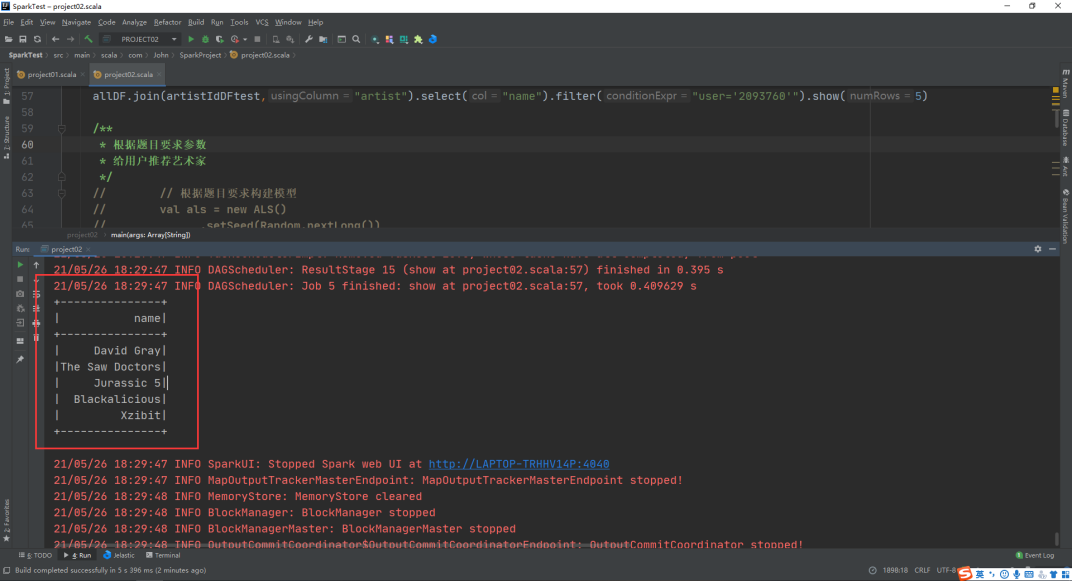
查看结果:
David gray:英国民谣创作才子
The Saw Doctors:雷鬼乐乐队
Jurassic 5:说唱团体
Blackalicious:说唱团体
Xzibit:说唱歌手
根据题目要求参数,给用户2093760推荐艺术家
推荐结果:
50 Cent:说唱歌手
Dr. Dre:说唱歌手
Ludacris:说唱歌手
2Pac:说唱歌手
The Game:说唱歌手
结论:
我们可以看出给用户推荐的歌手都是说唱歌手,这么绝对的推荐不一定是最优的。
因此我们需要计算AUC评分,用评分最高的参数再次对用户进行推荐,得出相对比较靠谱的推荐结果!

什么是AUC?
这里问题来了,这个AUC评分究竟是什么东西,为什么它能评估模型的好坏?
简单的概括一下,AUC是一个模型的评价指标,用于分类任务
这个指标简单来说其实就是随机抽出一对样本(一个正样本,一个负样本),然后用训练得到的分类器来对这两个样本进行预测,预测得到正样本的概率大于负样本概率的概率

如何计算AUC?
方法一:
在有M个正样本,N个负样本的数据集里
一共有MN对样本(一对样本即,一个正样本与一个负样本)
统计这M
N对样本里,正样本的预测概率大于负样本的预测概率的个数


单纯的看这个公式,估计大家看的不是特别明白,那么我举一个小例子!
假设有4条样本
2个正样本(label=1),2个负样本(label=0),那么M*N=4

两两进行比较,即总共有4个样本对,分别是:
(D,B)0.8大于0.4 结果为1
(D,A)0.8大于0.1 结果为1
(C,B)0.35小于0.4 结果为0
(C,A)0.35大于0.1 结果为1

方法二:
另外一个方法就是利用下面的公式

这是上面每个参数代表的含义:

同样用刚才的例子来看公式:

我们再根据每个样本的概率进行排序:

然后就根据公式进行计算:

前面的累加就将标签为1的样本他对应的rank加起来,后面的M和N就是正样本和负样本的数量。

那么如果正样本和负样本的概率相同怎么办?
比如说下面的例子:

其实很简单,我们只需要将概率相同的正样本和负样本的rank都加起来后求平均值即可!

这里介绍完AUC后,我们就开始进行计算!
推荐结果:
[unknown]:未知的原创歌手
Maroon 5:美国摇滚乐队
Bob Marley:雷鬼乐歌手
Eminem:说唱歌手
Green Day:美国朋克乐队
结论:
我们就可以看出,现在的结果就比较多样性。因为我们的听歌爱好其实不仅仅与歌的类型有关系,还可能与国家地区、文化信仰甚至国情民势都有关系。所以大家在做这一方面的研究时,考虑的方面得全面!

用测试数据对10个用户进行推荐
推荐结果:
(,ArrayBuffer(1361|Trans Am, |The Plastic Constellations, |Thunderbirds Are Now!, |The Advantage, |764-HERO))
(,ArrayBuffer(|[unknown], |ATB, |DJ Tiësto, |O-Zone, |Paul Oakenfold))
(,ArrayBuffer(|Frank Black and the Catholics, |Lo Fidelity Allstars, 4629|Unknown, |Eddie Izzard, |Porno for Pyros))
(,ArrayBuffer(3941|Gotan Project, 1181|David Holmes, |DJ BC, |The Kleptones, |Mr. Scruff))
(,ArrayBuffer(|[unknown], |The Postal Service, |Bright Eyes, |The Killers, 3327|Weezer))
(,ArrayBuffer(|Kitaro, 5925|Carl Orff, |Antonio Vivaldi, |石井妥師, |Eric Serra))
(,ArrayBuffer(|Ludovico Einaudi, |Amiel, |Missy Higgins, |Hal, |王菲))
(,ArrayBuffer(|[unknown], 930|Eminem, 1854|Linkin Park, 4267|Green Day, |blink-182))
(,ArrayBuffer(|[unknown], 2439|HiM, |Slipknot, 4468|System of a Down, |Metallica))
(,ArrayBuffer(|Wilco, |Belle and Sebastian, |The Decemberists, |The Magnetic Fields, |Fiona Apple))

利用AUC评分最高的参数,给艺术家推荐喜欢他的用户
这里我是给我最喜欢的歌手Eminem进行用户推荐!
推荐结果:(由于用户的信息只有ID,因此我将所有ID都放在了一个ArrayBuffer里面)
到此,咱们的音乐推荐就完成啦!
五、实验结论:
实验要点:
实验主要考察了大家对Dataframe的转换,也让大家熟悉基于 Mllib 的数据分析流程以及了解机器学习算法超参数的选择。
实验心得:
此实验的推荐我们可以广泛利用到其他的推荐系统,比如说电影推荐系统,购物推荐系统等等。通过这些推荐,我们可以更加明白用户需要什么、喜欢什么,从而进行针对性地推荐,因此来增加我们商品的销售以及其他利益!
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/210384.html原文链接:https://javaforall.net


