
目录
先甩几个典型的线性回归的模型,帮助大家捡起那些年被忘记的数学。
● 单变量线性回归: h(x)=theta0 + theta1* x 1
● 多变量线性回归: h(x)=theta0 + theta1* x 1 + theta2* x 2 + theta3* x 3
● 多项式回归: h(x)=theta0 + theta1* x 1 + theta2* (x2^2) + theta3* (x3^3)
多项式回归始终还是线性回归,你可以令x2=x2^2,x3=x3^3,简单的数据处理一下就好了,这样上述多项式回归的模型就变成多变量线性回归的模型了。
数据导入
下面我们要开始用数据说话了,先来看看数据源是什么样子吧。
import pandas as pd import numpy as np import matplotlib.pyplot as plt from pandas import DataFrame,Series from sklearn.cross_validation import train_test_split from sklearn.linear_model import LinearRegression #读取文件 datafile = u'E:\\pythondata\\dhdhdh.xlsx'#文件所在位置,u为防止路径中有中文名称,此处没有,可以省略 data = pd.read_excel(datafile)#datafile是excel文件,所以用read_excel,如果是csv文件则用read_csv examDf = DataFrame(data) examDf.head()运行结果:
Call Connect Return 0 2.1335 1. 1. 1 2.5534 1. 1. 2 3.3361 1. 2. 3 3.3861 1. 2. 4 3.9682 1. 2.
单变量线性回归
绘制散点图
先将上述数据中的Connect(接通量)和Return(回款量)做一个单变量的线性回归,先绘制一个散点图,大致看一下分布情况。
#绘制散点图,examDf.jt为X轴,examDf.hk为Y轴 plt.scatter(examDf.Connect,examDf.Return,color = 'darkgreen',label = "Exam Data") #添加图的标签(x轴,y轴) plt.xlabel("The Connection amount of the average account")#设置X轴标签 plt.ylabel("The ratio of average return amount")#设置Y轴标签 plt.show()#显示图像运行结果:
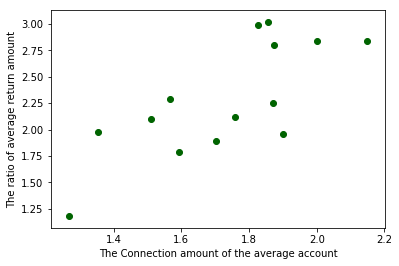

看来商业中的实际数据总是和课本上的完美数据不一样,看这零零散散的分布,线性关系很是勉强,但是大致还是有一个线性相关的样子的,那么就看看相关系数有多少吧。
相关系数R
rDf = examDf.corr()#查看数据间的相关系数 print(rDf)运行结果:
Call Connect Return Call 1.000000 0. 0. Connect 0. 1.000000 0. Return 0. 0. 1.000000
Connect(接通量)和Return(回款量)的相关系数为0.,还不错。
相关系数是用以反映变量之间相关关系密切程度的统计指标,对于相关性强度来说,我们一般认为:
0~0.3 弱相关
0.3~0.6 中等程度相关
0.6~1 强相关
在数学中,相关系数的计算一般是这样的,给数学狂人看:
R(相关系数) = X和Y的协方差 / (X的标准差 * Y的标准差) == cov(X,Y)/ σX * σY (即person系数)
拆分训练集和测试集
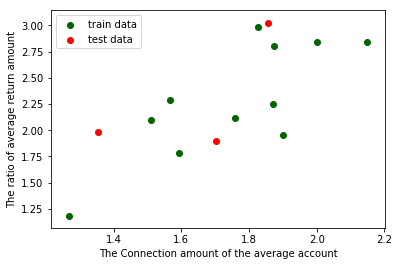
Connect(接通量)和Return(回款量)属于强相关,可以进行线性回归训练,那么我们先来拆分训练集和测试集吧。
#拆分训练集和测试集(train_test_split是存在与sklearn中的函数) X_train,X_test,Y_train,Y_test = train_test_split(examDf.Connect,examDf.Return,train_size=0.8) #train为训练数据,test为测试数据,examDf为源数据,train_size 规定了训练数据的占比 print("自变量---源数据:",examDf.Connect.shape, "; 训练集:",X_train.shape, "; 测试集:",X_test.shape) print("因变量---源数据:",examDf.Return.shape, "; 训练集:",Y_train.shape, "; 测试集:",Y_test.shape) #散点图 plt.scatter(X_train, Y_train, color="darkgreen", label="train data")#训练集为深绿色点 plt.scatter(X_test, Y_test, color="red", label="test data")#测试集为红色点 #添加标签 plt.legend(loc=2)#图标位于左上角,即第2象限,类似的,1为右上角,3为左下角,4为右下角 plt.xlabel("The Connection amount of the average account")#添加 X 轴名称 plt.ylabel("The ratio of average return amount")#添加 Y 轴名称 plt.show()#显示散点图运行结果:
自变量---源数据: (14,) ; 训练集: (11,) ; 测试集: (3,) 因变量---源数据: (14,) ; 训练集: (11,) ; 测试集: (3,)
回归模型训练
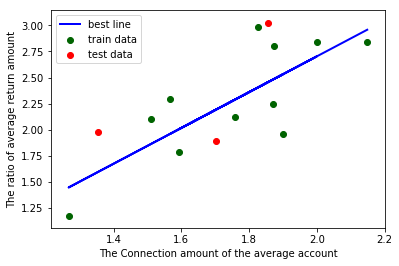
#调用线性规划包 model = LinearRegression() #线性回归训练 model.fit(X_train,Y_train)#调用线性回归包 a = model.intercept_#截距 b = model.coef_#回归系数 #训练数据的预测值 y_train_pred = model.predict(X_train) #绘制最佳拟合线:标签用的是训练数据的预测值y_train_pred plt.plot(X_train, y_train_pred, color='blue', linewidth=2, label="best line") #测试数据散点图 plt.scatter(X_train, Y_train, color='darkgreen', label="train data") plt.scatter(X_test, Y_test, color='red', label="test data") #添加图标标签 plt.legend(loc=2)#图标位于左上角,即第2象限,类似的,1为右上角,3为左下角,4为右下角 plt.xlabel("The Connection amount of the average account")#添加 X 轴名称 plt.ylabel("The ratio of average return amount")#添加 Y 轴名称 plt.show()#显示图像 print("拟合参数:截距",a,",回归系数:",b) print("最佳拟合线: Y = ",round(a,2),"+",round(b[0],2),"* X")#显示线性方程,并限制参数的小数位为两位 运行结果:
拟合参数:截距 -0.87745 ,回归系数: [1.] 最佳拟合线: Y = -0.73 + 1.72 * X
补充一句,有博友说单变量线性回归上面的这段代码中,加一个reshape就能运行出来了,可能是版本不同,我没加也能运行出来,所以分享在下面给大家参考一下,如果有和博友一样的情况,可以试试增加下面一段代码(谢谢博友 dsy23 的分享):
#调用线性规划包 model = LinearRegression() #在这里加一段 X_train = X_train.values.reshape(-1,1) X_test = X_test.values.reshape(-1,1) #线性回归训练 model.fit(X_train,Y_train)#调用线性回归包 a = model.intercept_#截距 b = model.coef_#回归系数多变量线性回归
在单变量线性回归中,我们将每一步都讲解的极其详细,所以在多变量线性回归中,我们不会重复讲那些简单的部分了,但是为了防止python小白迷失自己,所以在这部分该有的代码还是会甩出来,该有的备注也都有,只不过不会一点一点分步骤来了。
上面我们提到多变量线性回归的模型为h(x)=theta0 + theta1* x 1 + theta2* x 2 + theta3* x 3,下面,我们还是使用单变量线性回归中的数据,单变量线性回归中,我们只用到了Connect(接通量)和Return(回款量),既然是多变量回归模型,那么我们就多加一个变量Call(拨打量)。
数据检验(判断是否可以做线性回归)
#-*- coding:utf-8 -*- import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt from pandas import DataFrame,Series from sklearn.cross_validation import train_test_split from sklearn.linear_model import LinearRegression #读取文件 datafile = u'E:\\pythondata\\dhdhdh.xlsx'#文件所在位置,u为防止路径中有中文名称,此处没有,可以省略 data = pd.read_excel(datafile)#datafile是excel文件,所以用read_excel,如果是csv文件则用read_csv examDf = DataFrame(data) #数据清洗,比如第一列有可能是日期,这样的话我们就只需要从第二列开始的数据, #这个情况下,把下面中括号中的0改为1就好,要哪些列取哪些列 new_examDf = examDf.ix[:,0:] #检验数据 print(new_examDf.describe())#数据描述,会显示最值,平均数等信息,可以简单判断数据中是否有异常值 print(new_examDf[new_examDf.isnull()==True].count())#检验缺失值,若输出为0,说明该列没有缺失值 #输出相关系数,判断是否值得做线性回归模型 print(new_examDf.corr())#0-0.3弱相关;0.3-0.6中相关;0.6-1强相关; #通过seaborn添加一条最佳拟合直线和95%的置信带,直观判断相关关系 sns.pairplot(data, x_vars=['Call','Connect'], y_vars='Return', size=7, aspect=0.8, kind='reg') plt.show() 运行结果:
Call Connect Return count 99.000000 99.000000 99.000000 mean 3. 1. 2. std 1.027607 0. 0. min 1. 1.014208 0. 25% 2. 1. 2.044147 50% 3.040000 1. 2. 75% 3. 2. 3.035603 max 5. 3. 5. Call 0 Connect 0 Return 0 dtype: int64 Call Connect Return Call 1.000000 0. 0. Connect 0. 1.000000 0. Return 0. 0. 1.000000
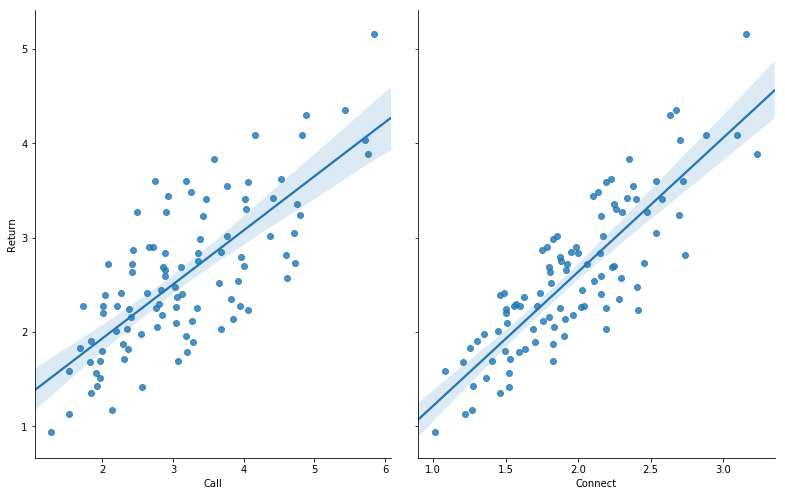
判断是否可以做线性回归:
- 异常值:通过最值或者平均数或者中位数等判断,或者直接通过查看是否有游离在大部队之外的点来判断是否有异常值;
- 空值:这个没办法,你必须看运行结果的10-12行是否等于0,是0则无空值,如果不是0,就要看看是删掉空值呢?还是用其他值代替呢?不同情况不同对待;
- 相关性:要么通过相关系数的大小判断,要么看散点图中的最佳拟合直线和95%的置信带,直观判断相关关系;
训练线性回归模型
#拆分训练集和测试集 X_train,X_test,Y_train,Y_test = train_test_split(new_examDf.ix[:,:2],new_examDf.Return,train_size=0.8) #new_examDf.ix[:,:2]取了数据中的前两列为自变量,此处与单变量的不同 print("自变量---源数据:",new_examDf.ix[:,:2].shape, "; 训练集:",X_train.shape, "; 测试集:",X_test.shape) print("因变量---源数据:",examDf.Return.shape, "; 训练集:",Y_train.shape, "; 测试集:",Y_test.shape) #调用线性规划包 model = LinearRegression() model.fit(X_train,Y_train)#线性回归训练 a = model.intercept_#截距 b = model.coef_#回归系数 print("拟合参数:截距",a,",回归系数:",b) #显示线性方程,并限制参数的小数位为两位 print("最佳拟合线: Y = ",round(a,2),"+",round(b[0],2),"* X1 + ",round(b[1],2),"* X2") Y_pred = model.predict(X_test)#对测试集数据,用predict函数预测 plt.plot(range(len(Y_pred)),Y_pred,'red', linewidth=2.5,label="predict data") plt.plot(range(len(Y_test)),Y_test,'green',label="test data") plt.legend(loc=2) plt.show()#显示预测值与测试值曲线 运行结果:
自变量---源数据: (99, 2) ; 训练集: (79, 2) ; 测试集: (20, 2) 因变量---源数据: (99,) ; 训练集: (79,) ; 测试集: (20,) 拟合参数:截距 -0.0070601 ,回归系数: [0.0 1.] 最佳拟合线: Y = -0.01 + 0.09 * X1 + 1.19 * X2
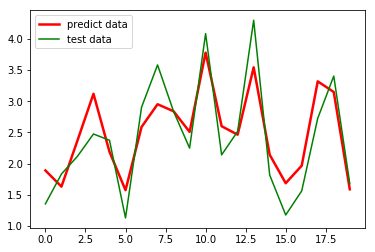
效果勉强满意,毕竟才用了80个数训练的模型,要求高的话多用一些数据就好。
除了用 Python 做线性回归,我们还可以使用 SPSS 来做,不用编程,不用各种调参,就是点几下就可以输出结果,更简便!具体操作请参考下面链接里的文章:
数据建模 – SPSS做多元线性回归 – 分析步骤、输出结果详解、与Python的结果对比 -(SPSS)
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/214996.html原文链接:https://javaforall.net


