
[机器学习]决策树算法的MATLAB实现
这是一篇关于决策树算法的MATLAB实现的文章,也是我的课堂实验,学习的书籍为西瓜书。此文章包含树的建立(使用信息增益,基尼指数),绘图,预测以及剪枝(后剪枝),部分代码为老师提供。文章中所有的代码以及老师提供的代码以及实验的要求都在以下连接,需要可以自取。应该说,最好就是跟着实验要求去做,然后不懂或者看不明白再来看这里面的代码,应该会对决策树有更加深刻的了解。假如大家对决策树有什么不了解,可以问我,我会尽量解答(当然我属实能力有限,毕竟才开始学,一起努力吧,冲冲冲)当然代码略微杂乱。而且matlab现在似乎提供了决策树等算法的生成包,大家可以自行查略,本文并不涉及。以下为正文
链接:https://pan.baidu.com/s/1ioCVZTNyCZiD0GM9Vy3L4w 提取码:v432 当然我的csdn资源中应该也有这个资源(写完这个应该就会去上传吧) 大家如果觉得还不错可以支持一下 一 .内容
- 基于 西瓜数据集2.0 的ID3决策树算法实现
数据集watermelon.mat,来自教材中的西瓜数据集2.0,共有18个样本数据。实验中,选取其中的16个样本构成训练集,其余2个样本构成测试集。基于ID3算法采用训练样本构造决策树,并简单绘出生成的决策树。最后,测试该决策树对测试样本的类别划分情况。
- 基于 Breast Cancer癌症数据集 分析ID3决策树的分类精度
数据集breastcancer.mat中,有277个样本数据,每个数据有9个属性特征以及一个类别标签。基于前述构造ID3决策树的算法程序,试采用10次10折交叉验证法评估ID3决策树模型在此数据集上的分类精度(注:分类精度的度量方法参见教材P29公式2.5)。
(这一部分我的最后结果是90的正确率还是挺开心的嘿嘿。
(不剪枝的话应该66左右。剪枝nb!
二.具体实现
基于西瓜数据集2.0的ID3决策树算法实现
(一)要求.
数据集watermelon.mat,来自教材中的西瓜数据集2.0,共有18个样本数据。实验中,选取其中的16个样本构成训练集,其余2个样本构成测试集。基于ID3算法采用训练样本构造决策树,并简单绘出生成的决策树。最后,测试该决策树对测试样本的类别划分情况。
(二)过程
- 主函数:导入数据集,划分训练集与测试集,构造决策树 Main_DecisionTree.m
- 子函数ID3():基于ID3算法构造决策树 ID3.m
- 子函数chooseFeature():选择信息增益最大的属性特征 chooseFeature.m
function bestFeature=chooseFeature(dataset,~) % 选择信息增益最大的属性特征 %数据预处理 [N,M]=size(dataset); %样本数量N M=M-1; %特征个数M y=strcmp(dataset(:,M+1),dataset(1,M+1)); %标签y(以第一个标签为1) x=dataset(:,1:M); %数据x gain = (1:M); %创建一个数组,用于储存每个特征的信息增益 %bestFeature; %最大信息增益的特征 Ent_D=calShannonEnt(y); %当前信息熵 %计算信息增益 for i=1:M % 计算第i种属性的增益 temp=tabulate(x(:,i)); value=temp(:,1); %属性值 count=cell2mat(temp(:,2)); %不同属性值的各自数量 Kind_Num=length(value); %取值数目 Ent=zeros(Kind_Num,1); % i属性下 j取值的信息熵 for j=1:Kind_Num % 在第j种取值下正例的数目 Ent(j)= calShannonEnt( y(strcmp(x(:,i),value(j))) ); end gain(i)=Ent_D-count'/N*Ent; end %随机挑选一个最大值 max_gain=find(gain==max(gain)); choose=randi(length(max_gain)); bestFeature=max_gain(choose); %%%%============================================ end temp=tabulate(x(:,i)); value=temp(:,1); %属性值 count=cell2mat(temp(:,2)); %不同属性值的各自数量 这里以此对每一个属性取值调用calShannonEnt函数来计算信息熵
Ent(j)= calShannonEnt( y(strcmp(x(:,i),value(j))) ); max_gain=find(gain==max(gain)); choose=randi(length(max_gain)); bestFeature=max_gain(choose); 这是为了应对当有多个最大的属性特征时的情况,这里我解决的方法是随机从中随机挑选出一个作为最大值,所以也因此,虽然输入数据相同,但训练输出的树也会因此而可能发生不同。
4.子函数calShannonEnt():计算信息熵 calShannonEnt.m
function shannonEnt = calShannonEnt(y) % 计算信息熵 % y对应的标签,为1或0,对应正例与反例 N=length(y); %标签长度 P_T=sum(y)/N; %正例概率 P_F=(N-sum(y))/N; %反例概率 if(P_T==0||P_F==0) %使得p*log2p为0 shannonEnt = 0; return end shannonEnt=-(P_T*log2(P_T)+P_F*log2(P_F)); %信息熵 end 因为传入的为[1,0]的逻辑数组,所以正例可以直接使用sum/N来计算。后面根据信息熵的约定当p=0信息熵p*log2p为0,所以加入了中间的一句判断,来返回该情况
对训练样本进行类别划分的代码如下: %---------------------------------------------- y_test=predict(x_test,mytree,labels); fprintf('测试样本的分类标签为:'); disp(y_test); %----------------------------------------------- (三)实验结果
决策树图像:
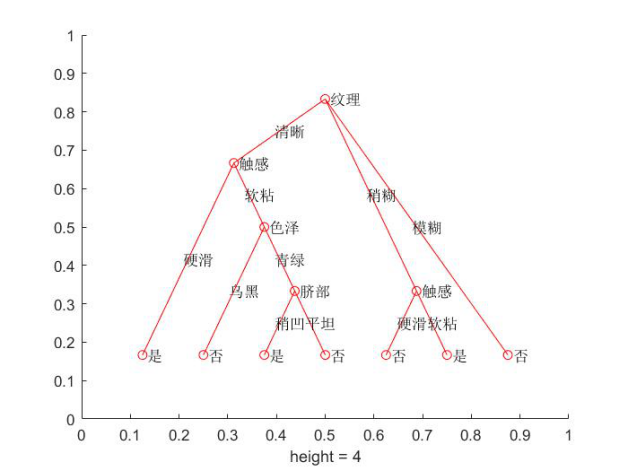

输出:
测试样本的分类标签为: '否' '否' 基于Breast Cancer数据集分析ID3决策树的分类精度
(一)要求
数据集breastcancer.mat中,有277个样本数据,每个数据有9个属性特征以及一个类别标签。基于前述构造ID3决策树的算法程序,试采用10次10折交叉验证法评估ID3决策树模型在此数据集上的分类精度(注:分类精度的度量方法参见教材P29公式2.5)。
(二)实验过程
1.predict函数的修改
在predict中,因为数据集的标签不能包含所有标签,所以当测试集中出现了数据集中没有的标签时,将无法进行预判而返回空数组,比如年龄这一个属性在训练集中没有20-39这个属性但出现在测试级中,将会无法返回预测标签。所以对其进行更改为:
hasKeys=0; keys = node.keys(); for i = 1:length(keys) key = keys{i}; c = char(feature); if strcmp(key,c) queue=[queue,{node(key)}]; %队列变成该节点下面的节点 hasKeys=1; end end if(~hasKeys) key = keys{randi(length(keys))}; queue=[queue,{node(key)}]; end 即随机选取一个属性值进行预判,接下去进行预测
% breastcancer数据集 %-----------------数据读取---------------------- clear clc load('breastcancer.mat') size_data = size(breastcancer); %breastcancer 为导入工作台的数据 %-------------10次10折交叉验证------------------- k_time=10; crossValidation_time=10; y_lable=breastcancer(2:size_data(1),size_data(2)); T_P=zeros(k_time,crossValidation_time); for i=1:crossValidation_time %分为训练集和测试集(10折), y_1=find(strcmp(y_lable(:),y_lable(1)));%与第一个标签相同的为一层次 y_2=find(~strcmp(y_lable(:),y_lable(1)));%其余为另一个层次 y_1_length=length(y_1); y_2_length=length(y_2); y_1_perNum=floor(y_1_length/k_time); y_2_perNum=floor(y_2_length/k_time); y_1_randIndex=randperm(y_1_length); y_2_randIndex=randperm(y_2_length); D_index=zeros(y_1_perNum+y_2_perNum,k_time); %D中存放了10组数据索引 for j=1:k_time %有数据被丢弃 D_index(:,j)=[... y_1(y_1_randIndex(y_1_perNum*(j-1)+1:y_1_perNum*j));... y_2(y_2_randIndex(y_2_perNum*(j-1)+1:y_2_perNum*j))]; end D_index=D_index+1; perNum_D=y_1_perNum+y_2_perNum; %训练10折交叉验证 for k=1:k_time %获取此时的数据集以及测试集 x_train = breastcancer(... [1; reshape(D_index(:,1:k-1),[],1);... reshape(D_index(:,k+1:k_time),[],1)],:) ; %这里加上了属性标签行 x_test = breastcancer(D_index(:,k),:); %选择最后两个当测试集 %训练 size_data = size(x_train); dataset = x_train(2:size_data(1),:); %纯数据集 labels = x_train(1,1:size_data(2)-1); %属性标签 %生成决策树 mytree = ID3_2(dataset,labels); %预测测试集标签并计算精度 y_test=predict_2(x_test(:,1:end-1),mytree,labels); T_P(i,k)=sum(strcmp(y_test',x_test(:,end)))/perNum_D; end end %----------------结果输出------------------------- fprintf('10次10折交叉验证的精度结果为:\n'); for i=1:10 fprintf('第%d次:%f\n',i,mean(T_P(i,:))); fprintf('\t%f\t%f\t%f\t%f\t%f\n',T_P(i,1:5)); fprintf('\t%f\t%f\t%f\t%f\t%f\n',T_P(i,6:10)); end fprintf('平均精度为:%d\n',mean(mean(T_P))); (三)实验结果
10次10折交叉验证的精度结果为: 第1次:0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 第2次:0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 第3次:0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 第4次:0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 第5次:0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 第6次:0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 第7次:0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 第8次:0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 第9次:0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 第10次:0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. (四)改进
1.使用基尼指数来作为选择指标
这里与之前的计算信息增益基本相同,最后选择的指标改为了最小的而非最大
function bestFeature=chooseFeatureGini(dataset,~) % 选择基尼指数最小的属性特征 %数据预处理 [N,M]=size(dataset); %样本数量N M=M-1; %特征个数M y=strcmp(dataset(:,M+1),dataset(1,M+1)); %标签y(以第一个标签为1) x=dataset(:,1:M); %数据x Gini_index = zeros(1,M); %创建一个数组,用于储存每个特征的信息增益 %bestFeature; %最大基尼系数的特征 %计算基尼指数 for i=1:M % 计算第i种属性的基尼指数 temp=tabulate(x(:,i)); value=temp(:,1); %属性值 count=cell2mat(temp(:,2)); %不同属性值的各自数量 Kind_Num=length(value); %取值数目 Gini=zeros(Kind_Num,1); % i属性下 j取值的基尼指数 for j=1:Kind_Num % 在第j种取值下正例的数目 Gini(j)= getGini( y(strcmp(x(:,i),value(j))) ); end Gini_index(i)=count'/N*Gini; end %随机挑选一个最小值 min_GiniIndex=find(Gini_index==min(Gini_index)); choose=randi(length(min_GiniIndex)); bestFeature=min_GiniIndex(choose); end 用于计算基尼指数的代码:
function Gini = getGini(y) % 计算基尼系数 % y对应的标签,为1或0,对应正例与反例 %%%%%%======================================== N=length(y); %标签长度 P_T=sum(y)/N; %正例概率 P_F=1-P_T; %正例概率 Gini=1-P_T*P_T-P_F*P_F; %基尼系数 %%%%%%===================================== end 在做这部分改动之后,10次10折交叉验证精度影响较小,基本与之前相同。
size_data = size(dataset); classList = dataset(:,size_data(2)); %%属性集为空,找最多数 temp=tabulate(classList); value=temp(:,1); %属性值 count=cell2mat(temp(:,2)); %不同属性值的各自数量 index=find(max(count)==count); choose=index(randi(length(index))); nodeLable = char(value(choose)); if size_data(2) == 1 myTree = nodeLable; return end leaf('nodeLabel')= nodeLable; 在 string(class(node))=="containers.Map" %的情况时加入 %除去nodelable标签(不影响检测) keys = node.keys(); index=find(strcmp(keys,'nodeLabel')); if(~isempty(index)) keys=[keys(1:(index-1)),keys((index+1):end)]; end 这修改后,10次10折交叉验证精度比之前的65%-66%有小幅度提升,在68%-69%左右
%去除完全相同的属性,避免产生没有分类结果的节点 choose=ones(1,size_data(2)); for i=1:(size_data(2)-1) featValues = dataset(:,i); uniqueVals = unique(featValues); if(length(uniqueVals)<=1) choose(i)=0; end end labels=labels((choose(1:size_data(2)-1))==1); dataset=dataset(:,choose==1); function [correct,tree_pruning] = pruning(x_V,tree,feature_list) %-----------------剪枝------------------------- %correct:返回的数据集的预测值正确程度数组,1为预测正确 %tree_pruning:剪枝后的数组 %x_V:训练集 %tree:剪枝前的树 %feature_list:训练集的标签 if(string(class(tree))~="containers.Map") %达到叶节点,计算标签与当前数据的真实标签的异同 %将结果保存在correct数组中 correct=strcmp(x_V(:,end),tree)'; tree_pruning=tree;%返回原本的节点 return; else size_data = size(x_V); labels=feature_list; %数据的属性 Feature=char(tree.keys); %当前节点的属性 FeatureIndex=strcmp(labels,Feature);%节点属性在所有属性中的索引 FeatureValue=x_V(:,FeatureIndex); %所有属性 x_V=x_V(:,logical([~FeatureIndex,1])); %删除该特征 feature_list=feature_list(~FeatureIndex); theTree = containers.Map;%新的节点以及边 theLeaf = containers.Map; leaf=tree(Feature);%原本的叶子节点 keys=leaf.keys; %获取属性的取值 %除去nodelable标签(不影响检测) index=find(strcmp(keys,'nodeLabel')); if(~isempty(index)) keys=[keys(1:(index-1)),keys((index+1):end)]; end correct=[]; %数据将包含目前数据预测的正确与否,为0-1数组 for i=1:length(keys) value=keys{i}; x_V_value=x_V(strcmp(FeatureValue,value),:); %删除拥有特征的数量 if(~isempty(x_V_value)) %数据集里有该取值,计算预测结果正确与否 [correct_per,theLeaf(value)] = pruning(x_V_value,leaf(value),feature_list); correct=[correct,correct_per]; else %数据集里没有该取值,保留原本的节点 theLeaf(value)=leaf(value); end end theLeaf('nodeLabel')= char(leaf('nodeLabel'));%获取之前的节点 theTree(Feature) = theLeaf; acc = sum(correct)/length(correct);%原本的精度 acc_pruning = strcmp(x_V(:,end),leaf('nodeLabel'))/size_data(1);%不划分的精度 if(acc<=acc_pruning) %假如不划分的精度更高,那么选取原本训练时最多的标签 tree_pruning= char(leaf('nodeLabel')); else %保留树 tree_pruning=theTree; end end end if k~=k_time x_train = breastcancer(... [1; reshape(D_index(:,1:k-1),[],1);... reshape(D_index(:,k+2:k_time),[],1)],:) ; %这里加上了属性标签行 else x_train = breastcancer([1; reshape(D_index(:,2:k-1),[],1)],:) ; %这里加上了属性标签行 end x_valid = breastcancer(D_index(:,k),:); %选择验证集 x_test = breastcancer(D_index(:,mod(k+1,k_time)+1),:); %选择测试集 (2)用剪枝后的数据集去验证
%剪枝 [correct,tree_pruning] = pruning(x_valid,mytree,labels); %---------------------------------------------- y_test=predict_2(x_test(:,1:end-1),tree_pruning,labels); T_P(i,k)=sum(strcmp(y_test',x_test(:,end)))/perNum_D; %----------------------------------------------- (五)改进结果
上述所有的改进之后,决策树的精度得到了很大的提升,在89% 90%左右
10次10折交叉验证的精度结果为: 第1次:0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 第2次:0. 0. 0. 0. 0. 0. 0. 0. 0. 1.000000 0. 第3次:0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 第4次:0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.000000 第5次:0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 第6次:0. 0. 0. 0. 0. 1.000000 0. 0. 0. 0. 0. 第7次:0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 第8次:0. 0. 0. 0. 0. 1.000000 1.000000 0. 0. 0. 0. 第9次:0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 第10次:0. 0. 0. 0. 0. 0. 0. 0. 0. 1.000000 0. 平均精度为:0. END
到此结束啦,谢谢你能看到这,感谢。你有自己试着去实现吗?你的精度又是多少呢?886
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/213158.html原文链接:https://javaforall.net


