
1、概念
1.1监督学习(数据集有输入和输出数据):通过已有的一部分输入数据与输出数据之间的相应关系。生成一个函数,将输入映射到合适的输出,比如分类。
1.2无监督学习(数据集中只有输入):直接对输入数据集进行建模,比如聚类。
1.3半监督学习:综合利用有类标的数据和没有类标的数据,来生成合适的分类函数。
2、类别
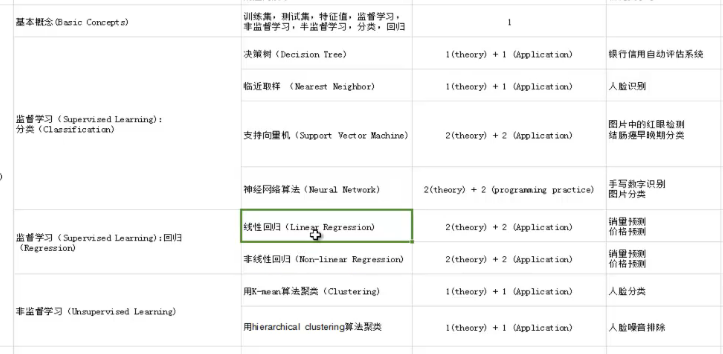
2.1监督学习分为分类(classification)和回归(regression)
最广泛被使用的分类器有人工神经网络、支持向量机、近期邻居法、高斯混合模型、朴素贝叶斯方法、决策树和径向基函数分类。
回归:线性回归,神经网络
2.2无监督学习:主要由聚类。

1.给定一个来自某未知分布的样本集S=L∪U, 当中L 是已标签样本集
L={(x1,y1),(x2,y2), … ,(x |L|,y|L|)}, U是一个未标签样本集U={x’1,x’2,…,x’|U|},希望得到函数f:X → Y能够准确地对样本x预測其标签y,这个函数可能是參数的。如最大似然法;可能是非參数的。如最邻近法、神经网络法、支持向量机法等;也可能是非数值的,如决策树分类。当中, x与x’ 均为d 维向量, yi∈Y 为样本x i 的标签, |L| 和|U| 分别为L 和U 的大小, 即所包括的样本数。半监督学习就是在样本集S 上寻找最优的学习器。怎样综合利用已标签例子和未标签例子,是半监督学习须要解决的问题。
2.3半监督学习问题从样本的角度而言是利用少量标注样本和大量未标注样本进行机器学习。从概率学习角度可理解为研究怎样利用训练样本的输入边缘概率 P( x )和条件输出概率P ( y | x )的联系设计具有良好性能的分类器。这样的联系的存在是建立在某些如果的基础上的。即聚类如果(cluster assumption)和流形如果(maniford assumption)。
项目推荐:
2000多G的计算机各行业电子资源分享(持续更新)
Java微服务实战296集大型视频-谷粒商城【附代码和课件】
Java开发微服务畅购商城实战【全357集大项目】-附代码和课件

发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/220923.html原文链接:https://javaforall.net


