
MixMatch:半监督学习
- 1 摘要
- 2 介绍
- 3 已有相关工作
-
- 3.1 Consistency Regularization 一致性正则化
- 3.2 Entropy Minimization/ Entropy regularization [熵最小化](https://blog.csdn.net/u0/article/details/)
- 3.3 Traditional regularization 传统正则化
- 4 MixMatch
1 摘要
半监督学习已被证明是利用未标记数据减轻对大型标记数据集依赖的一个强大范例。在这项工作中,我们结合了目前半监督学习的主流方法,提出了一种新的算法,MixMatch,它利用MixUp方法猜测数据中的低熵标签(low-entropy labels),这些数据包括了数据扩充之后的未标记样本和混合数据(未标记和标记的混合数据)。我们展示了MixMatch在许多数据集和标记的数据量上获得了大量最新的结果。例如,在包含250个标签的CIFAR-10上,我们将错误率降低了4倍(从38%降低到11%),在STL-10上降低了2倍。我们还演示了MixMatch如何帮助实现对差异隐私的更精确的隐私交换。最后,我们进行消融研究,梳理出哪些成分的混合匹配是最重要的成功
2 介绍
最近在训练大型深度神经网络方面取得的成功,在一定程度上要归功于大型标记数据集的存在。然而,对于许多学习任务来说,收集标记数据是昂贵的,因为它必然涉及到专家知识。这一点或许可以从医学任务中得到最好的说明,在医学任务中,使用昂贵的机械和标签进行测量是耗时分析的结果,通常来自多位人类专家的结论。此外,数据标签可能包含被认为是私有的敏感信息。相比之下,在许多任务中,获取未标记的数据要容易得多,也便宜得多
半监督学习(SSL)通过允许模型利用未标记的数据,试图在很大程度上减轻对标记数据的需求。最近的许多半监督学习方法都增加了一个损失项,这个损失项是在未标记的数据上计算的,它鼓励模型更好地泛化至到不可见的数据中。在最近的许多工作中,这个损失项可分为三类:
熵最小化——它鼓励模型对未标记的数据输出有信心的预测;
一致性正则化——当模型的输入受到扰动时,它鼓励模型产生相同的输出分布
泛型正则化——这有助于模型很好地泛化,避免对训练数据的过度拟合。
在本文中,我们引入了MixMatch,这是一种SSL算法,它引入了单个损失,将这些主要方法优雅地结合到半监督学习中。与之前的方法不同,MixMatci rget一次获得所有属性,我们发现它有以下好处:
- 实验表明,MixMatch在所有标准的图像基准测试(第4.2节)上都获得了最先进的结果,例如,在包含250个标签的CIFAR-10上获得了11.08%的错误率(其次是最佳方法,获得了38%的错误率);
- 此外,模型简化测试中表明,MixMatch 的效果比各个trick 混合之和要好;
- 我们在第4.3节中演示了MixMatch对于不同的私有学习是有用的,使PATE框架[34]中的学生能够获得最新的结果,同时增强所提供的隐私保障和所达到的准确性。
简而言之,MixMatch为未标记的数据引入了一个统一的损失项,它无缝地减少了熵,同时保持一致性,并保持与传统正则化技术的兼容性。
3 已有相关工作
为了设置MixMatch,我们首先介绍SSL的现有方法。我们主要关注那些目前最先进的和MixMatch的基础;有很多关于SSL技术的文献我们在这里没有讨论:
- transductive
- graph-based methods
- generative modeling
下面,我们将引用一个通用模型
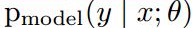

y是输入x的分类类别的标签
x是输入
theta 是参数
3.1 Consistency Regularization 一致性正则化
在监督学习中,一种常见的正则化技术是数据增强,它应用于对输入进行转换,同时假定这种转换不影响类语义分类。例如,在图像分类中,输入图像通常会发生弹性变形或添加噪声,这可以在不改变图像标签的情况下显著改变图像的像素内容。粗略地说,这可以通过近乎无限生产新数据或者说修改数据,人为地扩大了训练集的大小。一致性正则化将数据增强应用于半监督学习,它利用了这样一种思想 : 即使对未标记的示例进行了增强,分类器也应该输出相同的类分布。更正式地说,一致性正则化强制未标记的示例x应该与Augment(x)归为一类,其中Augment©是一个随机数据增强函数,类似于随机空间平移或添加噪声。
3.2 Entropy Minimization/ Entropy regularization 熵最小化
在许多半监督学习方法中,一个常见的基本假设是分类器的决策边界不应该通过边缘数据分布的高密度区域。实现这一点的一种方法是要求分类器对未标记的数据输出低熵预测。
- 这是在显式地通过简单地添加一个损失项来实现的,该损失项使Pmodel(y | x;0)未标注数据,这种形式的熵最小化与VAT相结合,得到了更强的结果 (VAT)
- ‘Pseudo-Label 伪标签’ 通过对未标记数据的高置信度预测构建硬标签,并在标准的交叉熵损失中使用这些硬标签作为训练目标,隐式地实现了熵的最小化 (Pseudo-Label, 2013) Pseudo-Label:深度学习中一种简单有效的半监督方法
- MixMatch还通过对未标记数据的目标分布使用“锐化”函数隐式地实现熵的最小化 (sharpen)
3.3 Traditional regularization 传统正则化
4 MixMatch
4.1 数据增强 Data Augmentation
4.2 标签猜测 Label Guessing
4.3 Sharpening 锐化
4.4 MixUp
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/211933.html原文链接:https://javaforall.net


