
前言:
该文属于安卓源码探究专栏中的文章,专栏所有文章清单链接如下,欢迎大家阅读。
安卓源码探究
一、Handler机制介绍
1.1 Handler是什么?
Handler是安卓中很常用的一种机制,其主要用于线程之间的通信。
1.2 为什么要了解Handler原理?
之前我在一个群里面聊天,说面试经常会问到handler,然后就被喷了,说现在都是MVVM,ViewBinding一类的架构,谁还用handler呀。确实,现在安卓上面封装的框架越来越多,也让我们使用起来越来越轻松,使用Handler的场景也会越来越少。但是使用的少,不代表没有用。现有的这些框架,甚至可预见的未来框架,都是基于Handler机制的。
打一个比方,我们普通人开车,也许只要会开就行,不必了解汽车的原理。但是如果你想成为一个赛车手,那么对汽车运行的机制和原理,还是要有一定的了解的。
最后,了解handler原理有哪些好处呢?
1.handler机制很经典,这种我们平常敲代码的过程中也可以视场景使用。
2.handler其实除了普通的同步消息,还有屏障消息和异步消息的,我们也可以视场景去使用。
3.handler还提供了闲时机制IdelHandler。
4.通过handler可以帮助我们排查到底是哪里的代码导致卡顿。
上面的这些点,后面文章中都会有详细的讲解。
1.3 Handler对于面试中的作用?
同时Handler也是面试当中经常会被问到的一种安卓机制。
我总结了一下,大约有六个点会被高频问到,这六个技术点特意用红字标注,属于面试中很容易被问到的技术点。
例如:技术点1
二、Handler原理概述
如下图所示:安卓中Handler的机制是子线程中获取一个Handler对象,通过这个Handler对象像MessageQueue中发送任务。主线程中开启一个无限死循环,不断的从MessageQueue中取Message任务,如果取到了就执行Messagez中的任务,如果没有取到则进入休眠状态。
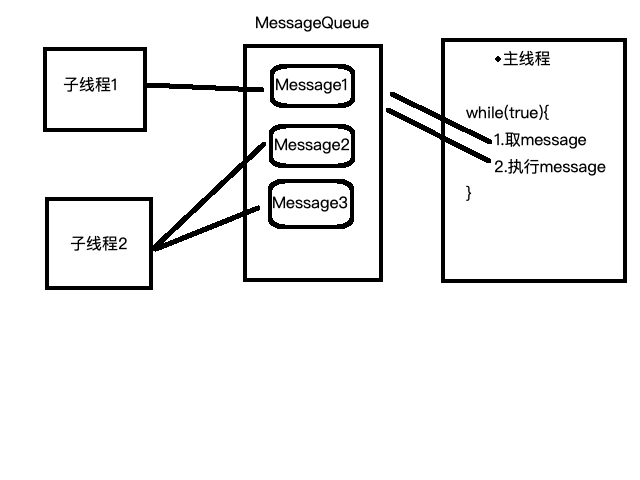

几个涉及到的重要的对象
Handler:一般要在主线程中创建,持有一个主线程的Looper,负责向主线程进行message分发。
Message:可以理解为task,任务执行的单元。
MessageQueue:里面是一个单链表,单链表存储Message任务。
Looper:负责处理Message任务,其loop方法在主线程中开启无限循环。
三、Message添加的流程
3.1添加Meesage的写法
我们可以看到很多种添加message的写法,其实最终都是调用了sendMessageDelayed方法。
一般写法主要有以下几种:
写法一:sendMessageDelayed(Message msg, long delayMillis)
public final boolean sendMessageDelayed(@NonNull Message msg, long delayMillis) { if (delayMillis < 0) { delayMillis = 0; } return sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis); }写法二:sendMessage(Message msg)
public final boolean sendMessage(@NonNull Message msg) { return sendMessageDelayed(msg, 0); }其实是调用了sendMessageDelayed方法。
写法三:
mHandler.post(new Runnable() { @Override public void run() { //do something } });其实我们点进去看一下,
sendMessageDelayed(getPostMessage(r), 0);再看getPostMessage方法:
private static Message getPostMessage(Runnable r) { Message m = Message.obtain(); m.callback = r; return m; }好吧。其实也是构建一个Message,然后sendMessage出去。
3.2 sendMessageDelayed方法
public final boolean sendMessageDelayed(@NonNull Message msg, long delayMillis) { if (delayMillis < 0) { delayMillis = 0; } return sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis); }调用sendMessageAtTime时传入的第二个参数为执行时间。
这个执行时间是当前时间+延迟时间算出来的。
这里有涉及到技术点1:修改手机时间会不会影响Message的执行,当前使用使用的是SystemClock.uptimeMillis(),这个指的是手机开机后系统非深度休眠时间,而不是手机时间。所以手机上修改当前时间是不会影响Message执行的。一般我们也可以通过这个值来获取手机开机多久。
3.3 sendMessageAtTime
1.sendMessageAtTime里面就做一个MessageQueue的判断。
public boolean sendMessageAtTime(@NonNull Message msg, long uptimeMillis) { MessageQueue queue = mQueue; if (queue == null) { RuntimeException e = new RuntimeException( this + " sendMessageAtTime() called with no mQueue"); Log.w("Looper", e.getMessage(), e); return false; } return enqueueMessage(queue, msg, uptimeMillis); }3.4 enqueueMessage方法
private boolean enqueueMessage(@NonNull MessageQueue queue, @NonNull Message msg, long uptimeMillis) { msg.target = this; msg.workSourceUid = ThreadLocalWorkSource.getUid(); if (mAsynchronous) { msg.setAsynchronous(true); } return queue.enqueueMessage(msg, uptimeMillis); }把Message加入到queue里
3.5 enqueueMessage方法
1.这里面代码看起来有点多和乱。但是核心逻辑就是按照执行时间从前到后的纬度,把当前的message节点插入到单链表当中。技术点2:链表是按照什么方式来排列的。执行时间顺序
2.Message中有一个参数when,这里会在被添加到链表的时候赋值,记录的就是执行时间。
3.同时通过nativeWake唤醒休眠。为何休眠,下面第四章时会讲到,一般无待执行Message时会进入休眠释放CPU资源。
boolean enqueueMessage(Message msg, long when) { if (msg.target == null) { throw new IllegalArgumentException("Message must have a target."); } synchronized (this) { if (msg.isInUse()) { throw new IllegalStateException(msg + " This message is already in use."); } if (mQuitting) { IllegalStateException e = new IllegalStateException( msg.target + " sending message to a Handler on a dead thread"); Log.w(TAG, e.getMessage(), e); msg.recycle(); return false; } msg.markInUse(); msg.when = when; Message p = mMessages; boolean needWake; if (p == null || when == 0 || when < p.when) { // New head, wake up the event queue if blocked. msg.next = p; mMessages = msg; needWake = mBlocked; } else { // Inserted within the middle of the queue. Usually we don't have to wake // up the event queue unless there is a barrier at the head of the queue // and the message is the earliest asynchronous message in the queue. needWake = mBlocked && p.target == null && msg.isAsynchronous(); Message prev; for (;;) { prev = p; p = p.next; if (p == null || when < p.when) { break; } if (needWake && p.isAsynchronous()) { needWake = false; } } msg.next = p; // invariant: p == prev.next prev.next = msg; } // We can assume mPtr != 0 because mQuitting is false. if (needWake) { nativeWake(mPtr); } } return true; }至此,message就插入到MessageQueue当中,插入流程完成。
四、Message被执行的流程
4.1 调用Looper.prepare()与当前线程进行绑定。
一般我们是不需要调用prepare方法的,因为应用启动后,在ActivityThread的main方法中,已经帮我们调用了Looper.prepare方法了。
private static void prepare(boolean quitAllowed) { if (sThreadLocal.get() != null) { throw new RuntimeException("Only one Looper may be created per thread"); } sThreadLocal.set(new Looper(quitAllowed)); }prepare的核心逻辑就是与当前线程进行绑定,通过ThreadLocal。保证一个Looper只会绑定唯一的一个Thread。
4.2 Looper.loop启动无限循环
调用Looper.loop方法,启动无限循环。这里会做一个检查,如果Looper没有绑定到当前线程,则会抛出异常。
public static void loop() { final Looper me = myLooper(); if (me == null) { throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread."); } ...不重要代码忽略 for (;;) { //启动无限循环 if (!loopOnce(me, ident, thresholdOverride)) { return; } } }4.3 获取到message去尝试执行
1.会调用MessageQueue.next()里面尝试获取message,如果获取不到会被阻塞。具体我们下一章节分析。
2.如果获取不到消息并且返回了,这时说明应用处于退出状态了,所以循环也关闭。
3.msg.target.dispatchMessage() 转交给Handler去真正的处理消息,由于当前的执行线程是主线程,所以dispatchMessage里面执行的回调也是在主线程。
4.我们可以看到代码中有logging进行输入打印,这一点对我们性能监控很有帮助,具体我们第七章节讲解。
5.msg.recycleUnChecked标记msg已被使用,进入可复用状态。
4.4 dispatchMessage执行message
这里有两种回调的方式,
方式一直接执行Message中的callBack;
方式二自定义Handler,重写其handleMessage方法。
这里我们可以明显看到,callBack的优先级会更高。这是技术点3:CallBack和handleMessage哪个会优先被执行
public void dispatchMessage(@NonNull Message msg) { if (msg.callback != null) { handleCallback(msg); } else { if (mCallback != null) { if (mCallback.handleMessage(msg)) { return; } } handleMessage(msg); } }handleCallBack中就是直接通过
message.callback.run();执行Message的runnable任务。PS:run()是Runnable接口中定义的方法
五、MessageQueue.next()取消息
先看代码,具体分为下面的几个环节。
Message next() { ... for (;;) { if (nextPollTimeoutMillis != 0) { Binder.flushPendingCommands(); } nativePollOnce(ptr, nextPollTimeoutMillis);//4.1 nativePollOnece synchronized (this) { // Try to retrieve the next message. Return if found. final long now = SystemClock.uptimeMillis(); Message prevMsg = null; Message msg = mMessages; ...屏障消息相关代码先忽略 if (msg != null) {//4.2 寻找可用message if (now < msg.when) { // Next message is not ready. Set a timeout to wake up when it is ready. nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE); } else { // Got a message. mBlocked = false; if (prevMsg != null) { prevMsg.next = msg.next; } else { mMessages = msg.next; } msg.next = null; if (DEBUG) Log.v(TAG, "Returning message: " + msg); msg.markInUse(); return msg; } } else { // No more messages. nextPollTimeoutMillis = -1; } ...idelHandler相关代码先忽略 } }5.1 nativePollOnce方法
这是一个native方法,阻塞的。我们上面所说的CPU休眠也就是通过nativePollOnce这个机制来实现的。调用这个方法的时候,CPU资源会被释放掉,直到被外界唤醒。底层的实现原理对应的是linux的epoll机制,这篇文章我们就不详细去分析了。我们只要知道其方法的功能就可以了。
nativePollOnce有两个参数,ptr和timeoutMillis
ptr可以理解为一个native标记的唯一值,用来识别绑定线程的。
timeoutMillis是超时时间。主要分为三种-1,0,>0。
=-1的时候是处于无限阻塞的状态,除非被外界唤醒。
=0的时候不会阻塞,会立马执行。
>0时会阻塞对应的时间,然后释放阻塞状态。
PS:nativePollOnce的native实现其实和安卓层有一些类似,也有一个阻塞的循环队列的。底层的实现机制是epoll,由于native层不是本文的核心,这里就不扩展介绍了,感兴趣的同学可以留言,我
5.2 遍历链表,寻找可以用的message
1.因为链表我们插入时是按照执行时间去插入的,所以最先执行的Message一定在链表的最头部;
2.首先获取一下当前系统非休眠状态时间;
3.首先尝试获取链表的头部,那么说明链表中无数据。则把nextPollTimeoutMillis赋值为-1,下一个循环时,就会进入无限阻塞状态,直接被唤醒。这里对应的就是2.5 章节时讲到的native唤醒机制。
4.如果头节点不为空,则判断其执行时间和当前时间做比较;
5.如果其执行时间小于当前时间,则计算差值nextPollTimeoutMillis。并且会跳出此次Message选择流程。并且在下一次循环的时候,nativePollOnce会使用该值休眠对应的时间。保证休眠时间一到,正好到了头节点的执行时间。
6.如果其执行时间是否大于当前时间,则表明该节点是可以被执行的。把头节点改成下一级节点。并且通过Message.markInUse标记当前Message已经被使用。
7.返回上一步查到的message对象
五、异步消息/屏障消息
技术点4:屏障异步消息的实现机制
1 屏障消息其实就是target为空的Message消息。
2 异步消息一定要搭配屏障消息来使用。
3 如果头节点为屏障消息时,则会从消息链表中从前向后依次寻找异步消息,找到异步消息则跳出循环。
4 并且从链表中移除当前的异步节点,并且把异步节点的前后两个节点关联起来。
5 这里要注意,头部节点仍然是屏障消息没有被移除。所以正常消息仍然是不会被执行的。
if (msg != null && msg.target == null) { // Stalled by a barrier. Find the next asynchronous message in the queue. do { prevMsg = msg;//如果时异步消息,则保存保存消息之前的那条消息,方便后面关联 msg = msg.next; } while (msg != null && !msg.isAsynchronous()); } if (msg != null) { if (now < msg.when) { // Next message is not ready. Set a timeout to wake up when it is ready. nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE); } else { // Got a message. mBlocked = false; if (prevMsg != null) { prevMsg.next = msg.next;//把异步消息的next赋值给前面那个节点的next } else { mMessages = msg.next; } msg.next = null; if (DEBUG) Log.v(TAG, "Returning message: " + msg); msg.markInUse(); return msg; } } else { // No more messages. nextPollTimeoutMillis = -1; }六、IdleHandler
技术点5:IdelHandler执行时机
6.1 IdleHandler介绍
顾名思义,就是闲时任务。当前没有要被执行的Message时,则会触发执行IdelHandler,我们一般可以把那些需要在主线程执行,但是优先级不高的任务放在IdelHandler里面执行,比如预加载下一个页面,二屏加载等等。
6.2 IdleHandler何时触发
看代码我可以知道,获取Message的时候,如果没有获取到Message时,则会进入执行IdleHandler的流程。
Message next() { ...代码省略 for (;;) { if (DEBUG) Log.v(TAG, "Returning message: " + msg); msg.markInUse(); return msg; //如果取到了消息则返回 } } else { // No more messages. nextPollTimeoutMillis = -1; } ... //如果没有取到消息,则会执行下面的逻辑 // If first time idle, then get the number of idlers to run. // Idle handles only run if the queue is empty or if the first message // in the queue (possibly a barrier) is due to be handled in the future. if (pendingIdleHandlerCount < 0 && (mMessages == null || now < mMessages.when)) { pendingIdleHandlerCount = mIdleHandlers.size(); } if (pendingIdleHandlerCount <= 0) { // No idle handlers to run. Loop and wait some more. mBlocked = true; continue; } if (mPendingIdleHandlers == null) { mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)]; } mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers); } // Run the idle handlers. // We only ever reach this code block during the first iteration. for (int i = 0; i < pendingIdleHandlerCount; i++) { final IdleHandler idler = mPendingIdleHandlers[i]; mPendingIdleHandlers[i] = null; // release the reference to the handler boolean keep = false; try { keep = idler.queueIdle(); } catch (Throwable t) { Log.wtf(TAG, "IdleHandler threw exception", t); } if (!keep) { synchronized (this) { mIdleHandlers.remove(idler); } } } // Reset the idle handler count to 0 so we do not run them again. pendingIdleHandlerCount = 0; // While calling an idle handler, a new message could have been delivered // so go back and look again for a pending message without waiting. nextPollTimeoutMillis = 0; } }6.3 IdleHandler执行流程
IdleHandler可以有多个,在MeesageQueue中由mIdelHandlers存储每执行时,转换为数组依次执行。
pendingIdleHandlerCount = mIdleHandlers.size(); mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers); for (int i = 0; i < pendingIdleHandlerCount; i++) { final IdleHandler idler = mPendingIdleHandlers[i]; mPendingIdleHandlers[i] = null; // release the reference to the handler boolean keep = false; try { keep = idler.queueIdle(); } catch (Throwable t) { Log.wtf(TAG, "IdleHandler threw exception", t); } if (!keep) { synchronized (this) { mIdleHandlers.remove(idler); } } }这里要注意一点,IdleHandler的回调只会执行一次,执行完成后会被移除。
七、Message执行监听
技术点6:如何对主线程卡顿问题进行监控
7.1 触发原理
3.3章节的时候,我们有提到logging这个对象。我们在回头看一下代码,这里我们很清楚的看到,logging会在message执行前和执行后分别调用。那这两次打印之间的时间,就可以认为是Message中回调的执行时间。
private static boolean loopOnce(final Looper me, final long ident, final int thresholdOverride) { ...省略代码 final Printer logging = me.mLogging; if (logging != null) { logging.println(">>>>> Dispatching to " + msg.target + " " + msg.callback + ": " + msg.what); } ...省略代码 try { msg.target.dispatchMessage(msg); if (observer != null) { observer.messageDispatched(token, msg); } dispatchEnd = needEndTime ? SystemClock.uptimeMillis() : 0; } catch (Exception exception) { ...省略代码 if (logging != null) { logging.println("<<<<< Finished to " + msg.target + " " + msg.callback); } }7.2 使用方式
我们看一下logging对应的Printer类,其实就是一个接口,
public interface Printer { / * Write a line of text to the output. There is no need to terminate * the given string with a newline. */ void println(String x); } 并且我们发现logging是允许我们主动去设置的 。使用时取的是Looper.mLogging对象。
而setMessageLogging方法正好是设置mLogging的。
public void setMessageLogging(@Nullable Printer printer) { mLogging = printer; }所以我们只要创建一个Printer对象,然后注册到Looper里,那么通过两次回调的时间,就可以判断哪个Meesage执行超时了。如下代码就可以监控主线程所有Message消息执行超过100毫秒的场景。
//声明Printer对象 private Printer printer = new Printer() { @Override public void println(String it) { long currentTimeMillis = System.currentTimeMillis(); //其实这里应该是一一对应判断的,但是由于是运行主线程中,所以Dispatching之后一定是Finished,依次执行 if (it.contains("Dispatching")) { lastFrameTime = currentTimeMillis; return; } if (it.contains("Finished")) { long useTime = currentTimeMillis - lastFrameTime; //记录时间 if (useTime > 100) { //todo 要判断哪里耗时操作导致的 Log.i(TAG, "执行超过100毫秒"); } } } }; //然后注册 Looper mainLooper = Looper.getMainLooper(); mainLooper.setMessageLogging(printer);7.3 应用场景
继续扩展一下,如果我们仅仅知道主线程卡不卡肯定还不够的。我们肯定还想知道到底是哪里卡了?这也是BlockCanary所想要解决的。不过我们这里也有一个简单实现,一个类就可以完成性能监控。
1.我们可以开启一个子线程每隔制定时间(比如20毫秒)不断的去捕获主线程的堆栈状态。
2.当println回调通知Message的回调执行开始时,我们把每次的捕获到的堆栈存储到Map当中。
3.当println回调通知结束时,我们判断一下执行时间,超过超时,则打印Map中所有的堆栈结构。如果Map中存在两个一摸一样堆栈结构,则说明这个堆栈所对应的方法至少执行了20毫秒(最多40毫秒)。如果存在3个,则至少执行了40毫秒,以此类推。
4.所以通过打印的相同堆栈的次数,我们就知道了到底是哪里导致的卡顿。开发调试阶段我经常用,十分好用。
附小型性能监控类完整代码:
package com.common.monitor; import android.content.Context; import android.os.Handler; import android.os.HandlerThread; import android.os.Looper; import android.util.Log; import android.util.Printer; import com.common.monitor.monitor.BaseMonitor; import java.util.HashMap; import java.util.Hashtable; import java.util.Map; public class ANRMonitor{ final static String TAG = "anr"; public static void init(Context context) { if (true){//开关 return; } ANRMonitor anrMonitor = new ANRMonitor(); anrMonitor.start(context); Log.i(TAG, "ANRMonitor init"); } private void start(Context context) { Looper mainLooper = Looper.getMainLooper(); mainLooper.setMessageLogging(printer); HandlerThread handlerThread = new HandlerThread(ANRMonitor.class.getSimpleName()); handlerThread.start(); //时间较长,则记录堆栈 threadHandler = new Handler(handlerThread.getLooper()); mCurrentThread = Thread.currentThread(); } private long lastFrameTime = 0L; private Handler threadHandler; private long mSampleInterval = 40; private Thread mCurrentThread;//主线程 private final Map
mStackMap = new HashMap<>(); private Printer printer = new Printer() { @Override public void println(String it) { long currentTimeMillis = System.currentTimeMillis(); //其实这里应该是一一对应判断的,但是由于是运行主线程中,所以Dispatching之后一定是Finished,依次执行 if (it.contains("Dispatching")) { lastFrameTime = currentTimeMillis; //开始进行记录 threadHandler.postDelayed(mRunnable, mSampleInterval); synchronized (mStackMap) { mStackMap.clear(); } return; } if (it.contains("Finished")) { long useTime = currentTimeMillis - lastFrameTime; //记录时间 if (useTime > 20) { //todo 要判断哪里耗时操作导致的 Log.i(TAG, "ANR:" + it + ", useTime:" + useTime); //大于100毫秒,则打印出来卡顿日志 if (useTime > 100) { synchronized (mStackMap) { Log.i(TAG, "mStackMap.size:" + mStackMap.size()); for (String key : mStackMap.keySet()) { Log.i(TAG, "key:" + key + ",state:" + mStackMap.get(key)); } mStackMap.clear(); } } } threadHandler.removeCallbacks(mRunnable); } } }; private Runnable mRunnable = new Runnable() { @Override public void run() { doSample(); threadHandler .postDelayed(mRunnable, mSampleInterval); } }; protected void doSample() { StringBuilder stringBuilder = new StringBuilder(); for (StackTraceElement stackTraceElement : mCurrentThread.getStackTrace()) { stringBuilder .append(stackTraceElement.toString()) .append("\n"); } synchronized (mStackMap) { mStackMap.put(mStackMap.size() + "", stringBuilder.toString()); } } }
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/213366.html原文链接:https://javaforall.net


