
- 流式处理是利用连续计算来处理无限数据流的能力,因为数据流是流动的。所以无须收集或存储数据以对其进行操作
流式处理


这个弹珠图是流式处理的一个简单表示。图中每个圆圈代表某一特定时间点的某些信息或发生的事件,事件的数量是无限的,并且不断地从左往右移动
2.处理购买交易

public class ZMartKafkaStreamsApp { private static final Logger LOG = LoggerFactory.getLogger(ZMartKafkaStreamsApp.class); public static void main(String[] args) throws Exception { StreamsConfig streamsConfig = new StreamsConfig(getProperties()); Serde
purchaseSerde = StreamsSerdes.PurchaseSerde(); Serde
purchasePatternSerde = StreamsSerdes.PurchasePatternSerde(); Serde
rewardAccumulatorSerde = StreamsSerdes.RewardAccumulatorSerde(); Serde
stringSerde = Serdes.String(); StreamsBuilder streamsBuilder = new StreamsBuilder(); KStream
purchaseKStream = streamsBuilder.stream("transactions", Consumed.with(stringSerde, purchaseSerde)) .mapValues(p -> Purchase.builder(p).maskCreditCard().build()); KStream
patternKStream = purchaseKStream.mapValues(purchase -> PurchasePattern.builder(purchase).build()); patternKStream.print(Printed.
toSysOut().withLabel("patterns")); patternKStream.to("patterns", Produced.with(stringSerde,purchasePatternSerde)); KStream
rewardsKStream = purchaseKStream.mapValues(purchase -> RewardAccumulator.builder(purchase).build()); rewardsKStream.print(Printed.
toSysOut().withLabel("rewards")); rewardsKStream.to("rewards", Produced.with(stringSerde,rewardAccumulatorSerde)); purchaseKStream.print(Printed.
toSysOut().withLabel("purchases")); purchaseKStream.to("purchases", Produced.with(stringSerde,purchaseSerde)); // used only to produce data for this application, not typical usage MockDataProducer.producePurchaseData(); KafkaStreams kafkaStreams = new KafkaStreams(streamsBuilder.build(),streamsConfig); LOG.info("ZMart First Kafka Streams Application Started"); kafkaStreams.start(); Thread.sleep(65000); LOG.info("Shutting down the Kafka Streams Application now"); kafkaStreams.close(); MockDataProducer.shutdown(); } private static Properties getProperties() { Properties props = new Properties(); props.put(StreamsConfig.CLIENT_ID_CONFIG, "FirstZmart-Kafka-Streams-Client"); props.put(ConsumerConfig.GROUP_ID_CONFIG, "zmart-purchases"); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "FirstZmart-Kafka-Streams-App"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(StreamsConfig.REPLICATION_FACTOR_CONFIG, 1); props.put(StreamsConfig.DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG, WallclockTimestampExtractor.class); return props; } }
3.流和状态
public class ZMartKafkaStreamsAddStateApp { private static final Logger LOG = LoggerFactory.getLogger(ZMartKafkaStreamsAddStateApp.class); public static void main(String[] args) throws Exception { StreamsConfig streamsConfig = new StreamsConfig(getProperties()); Serde
purchaseSerde = StreamsSerdes.PurchaseSerde(); Serde
purchasePatternSerde = StreamsSerdes.PurchasePatternSerde(); Serde
rewardAccumulatorSerde = StreamsSerdes.RewardAccumulatorSerde(); Serde
stringSerde = Serdes.String(); StreamsBuilder builder = new StreamsBuilder(); KStream
purchaseKStream = builder.stream( "transactions", Consumed.with(stringSerde, purchaseSerde)) .mapValues(p -> Purchase.builder(p).maskCreditCard().build()); KStream
patternKStream = purchaseKStream.mapValues(purchase -> PurchasePattern.builder(purchase).build()); patternKStream.print(Printed.
toSysOut().withLabel("patterns")); patternKStream.to("patterns", Produced.with(stringSerde, purchasePatternSerde)); // adding State to processor String rewardsStateStoreName = "rewardsPointsStore"; RewardsStreamPartitioner streamPartitioner = new RewardsStreamPartitioner(); KeyValueBytesStoreSupplier storeSupplier = Stores.inMemoryKeyValueStore(rewardsStateStoreName); StoreBuilder
> storeBuilder = Stores.keyValueStoreBuilder(storeSupplier, Serdes.String(), Serdes.Integer()); builder.addStateStore(storeBuilder); KStream
transByCustomerStream = purchaseKStream.through( "customer_transactions", Produced.with(stringSerde, purchaseSerde, streamPartitioner)); KStream
statefulRewardAccumulator = transByCustomerStream.transformValues(() -> new PurchaseRewardTransformer(rewardsStateStoreName), rewardsStateStoreName); statefulRewardAccumulator.print(Printed.
toSysOut().withLabel("rewards")); statefulRewardAccumulator.to("rewards", Produced.with(stringSerde, rewardAccumulatorSerde)); // used only to produce data for this application, not typical usage MockDataProducer.producePurchaseData(); LOG.info("Starting Adding State Example"); KafkaStreams kafkaStreams = new KafkaStreams(builder.build(),streamsConfig); LOG.info("ZMart Adding State Application Started"); kafkaStreams.cleanUp(); kafkaStreams.start(); Thread.sleep(65000); LOG.info("Shutting down the Add State Application now"); kafkaStreams.close(); MockDataProducer.shutdown(); }
4.数据本地化
数据本地化堆性能至关重要。虽然键查找通常非常快,但是当远程存储在大规模处理时带来的延迟将成为瓶颈。
下图说明了数据本地化背后的原理,本地数据调用比通过网络向远程数据库的调用更有效

当一个流式应用程序处理数百万或数十亿条记录,当乘以一个较大的因子时,即使较小的网络延迟也会产生巨大的影响。
5.故障恢复和容错
从失败中恢复的能力对于流式处理应用程序非常重要,所以任何一个进程失败都不会使其他进程收到影响。此外,每个存储的键/值都在主题中做了复制,以用于在进程失败或重启时恢复丢失的值

kafka streams提供的状态存储既能满足本地化又能满足容错性的需求,对于已经定义的处理器来说它们是本地的,并且不会跨进程或线程访问共享。状态存储也使用主题来做备份和快速恢复。
6.状态存储容错
kafka streams的状态默认都启用了日志。日志在这里指一个kafka主题,该主题作为一个变更日志用来备份存储中的值并提供容错。
假设有一台运行kafka streams的应用程序宕机了,一旦服务器恢复并重新启动了kafka streams的应用程序,该机器上对应实例的状态存储就会恢复到它们原来的内容(在崩溃之前变更日志中最后提交的偏移量)
7.处理器API
public static void main(String[] args) throws Exception { MockDataProducer.producePurchaseData(); StreamsConfig streamsConfig = new StreamsConfig(getProperties()); Deserializer
stringDeserializer = Serdes.String().deserializer(); Serializer
stringSerializer = Serdes.String().serializer(); Serde
purchaseSerde = StreamsSerdes.PurchaseSerde(); Deserializer
purchaseDeserializer = purchaseSerde.deserializer(); Serializer
purchaseSerializer = purchaseSerde.serializer(); Serializer
patternSerializer = StreamsSerdes.PurchasePatternSerde().serializer(); Serializer
rewardsSerializer = StreamsSerdes.RewardAccumulatorSerde().serializer(); Topology topology = new Topology(); topology.addSource("txn-source", stringDeserializer, purchaseDeserializer, "transactions") .addProcessor("masking-processor", () -> new MapValueProcessor
(p -> Purchase.builder(p).maskCreditCard().build()), "txn-source") .addProcessor("rewards-processor", () -> new MapValueProcessor
(purchase -> RewardAccumulator.builder(purchase).build()), "txn-source") .addProcessor("patterns-processor", () -> new MapValueProcessor
(purchase -> PurchasePattern.builder(purchase).build()), "txn-source") .addSink("purchase-sink", "purchases", stringSerializer, purchaseSerializer, "masking-processor") .addSink("rewards-sink", "rewards", stringSerializer, rewardsSerializer, "rewards-processor") .addSink("patterns-sink", "patterns", stringSerializer, patternSerializer, "patterns-processor"); topology.addProcessor("purchase-printer", new KStreamPrinter("purchase"), "masking-processor") .addProcessor("rewards-printer", new KStreamPrinter("rewards"), "rewards-processor") .addProcessor("patterns-printer", new KStreamPrinter("pattens"), "patterns-processor"); KafkaStreams kafkaStreams = new KafkaStreams(topology, streamsConfig); System.out.println("ZMart Processor App Started"); kafkaStreams.start(); Thread.sleep(35000); System.out.println("Shutting down the ZMart Processor App now"); kafkaStreams.close(); MockDataProducer.shutdown(); }
8.监控和性能
8.1基本监控
生产者在kafka节点发送消息的速度与消费者何时从代理读到这些消息之间的时间差异称为消费滞后

消费者肯定会有一些滞后,但理想状况下,消费者会赶上消息生产的速度,或者至少滞后速率一致,而不是滞后逐渐增加

检查消费者滞后
>bin/kafka-consumer-groups.sh –bootstrap-server localhost:9092 –list //找出所有活跃的消费者组
>bin/kafka-consumer-groups.sh –bootstrap-server localhost:9092 –group
–describe
有一点滞后或者保持在一个恒定的速率的滞后就没问题,但是如果出现随时间的推移,滞后也持续增长的现象就表明需要给消费者更多的资源。例如增加分区数,从而增加从主题消费的线程数。
或者有可能读取消息后的处理逻辑太繁重了,在消费消息滞后,你可以将其移到一个异步队列中,然后由另一个线程从异步队列中获取该消息并作处理。
8.2应用程序指标
当提到衡量应用程序的性能时,你可以大致了解一条记录需要多长时间,测量短刀端延迟无疑是一个好的总体性能指标。但如果你想提升性能,你就需要精确知道在哪里变慢了

线程指标
提交、轮询和处理操作的平均时间
每秒创建的任务数,以及每秒关闭的任务数
任务指标
每秒提交任务的平均数
平均提交时间
处理器节点指标
平均以及最大处理时间
每秒处理操作的平均数
转发速率
状态存储指标
put、get和flush操作的平均执行时间
平均每秒执行put、get和flush操作数
指标配置
会有性能成本,单个指标本身可能代价并不大,但是当乘以一个较大的因子(数万甚至更大)时,影响就比较大了。因此在将指标采集级别设置为DEBUG级别之前,先仔细考虑这些指标对应用程序性能的影响
private static Properties getProperties() { Properties props = new Properties(); props.put(StreamsConfig.CLIENT_ID_CONFIG, "zmart-metrics-client-id"); props.put(ConsumerConfig.GROUP_ID_CONFIG, "zmart-metrics-group-id"); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "zmart-metrics-application-id"); props.put(StreamsConfig.METRICS_RECORDING_LEVEL_CONFIG, "DEBUG"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(StreamsConfig.producerPrefix(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG), Collections.singletonList(ZMartProducerInterceptor.class)); return props; }
配置后可使用jvm自带的jconsole工具观察
8.3更多kafka streams调试技术
关注获得关于应用程序的各种状态的通知并查看拓扑结构的技术
- Topology.describe()

获取应用程序各种状态的通知
当启动kafka streams应用程序时,它不会自动开始处理数据,需要先做一些协调工作。例如,消费者需要获取元数据和订阅信息;应用程序需要启动StreamThread实例,并给相应的StreamTask分配TopicPartition。
分配或重新分配任务的过程称为再平衡,再平衡意味着kafka streams能够自动伸缩,这是一个至关重要的优势,你可以在现有应用程序已运行时添加新的应用程序实例,并且再平衡过程将重新分配工作负载
引发再平衡操作的原因包括:另一个具有相同应用程序ID的kafka streams实例启停,增加一个主题的分区,或者在正则表达式定义源节点的情况下添加或移除与正则表达式匹配的主题
在再平衡阶段,在应用程序完成主题的分区分配给流任务之前,外部交互将会暂停,因此在应用程序的生命周期中应该意识到这一点。例如,可查询状态存储不可用,因此在状态存储再次可用之前要能够限制查看存储内容的请求
幸运的是,kafka streams提供了一种StateListener机制,来查出应用程序是否在进行再平衡
使用状态监听器
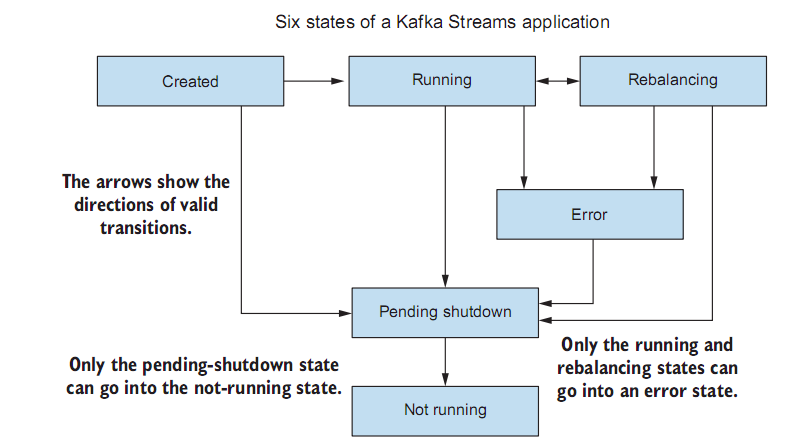
KafkaStreams kafkaStreams = new KafkaStreams(topology, streamsConfig); kafkaStreams.setGlobalStateRestoreListener(new LoggingStateRestoreListener()); kafkaStreams.setUncaughtExceptionHandler((thread, exception) -> LOG.error("Thread [{}] encountered [{}]", thread.getName(), exception.getMessage()) ); kafkaStreams.setStateListener((newState, oldState) -> { if (oldState == KafkaStreams.State.REBALANCING && newState== KafkaStreams.State.RUNNING) { LOG.info("Topology Layout {}", topology.describe()); LOG.info("Thread metadata {}", kafkaStreams.localThreadsMetadata()); } });
状态恢复监听器
public class LoggingStateRestoreListener implements StateRestoreListener { private static final Logger LOG = LoggerFactory.getLogger(LoggingStateRestoreListener.class); private final Map
totalToRestore = new ConcurrentHashMap<>(); private final Map
restoredSoFar = new ConcurrentHashMap<>(); @Override public void onRestoreStart(TopicPartition topicPartition, String store, long start, long end) { long toRestore = end - start; totalToRestore.put(topicPartition, toRestore); LOG.info("Starting restoration for {} on topic-partition {} total to restore {}", store, topicPartition, toRestore); } @Override public void onBatchRestored(TopicPartition topicPartition, String store, long start, long batchCompleted) { NumberFormat formatter = new DecimalFormat("#."); long currentProgress = batchCompleted + restoredSoFar.getOrDefault(topicPartition, 0L); double percentComplete = (double) currentProgress / totalToRestore.get(topicPartition); LOG.info("Completed {} for {}% of total restoration for {} on {}", batchCompleted, formatter.format(percentComplete * 100.00), store, topicPartition); restoredSoFar.put(topicPartition, currentProgress); } @Override public void onRestoreEnd(TopicPartition topicPartition, String store, long totalRestored) { LOG.info("Restoration completed for {} on topic-partition {}", store, topicPartition); restoredSoFar.put(topicPartition, 0L); } }
未捕获的异常处理器
9.额外的配置信息
A.1限制启动时再平衡数量
group.initial.rebalance.delay.ms ,当有新消费者假如消费者组时,该配置会让最初消费者从GroupCoordinator中再平衡延迟配置中指定的时间,该配置默认3s。
假设你启动类4个实例,同时设置了适当的再平衡延迟时间,那么应该在4个实例都上线之后只进行一次再平衡操作——这意味着你可以更快的开始处理数据
A.2应对代理中断的能力
设置Producer.NUM_RETRIES为Integer.MAX_VALUE
设置Producer.REQUEST_TIMEOUT为(5分钟)
设置Producer.BLOCK_MS_CONFIG为Integer.MAX_VALUE
设置Consumer.MAX_POLL_CONFIG为Integer.MAX_VALUE
设置这些值应该有助于确保:如果Kafka集群中的所有代理都已关闭,那么Kafka Streams应用程序将保持不变,这样一旦代理重新上线之后它们就能准备好重新开始工作
A.3处理反序列化错误
在处理数据时遇到一些异常数据并不意外,Kafka Streams提供了配置项default.deserialization.exception.handler来指定如何处理反序列化时发生的错误
默认设置是LogAndFailExceptionHandler,当发生反序列化异常时Kafka Streams应用程序实例将会失败(关闭)。此外还提供了一个配置选项LogAndContinueExceptionHandler,
记录错误日志,但Kafka streams应用程序将继续运行。也可以自定义实现
A.4扩展应用程序
例如具有12个分区的单个输入主题,有12个分区,kafka streams就会创建12个任务。现在我们假设每个任务对应一个线程,你也可以拥有一个具有2个线程的实例,但这种方式有个缺陷:
如果承载Kafka streams应用程序的机器宕机了,所有的流式处理都将停止
但是如果每个实例都启动4个线程,那么每个实例将会处理4个输入分区,这种方式的好处是如果其中一个Kafka streams实例停止运行,就会触发再平衡,那么停止运行的4个任务就会被分配
给其它2个实例来完成
A.5配置内部主题
当构建拓扑时,Kafka streams会创建几个内部主题,这些内部主题可以是用于备份状态存储的变更日志或者重新分区主题。根据数据量,这些内部主题可能会占用大量的空间。此外,
即使变更日志主题默认情况下在创建时会使用”compact”清除策略,,但如果就有很多唯一的键,那么这些压缩主题也会逐渐增大。考虑到这一点,最好对内部主题进行配置以使其大小易于管理。
props.put(StreamsConfig.topicPrefix(“retention.bytes”),1024*1024);
props.put(StreamsConfig.topicPrefix(“retention.ms”),);
props.put(“cleanup.policy”,”compact,delete”)
A.6清理本地状态
在开发或者测试期间,或者迁移到一个新实例时,你可能想要清除以前所有的本地状态。在调用KafkaStreams.start方法之前或KafkaStreams.stop方法只有调用KafkaStreams.cleanUp方法。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/214293.html原文链接:https://javaforall.net


