
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
目录
知识补充
在正式阅读之前,首先需要理解以下基本概念以帮助你更好的了解数据仓库:
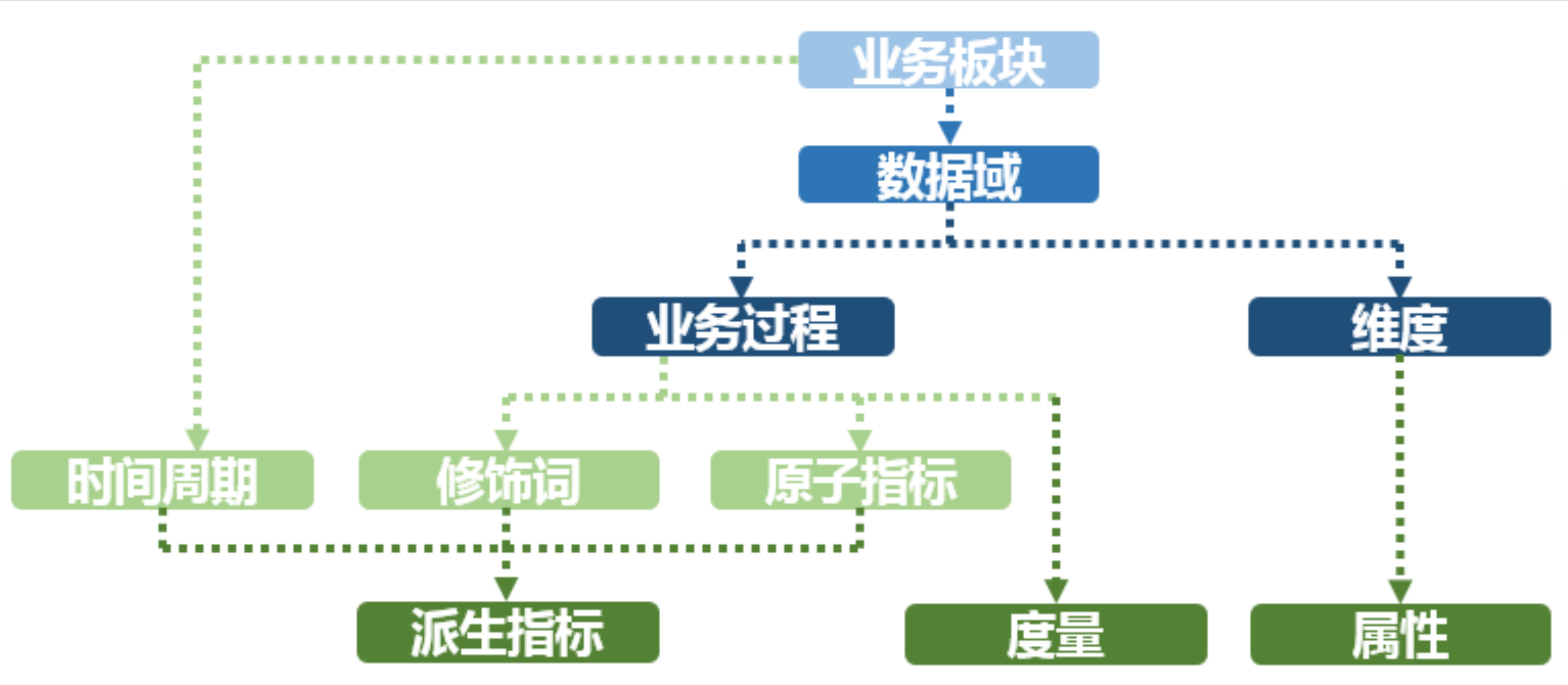
- 业务板块:比数据域更高维度的业务划分方法,适用于庞大的业务系统。
- 维度:维度建模由Ralph Kimball提出。维度模型主张从分析决策的需求出发构建模型,为分析需求服务。维度是度量的环境,是我们观察业务的角度,用来反映业务的一类属性。属性的集合构成维度,维度也可以称为实体对象。例如,在分析交易过程时,可以通过买家、卖家、商品和时间等维度描述交易发生的环境。
- 属性(维度属性):维度所包含的表示维度的列称为维度属性。维度属性是查询约束条件、分组和报表标签生成的基本来源,是数据易用性的关键。
- 度量:在维度建模中,将度量称为事实,将环境描述为维度,维度是用于分析事实所需要的多样环境。度量通常为数值型数据,作为事实逻辑表的事实。
- 指标:指标分为原子指标和派生指标。原子指标是基于某一业务事件行为下的度量,是业务定义中不可再拆分的指标,是具有明确业务含义的名词,体现明确的业务统计口径和计算逻辑,例如支付金额。
- 原子指标=业务过程+度量。
- 派生指标=时间周期+修饰词+原子指标,派生指标可以理解为对原子指标业务统计范围的圈定。
- 业务限定:统计的业务范围,筛选出符合业务规则的记录(类似于SQL中where后的条件,不包括时间区间)。
- 统计周期:统计的时间范围,例如最近一天,最近30天等(类似于SQL中where后的时间条件)。
- 统计粒度:统计分析的对象或视角,定义数据需要汇总的程度,可理解为聚合运算时的分组条件(类似于SQL中的group by的对象)。粒度是维度的一个组合,指明您的统计范围。例如,某个指标是某个卖家在某个省份的成交额,则粒度就是卖家、地区这两个维度的组合。如果您需要统计全表的数据,则粒度为全表。在指定粒度时,您需要充分考虑到业务和维度的关系。统计粒度常作为派生指标的修饰词而存在。

离线数仓的分层设计
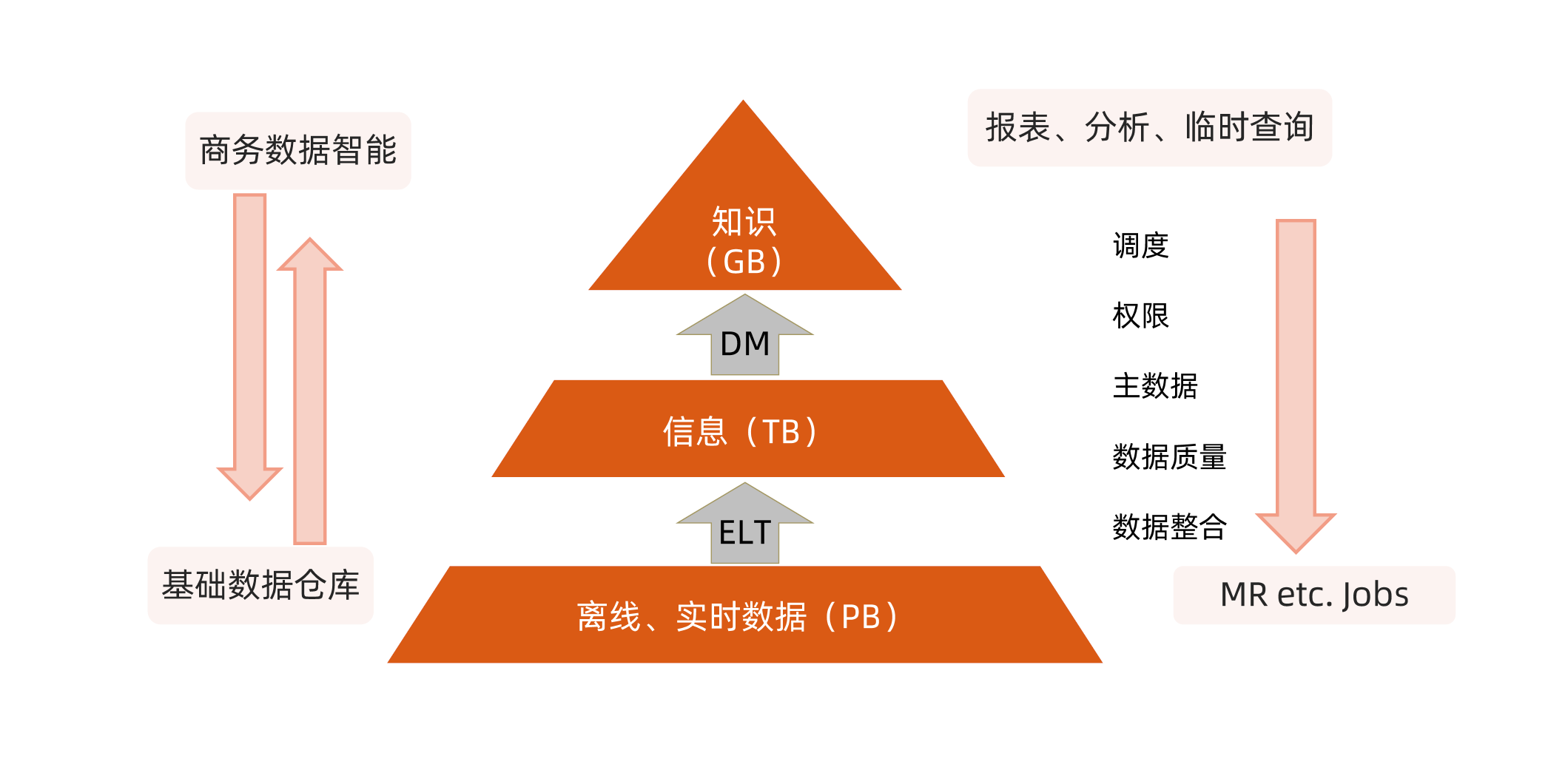
传统数仓:
数仓为什么要分层呢?
- 清晰数据结构:每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解。
- 数据血缘追踪:简单来讲一张业务表的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
- 减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
- 屏蔽原始数据的异常:屏蔽业务的影响,不必改一次业务就需要重新接入数据。
所以我们从理论上先来理解分层:
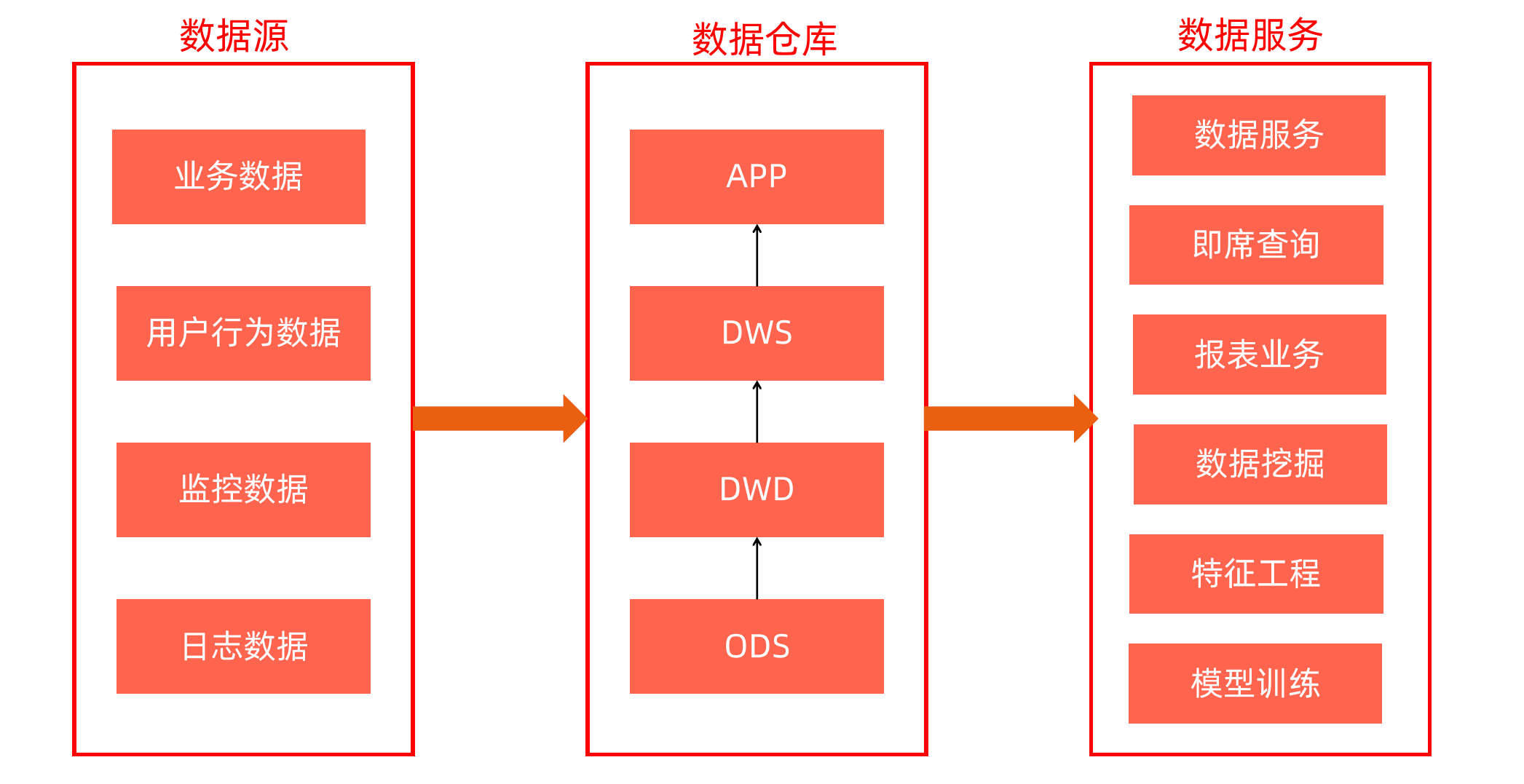
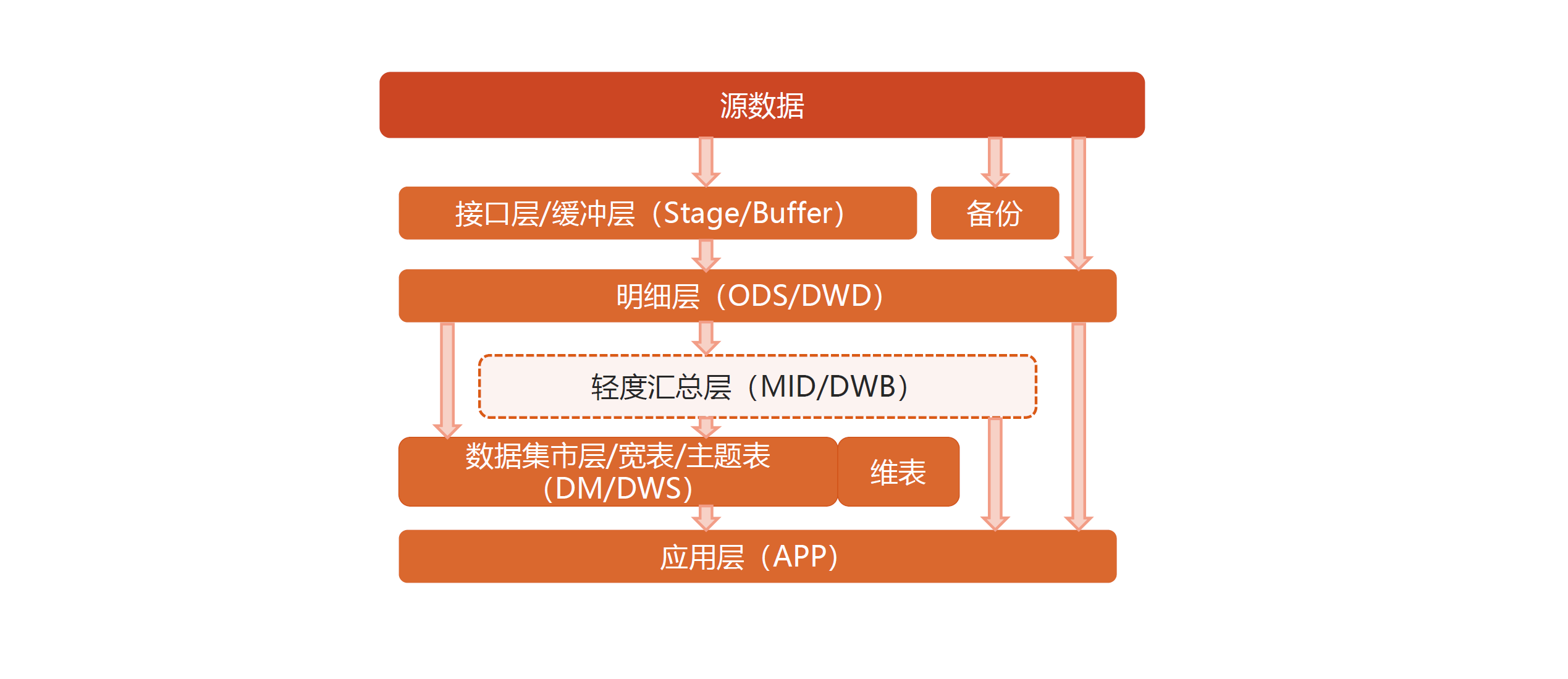
我们来做一个抽象,可以把数据仓库分为下面三个层,即:数据运营层、数据仓库层和数据产品层。
数据分层 ODS
ODS全称是Operational Data Store,操作数据存储。
“面向主题”的数据贴源层,也叫ODS层,是最接近数据源中数据的一层,数据源中的数据,经过抽取、洗净、传输,也就说传说中的ETL之后,装入本层。本层的数据,总体上大多是按照源头业务系统的分类方式而分类的。
数据分层 DW
这一层是数据仓库的总体,它包含:
- 公共汇总粒度事实层(DWS):以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表,以宽表化手段物理化模型。构建命名规范、口径一致的统计指标,为上层提供公共指标,建立汇总宽表、明细事实表。
公共汇总粒度事实层的表通常也被称为汇总逻辑表,用于存放派生指标数据。
- 明细粒度事实层(DWD):以业务过程作为建模驱动,基于每个具体的业务过程特点,构建最细粒度的明细层事实表。可以结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,即宽表化处理。
明细粒度事实层的表通常也被称为逻辑事实表。
数据分层 APP
数据产品层(APP),这一层是提供为数据产品使用的结果数据。
在这里,主要是提供给数据产品和数据分析使用的数据,一般会存放在es、mysql等系统中供线上系统使用,也可能会存在 Hive 或者Druid中供数据分析和数据挖掘使用。
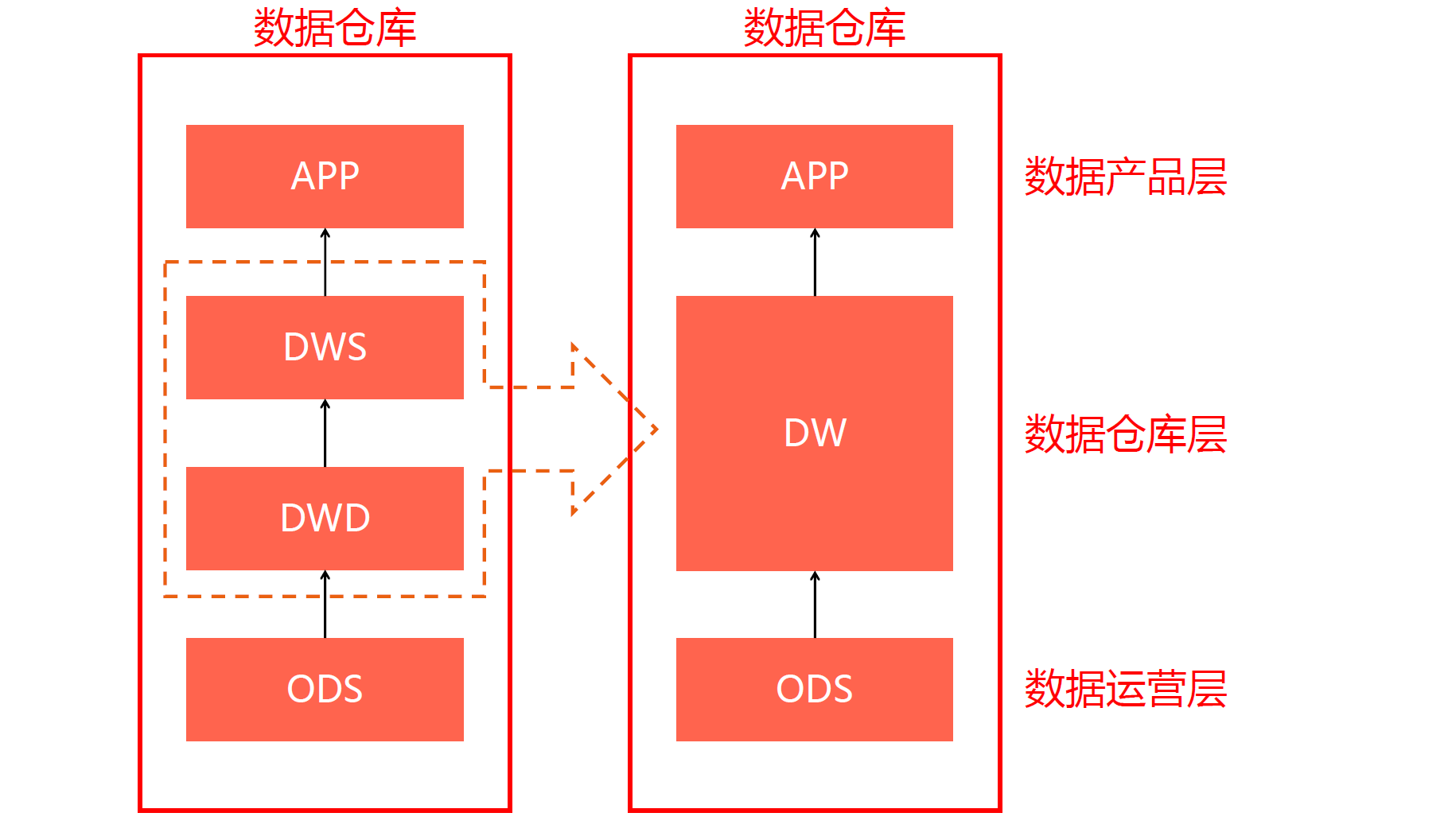
当然在实际中,根据需要我们还可以扩充层次架构:
数据建模
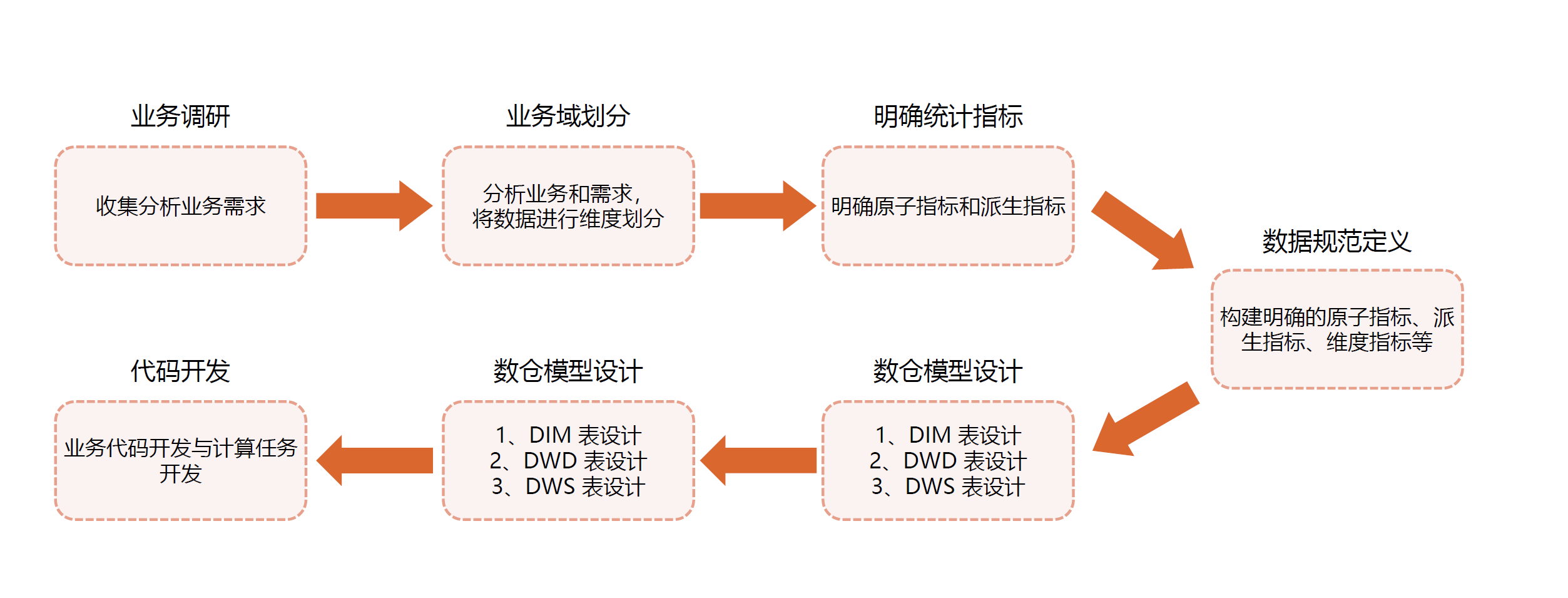
首先当然是明确需求:
- 业务量(DAU),数据量(GB/TB/PB量级),增长率?
- 用于离线数据分析场景,是否需要支持实时分析?可能涉及复杂查询?需要支持上层报表系统,是否开放给非技术人员使用?
- 业务部门目前有没有明确的数据需求,半年内是否有数据监测分析和指标统计等需求?
- 是否有采购商业级产品的预算,是否所以优先使用开源产品?
之后就是考虑成本:这里不做建议
然后考虑规模:
- 对于未来一段时期内的数据量,需要有大致的评估
- Oracle RAC支持少量节点集群和scale up场景
- Hadoop集群可以进行水平扩展(scale out)
- PG加上proxy 也可以水平分片
- 除了引擎,外围系统同样需要考虑数据规模
- 除了数据规模,还需要考虑租户用量
之后就是易用性、运维等等
再之后我们搭建数仓分层和引擎架构:
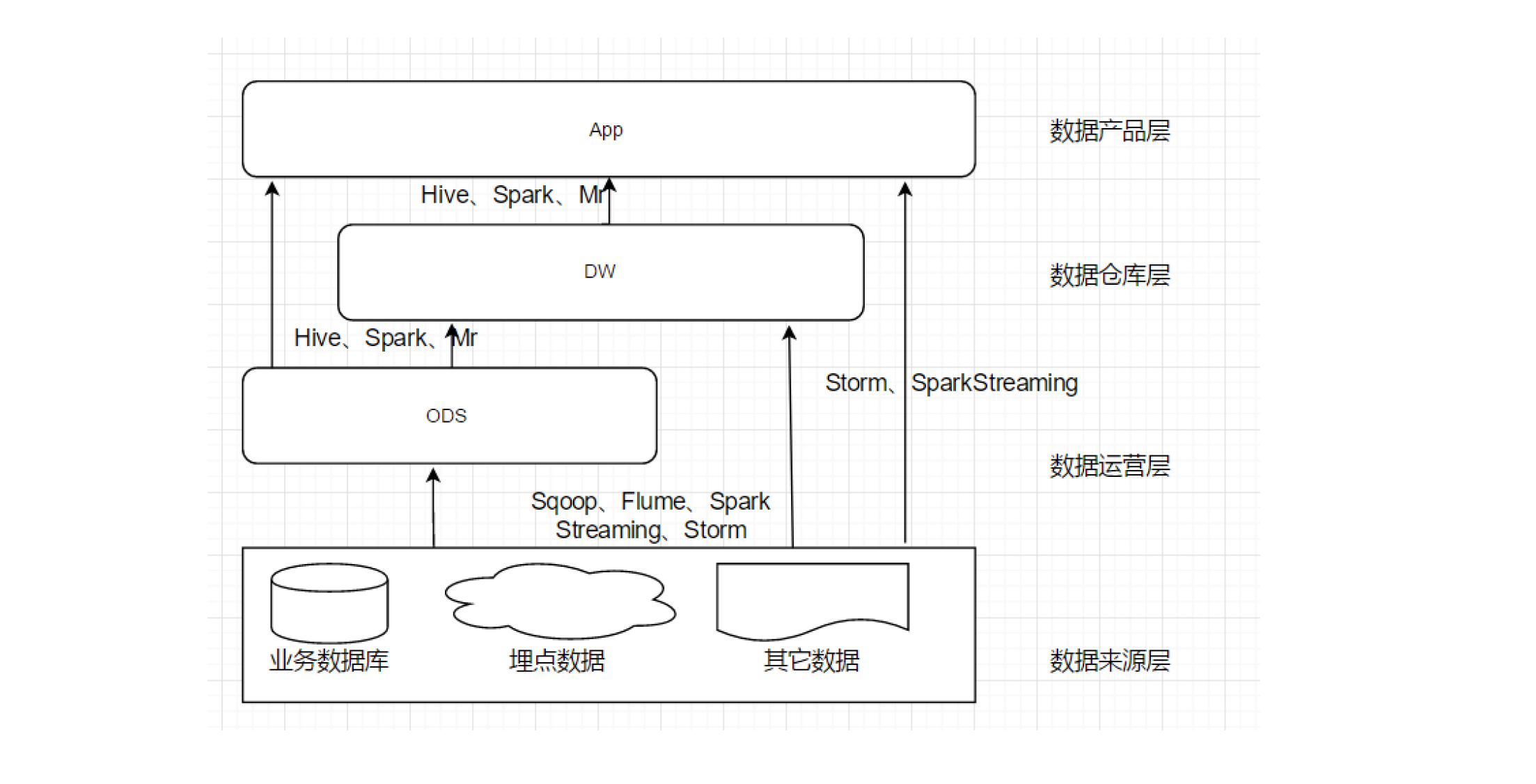
相关技术栈:
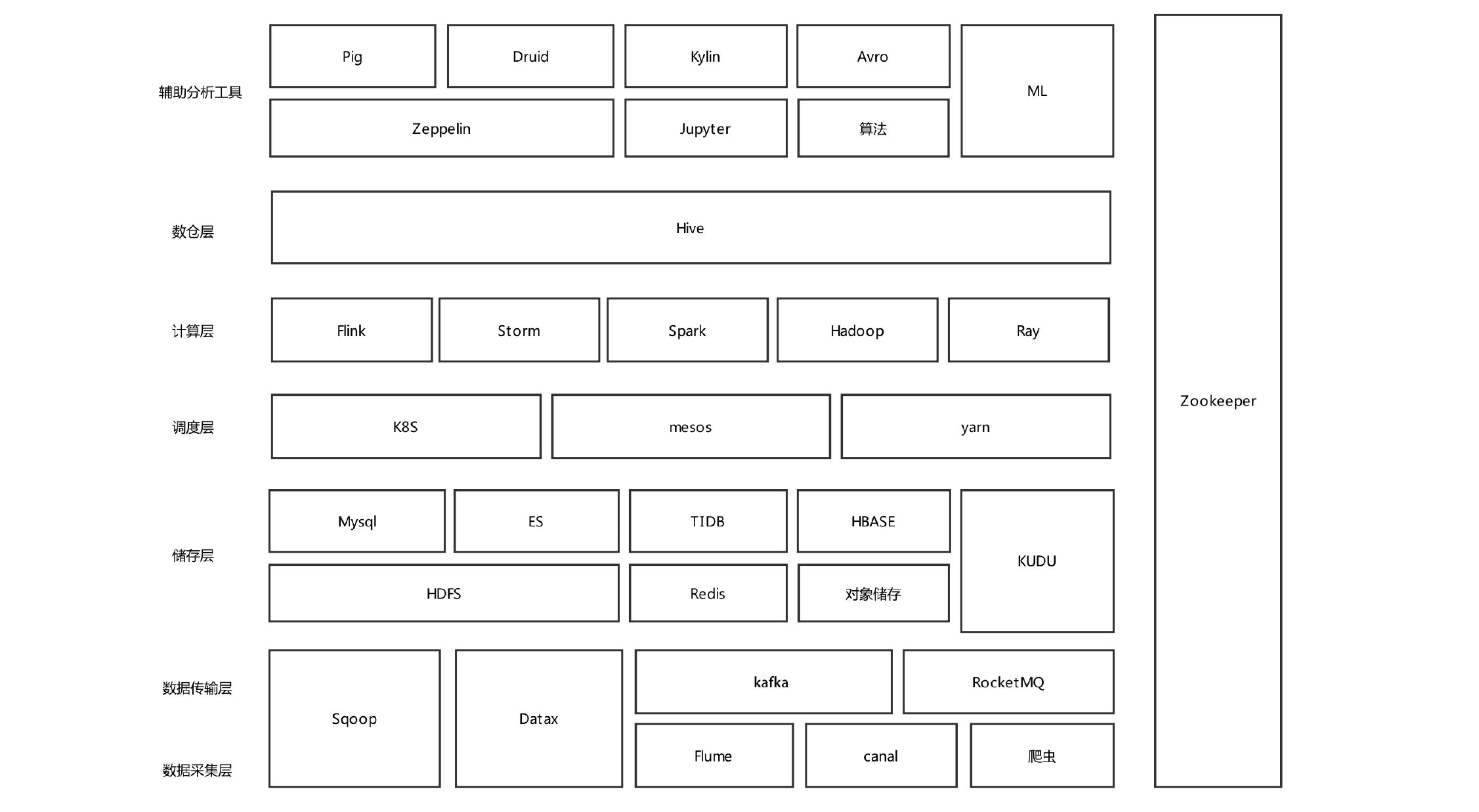
可以参考下面的技术选型:
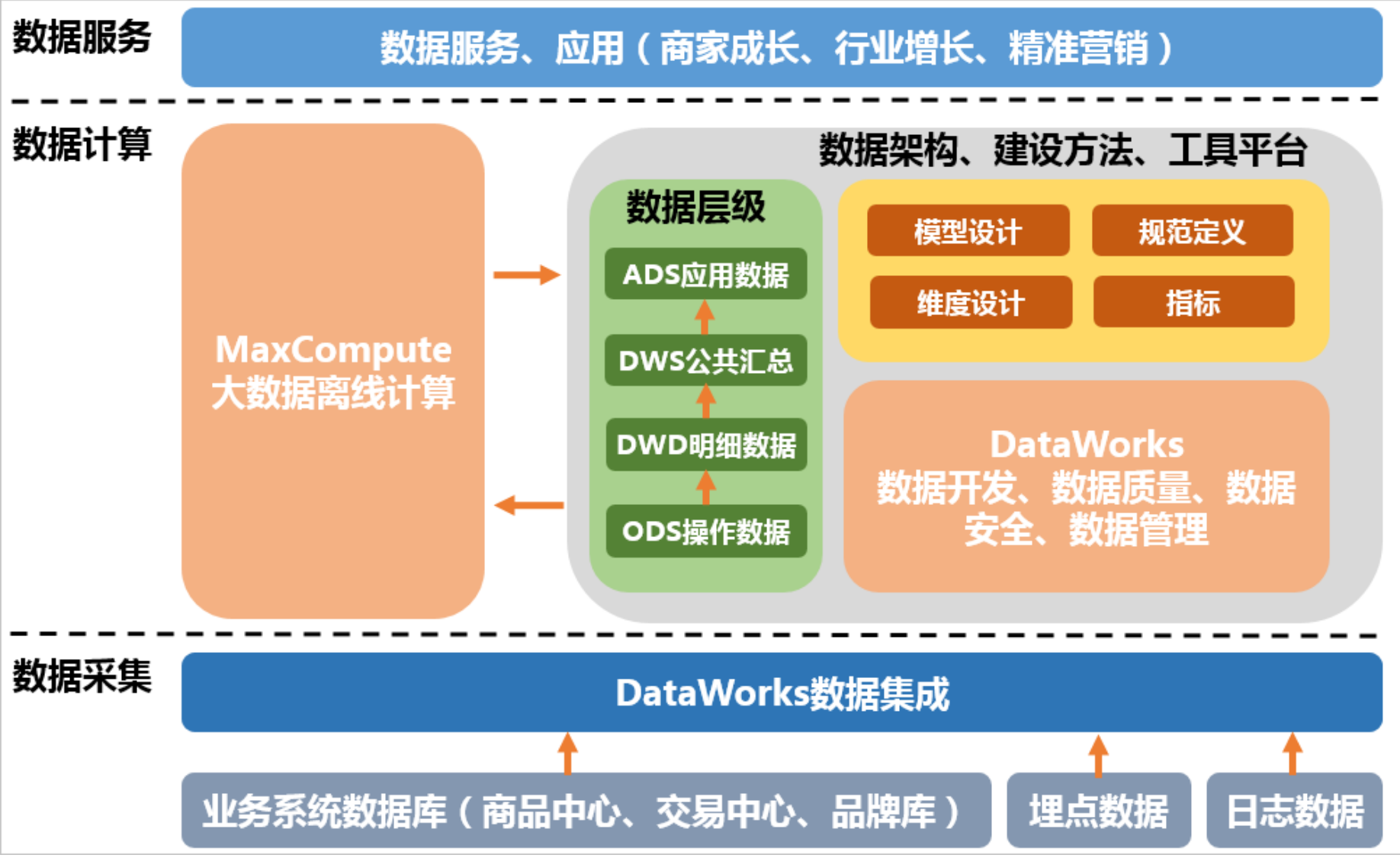
那么这样的数据仓库,sparksql有什么优势呢?
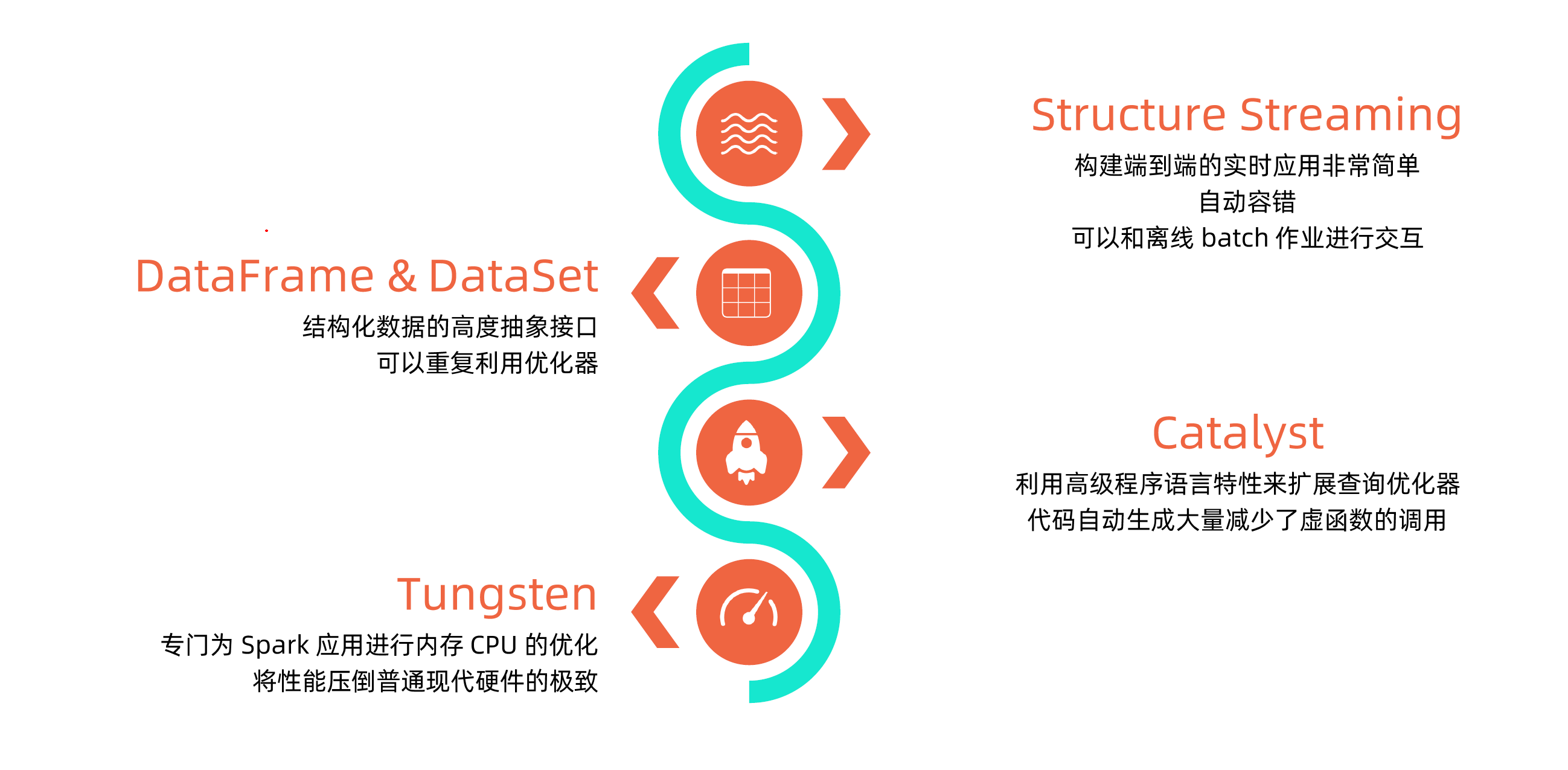
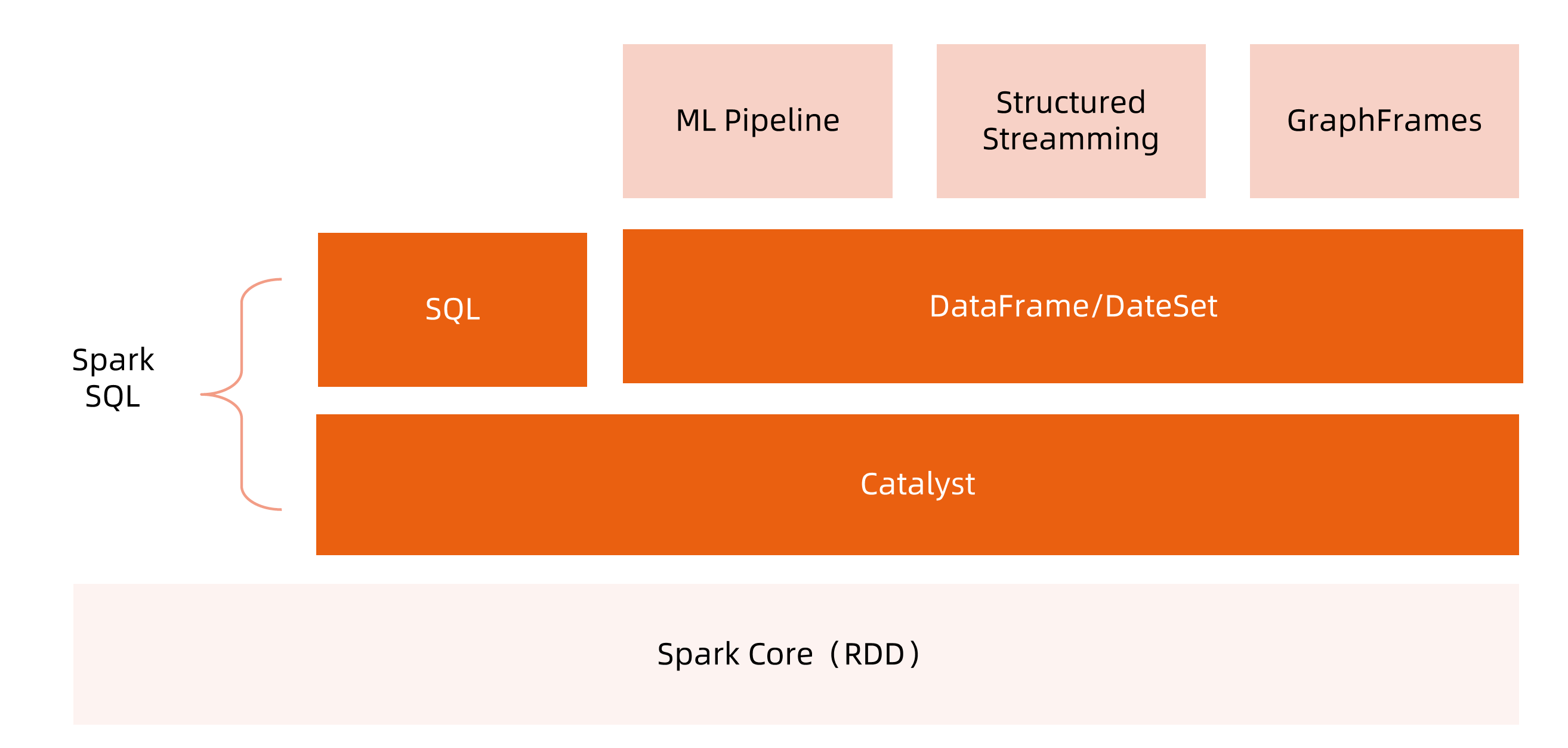
sparksql在其中有自己的架构体系:
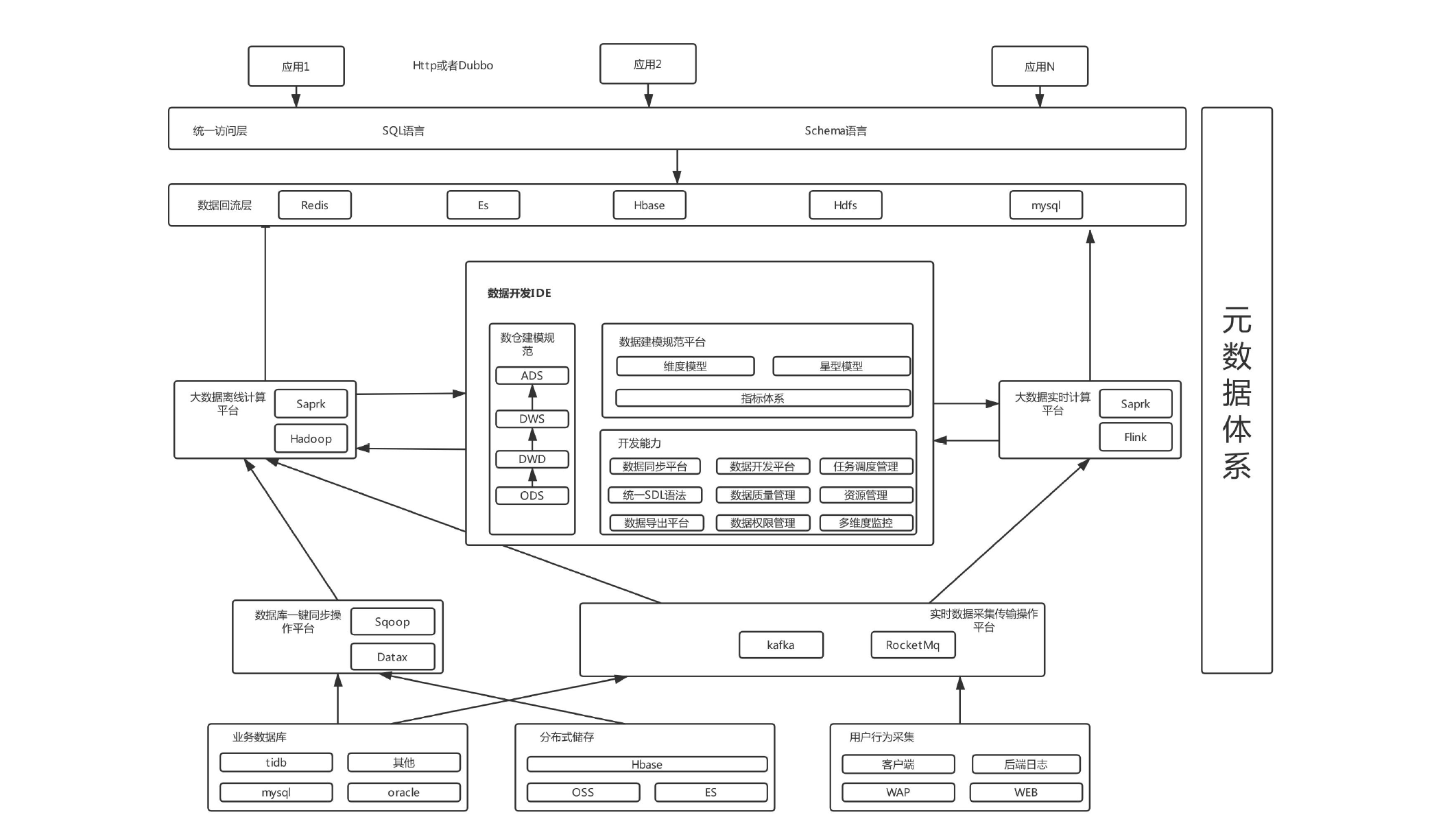
最后我们来看一个真实的数仓架构:
写在最后,数据仓库也是很多表组成的,请永远记住什么是数据仓库?
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。 为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
更多数据仓库的介绍,请移步:
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/210462.html原文链接:https://javaforall.net


