
评测指标是衡量一个算法是否出色的一个重要部分,好的指标能让我们这些炼丹学徒知道,练出来的丹药是否有效果。那么在机器学习中有哪些值得一探究竟的指标呢?本文就PR图,ROC、AUC、mAP这4个方面进行详细探究。
总的来说评价指标的核心得从二分类问题说起:一个类,它实际值有0、1两种取值,即负例、正例;而二分类算法预测出来的结果,也只有0、1两种取值,即负例、正例。我们不考虑二分类算法细节,当作黑箱子就好;我们关心的是,预测的结果和实际情况匹配、偏差的情况。
从TP、FP、TN、FN讲起。那么说起这些指标,则又要需要说混淆矩阵了。
混淆矩阵
混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型作出的分类判断两个标准进行汇总。这个名字来源于它可以非常容易的表明多个类别是否有混淆(正类预测成负类)。
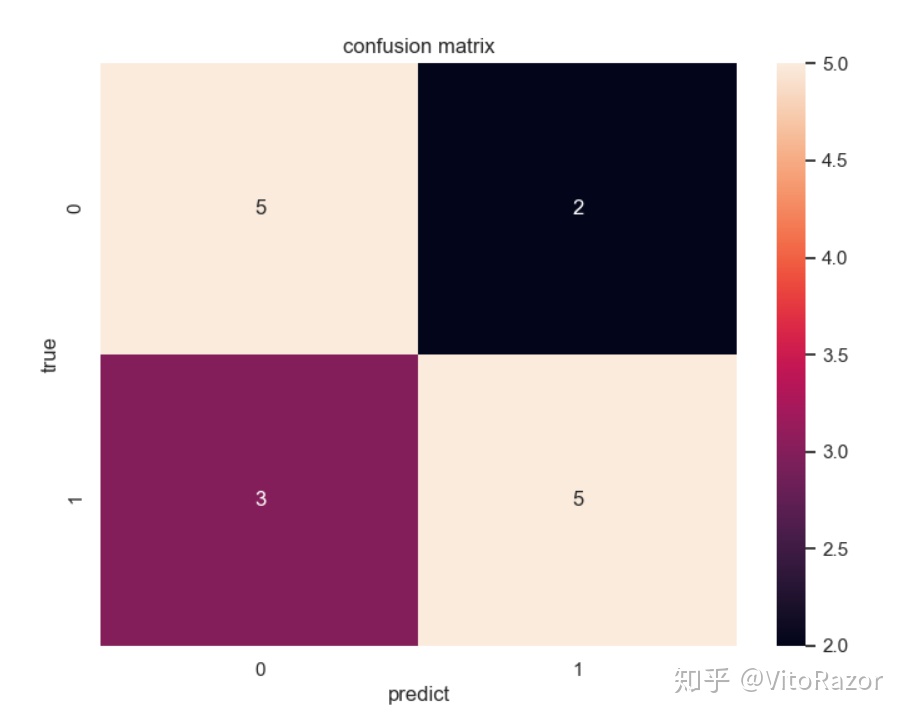

这里,我们认为 1 为正类, 0为负类,那么我们可以得出这样的指标:
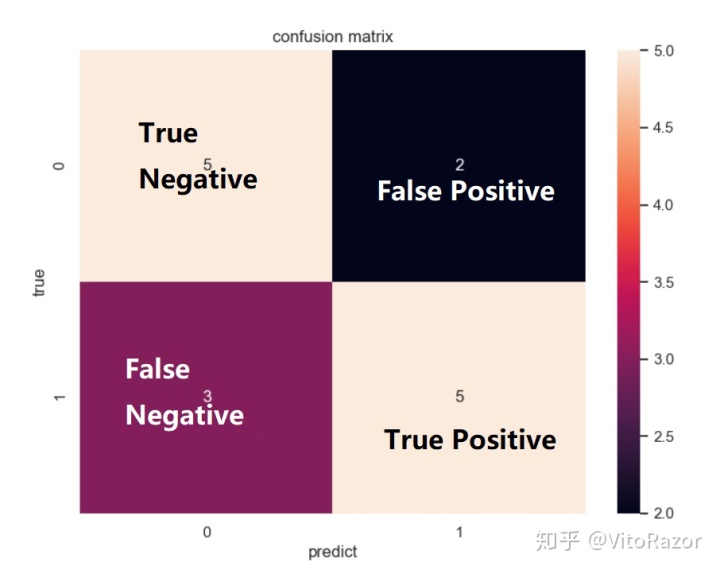
P (Positive) 和 N(Negative) 代表模型的判断结果
T (True) 和 F(False) 评价模型的判断结果是否正确
FP: 假正例,模型的判断是正例 (P) ,实际上这是错误的(F),连起来就是假正例
FN:假负例,模型的判断是负例(N),实际上这是错误的(F),连起来就是假正例
TP:真正例, 模型的判断是正例(P),实际上它也是正例,预测正确(T),连起来就是真正例
TN:真负例,模型的判断是负例(N),实际上它也是负例,预测正确(T),就是真正例

细致得说下具体说下从混淆矩阵中能活得那些有用的指标:
Accuracy:准确率
也就所有预测正确的和所有test集的比例。
准确率=预测正确的样本数/所有样本数,即预测正确的样本比例(包括预测正确的正样本和预测正确的负样本)。
Precision:查准率
用于衡量模型对某一类的预测有多准。
Recall:召回率(真正类率)
指的是某个类别的Recall。Recall表示某一类样本,预测正确的与所有Ground Truth的比例。

FPR:负正类率
代表分类器预测的正类中实际负实例占所有负实例的比例。FPR = 1 – TNR
TNR:真负类率
代表分类器预测的负类中负实例占所有负实例的比例,TNR=1-FPR
ROC 和 AUC
roc曲线:接收者操作特征(receiveroperating characteristic), roc曲线上每个点反映着对同一信号刺激的感受性。
横轴:假正类率 (false postive rate, FPR),特异度,划分实例中所有负例占所有负例的比例;TNR=1-FPR。
纵轴:真正类率 ==Recall(true postive rate, TPR),灵敏度,Sensitivity(正类覆盖率)
假设已经得出一系列样本被划分为正类的概率,然后按照从大到小排序,
我们从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于这个threshold时,我们认为它为正样本,否则为负样本。从第一个样本开始,设该样本的Score值为阈值,则该样本及之后的样本(均比该样本概率值小)判为负样本,即所有样本判为全负,计算得TPR=FPR=0,即ROC曲线(0,0)点;再选择第二个样本点的Score作为阈值,大于等于该阈值的样本(在该样本之前)判为正样本,小于该阈值的判为负样本,那么此时TP = 1, TP+FN = all gt,计算TPR = recall 。负正类率()
AUC(Area under Curve):Roc曲线下的面积,介于0.1和1之间。Auc作为数值可以直观的评价分类器的好坏,值越大越好。
可以这么理解


计算AUC
AUC(Area under Curve):Roc曲线下的面积,介于0.1和1之间。Auc作为数值可以直观的评价分类器的好坏,值越大越好。
首先AUC值是一个概率值,当你随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
最直观的,根据AUC这个名称,我们知道,计算出ROC曲线下面的面积,就是AUC的值。事实上,这也是在早期 Machine Learning文献中常见的AUC计算方法。由于我们的测试样本是有限的。我们得到的AUC曲线必然是一个阶梯状的。因此,计算的AUC也就是这些阶梯 下面的面积之和。这样,我们先把score排序(假设score越大,此样本属于正类的概率越大),然后一边扫描就可以得到我们想要的AUC。但是,这么 做有个缺点,就是当多个测试样本的score相等的时候,我们调整一下阈值,得到的不是曲线一个阶梯往上或者往右的延展,而是斜着向上形成一个梯形。此 时,我们就需要计算这个梯形的面积。由此,我们可以看到,用这种方法计算AUC实际上是比较麻烦的。
测试任意给一个正类样本和一个负类样本,正类样本的score有多大的概率大于负类样本的score。具体来说就是统计一下所有的 M×N(M为正类样本的数目,N为负类样本的数目)个正负样本对中,有多少个组中的正样本的score大于负样本的score。当二元组中正负样本的 score相等的时候,按照0.5计算。然后除以MN。实现这个方法的复杂度为O(n^2)。n为样本数(即n=M+N)
公式法:它也是首先对score从大到小排序,然后令最大score对应的sample 的rank为n,第二大score对应sample的rank为n-1,以此类推。然后把所有的正类样本的rank相加,再减去M-1种两个正样本组合的情况。得到的就是所有的样本中有多少对正类样本的score大于负类样本的score。然后再除以M×N。即
、为了求的组合中正样本的score值大于负样本,如果所有的正样本score值都是大于负样本的,那么第一位与任意的进行组合score值都要大,我们取它的rank值为n,但是n-1中有M-1是正样例和正样例的组合这种是不在统计范围内的(为计算方便我们取n组,相应的不符合的有M个),所以要减掉,那么同理排在第二位的n-1,会有M-1个是不满足的,依次类推,故得到后面的公式M*(M+1)/2,我们可以验证在正样本score都大于负样本的假设下,AUC的值为1。
2、根据上面的解释,不难得出,rank的值代表的是能够产生score前大后小的这样的组合数,但是这里包含了(正,正)的情况,所以要减去这样的组(即排在它后面正例的个数),即可得到上面的公式
另外,特别需要注意的是,再存在score相等的情况时,对相等score的样本,需要 赋予相同的rank(无论这个相等的score是出现在同类样本还是不同类的样本之间,都需要这样处理)。具体操作就是再把所有这些score相等的样本 的rank取平均。然后再使用上述公式。
代码:采用第一种方法计算:
#include参考
https:// blog.csdn.net/pzy 41/article/details/
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/210593.html原文链接:https://javaforall.net


