
一、正态分布
- 标准正态分布
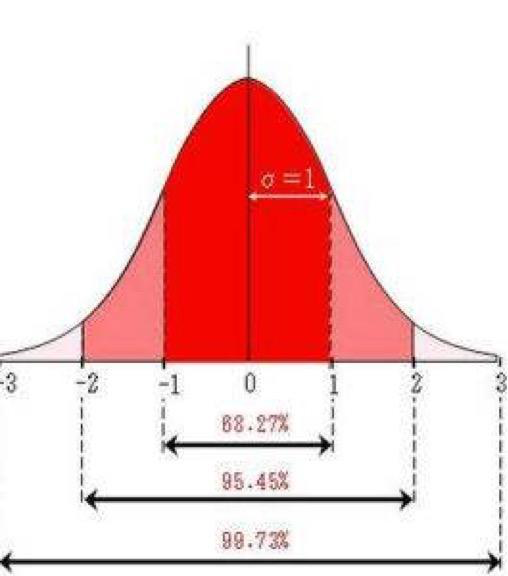
标准正态分布就是均值为0,标准差为1的分布,如下图

- 一般正态分布
一般正态分布n,假设其均值是 μ,标准差为σ ,即服从 n~N(μ,σ)
经过变换可以转换成标准正态分布:另X = (N – μ)/ σ,则X就是服从标准的正态分布了X~N(0,1)
二、置信区间
- 上图中的面积就是标准正态分布的概率,而置信区间就是变量的区间估计,例如图中的-1到1就是一个置信区间:标准正态分布的变量X ,有68.27%的概率 X属于[-1,1]这个区间。
最常用的是95%的分布区间,就是[-1.96,1.96]这个区间。方便公式化,我们另区间为[-z,z],那么 -z<=X<=z。
进而可以推导一般正态分布的置信区间:
-z<=X<=z
-z<=(N - μ)/ σ<=z
μ-zσ<=N<=μ+zσ
因此,一般正态分布n~N(μ,σ)的置信区间是 [μ-zσ, μ+zσ],其中z根据置信水平而定。置信水平与区间对应关系如下: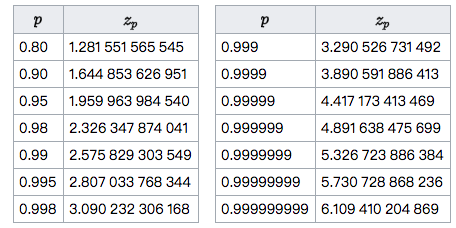
- 性质分析
置信区间与置信水平、样本量等因素均有关系,其中样本量对置信区间的影响为:在置信水平固定的情况下,样本量越多,置信区间越窄。其次,在样本量相同的情况下,置信水平越高,置信区间越宽。
因此:如果样本多,就说明比较可信,不需要很大的修正,所以置信区间会比较窄,下限值会比较大;但是如果样本少,就说明不一定可信,必须进行较大的修正,置信区间会比较宽,下限值会比较小。
由此得出结论:上述正态区间只适用于样本较多的情况,对于小样本,它的准确性很差。
三、威尔逊区间(Wilson score interval)
- 由于正态区间对于小样本并不可靠,因而,1927年,美国数学家 Edwin Bidwell Wilson提出了一个修正公式,被称为“威尔逊区间”,很好地解决了小样本的准确性问题。
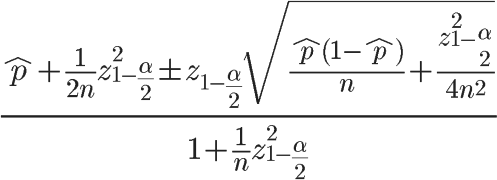
在上面的公式中,^p表示样本的”赞成票比例”,n表示样本的大小,z表示对应某个置信水平的z统计量,这是一个常数,可以通过查前文表得到。一般情况下,在95%的置信水平下,z统计量的值为1.96。 - 威尔逊置信区间的均值为
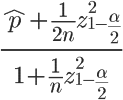
下限为:
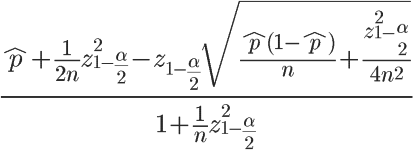
可以看到:当n的值足够大时,这个下限值会趋向^p。如果n非常小(投票人很少),这个下限值会大大小于p,实际上,起到了降低”赞成票比例”的作用,使得该项目的得分变小、排名下降。 - 根据离散型随机变量的均值和方差定义:
μ=E(X)=0*(1-p)+1*p=p
σ=D(X)=(0-E(X))2(1-p)+(1-E(X))2p=p2(1-p)+(1-p)2p=p2-p3+p3-2p2+p=p-p2=p(1-p)
因此上面的威尔逊区间公式可以写成:
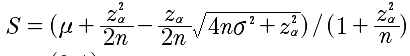
就是对正态区间的均值和标准差进行了修正。
但是有个问题:这个修正公式是仅仅适用于伯努利分布(好差评),还是也适用于其他分布(如5星评价)?这个问题本人也没搞清,望高人指点。
计算程序如下:
def wilson_score(pos, total, p_z=2.): """ 威尔逊得分计算函数 参考:https://en.wikipedia.org/wiki/Binomial_proportion_confidence_interval :param pos: 正例数 :param total: 总数 :param p_z: 正太分布的分位数 :return: 威尔逊得分 """ pos_rat = pos * 1. / total * 1. # 正例比率 score = (pos_rat + (np.square(p_z) / (2. * total)) - ((p_z / (2. * total)) * np.sqrt(4. * total * (1. - pos_rat) * pos_rat + np.square(p_z)))) / \ (1. + np.square(p_z) / total) return score tips:对于5星评价问题,可以参考 http://www.evanmiller.org/ranking-items-with-star-ratings.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/219654.html原文链接:https://javaforall.net


