
k均值算法原理和优缺点
点击打开链接
定义
D=类内平均距离/类间平均距离
不同的K有不同的D,D越小越好,但k也不能过大,根据实际情况取。
数据集
96个维度的616条数据。
matlab代码
clc;clear data=xlsread('C:\Users\Administrator\Desktop\数据.xlsx','Sheet1'); [n,p]=size(data); for i=1:p minr=min(data(:,i)); maxr=max(data(:,i)); data(:,i)=(data(:,i)-minr)/(maxr-minr);%归一化 end K=15;D=zeros(K-1,2);T=0; for k=2:K T=T+1; [lable,c,sumd,d]=kmeans(data,k); %data,n*p原始数据向量 %lable,n*1向量,聚类结果标签; %c,k*p向量,k个聚类质心的位置 %sumd,1*k向量,类间所有点与该类质心点距离之和 %d,n*k向量,每个点与聚类质心的距离 %-----求每类数量----- sort_num=zeros(k,1);%每类数量 for i=1:k for j=1:n if lable(j,1)==i sort_num(i,1)=sort_num(i,1)+1; end end end %-----求每类数量----- sort_ind=sumd./sort_num;%每类类内平均距离 sort_ind_ave=mean(sort_ind);%类内平均距离 %-----求类间平均距离----- h=nchoosek(k,2);A=zeros(h,2);t=0;sort_outd=zeros(h,1); for i=1:k-1 for j=i+1:k t=t+1; A(t,1)=i; A(t,2)=j; end end for i=1:h for j=1:p sort_outd(i,1)=sort_outd(i,1)+(c(A(i,1),j)-c(A(i,2),j))^2; end end sort_outd_ave=mean(sort_outd);%类间平均距离 %-----求类间平均距离----- D(T,1)=k; D(T,2)=sort_ind_ave/sort_outd_ave; end min(D(:,2)); [f,g]=find(D==min(D(:,2))); plot(D(:,1),D(:,2))运行结果

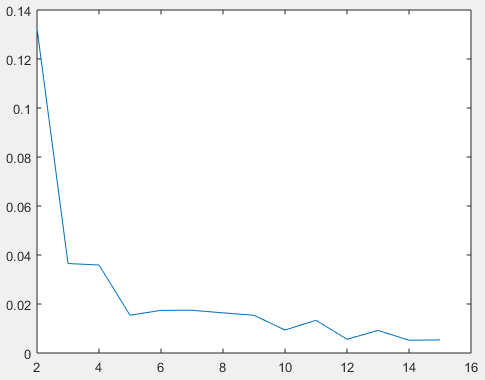
横坐标为K,纵坐标为D,随着K的增加D虽然越来越小,但结合实际业务,K不能取太大,取5较好。
K取5的聚类matlab代码如下:
clc;clear; k=5;%类数设置 data=xlsread('C:\Users\Administrator\Desktop\数据.xlsx','Sheet1'); [n,p]=size(data); [lable,c,sumd,d]=kmeans(data,k); %data,n*p原始数据向量 %lable,n*1向量,聚类结果标签; %c,k*p向量,k个聚类质心的位置 %sumd,1*k向量,类间所有点与该类质心点距离之和 %d,n*k向量,每个点与聚类质心的距离 x=0:95;y=zeros(k,p); for i=1:k t=0; for j=1:n if lable(j,1)==i t=t+1; y(i,:)= y(i,:)+data(j,:); end end y(i,:)= y(i,:)/t; subplot(2,3,i); plot(x,y(i,:)) end聚类效果如下

如果对你有帮助,请点下赞,予人玫瑰手有余香!
时时仰望天空,理想就会离现实越来越近!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/215091.html原文链接:https://javaforall.net


