


p 值可以解释如下:一个很小的p 值表示,在预测变量和响应变量之间的真实关系
未知的情况下,不太可能完全由于偶然而观察到预测变量和响应变量之间的强相关。因此,如果看到一个很小的p 值,就可以推断预测变量和响应变量问存在关联。如果p 值足够小,我们便拒绝零假设( reject the null hypothesis) 也就是声明X 和Y 之间存在关系。
# 相关 # 相关系数可以用来描述定量变量之间的关系。相关系数的符号()表明关系的方向(正相 # 关或负相关),其值的大小表示关系的强弱程度(完全不相关时为0,完全相关时为1)我们将使用R基础安装中的 # state.x77数据集,它提供了美国50个州在1977年的人口、收入、文盲率、预期寿命、谋杀率和 # 高中毕业率数据。数据集中还收录了气温和土地面积数据,但为了节约空间,这里将其丢弃。你 # 可以使用help(state.x77)了解数据集的更多信息。除了基础安装以外,我们还将使用psych # 和ggm包。 install.packages("psych") library(psych) install.packages("igraph") library(igraph) install.packages("ggm") library(ggm) # # 相关的类型 # R可以计算多种相关系数,包括Pearson相关系数、Spearman相关系数、Kendall相关系数、偏 # 相关系数、多分格(polychoric)相关系数和多系列(polyserial)相关系数。 # # 1. Pearson、Spearman和Kendall相关 # Pearson积差相关系数衡量了两个定量变量之间的线性相关程度。Spearman等级相关系数则衡 # 量分级定序变量之间的相关程度。Kendall’s Tau相关系数也是一种非参数的等级相关度量。 # cor()函数可以计算这三种相关系数,而cov()函数可用来计算协方差。 cor(x,use = ,method = ) # # x 矩阵或数据框 # use 指定缺失数据的处理方式。可选的方式为all.obs(假设不存在缺失数据——遇到缺失数据时将报 # 错)、everything(遇到缺失数据时,相关系数的计算结果将被设为missing)、complete.obs # (行删除)以及 pairwise.complete.obs(成对删除,pairwise deletion) # method 指定相关系数的类型。可选类型为pearson、spearman或kendall # # 协方差和相关系数 states<-state.x77[,1:6] cov(states) # # > cov(states) # Population Income Illiteracy Life Exp Murder # Population .7588 .7796 292. -407. 5663. # Income .7796 .3061 -163. 280. -521. # Illiteracy 292.8680 -163.7020 0. -0. 1. # Life Exp -407.8425 280.6632 -0. 1. -3. # Murder 5663.5237 -521.8943 1. -3. 13. # HS Grad -3551.5096 3076.7690 -3. 6. -14. # HS Grad # Population -3551. # Income 3076. # Illiteracy -3. # Life Exp 6. # Murder -14. # HS Grad 65. cor(states) cor(states,method = "spearman") # # > cor(states,method = "spearman") # Population Income Illiteracy Life Exp Murder HS Grad # Population 1.0000000 0. 0. -0. 0. -0. # Income 0. 1.0000000 -0. 0. -0. 0. # Illiteracy 0. -0. 1.0000000 -0. 0. -0. # Life Exp -0. 0. -0. 1.0000000 -0. 0. # Murder 0. -0. 0. -0. 1.0000000 -0. # HS Grad -0. 0. -0. 0. -0. 1.0000000 # # # 首个语句计算了方差和协方差,第二个语句则计算了Pearson积差相关系数,而第三个语句计算 # 了Spearman等级相关系数。举例来说,我们可以看到收入和高中毕业率之间存在很强的正相关, # 而文盲率和预期寿命之间存在很强的负相关 # # 请注意,在默认情况下得到的结果是一个方阵(所有变量之间两两计算相关)。你同样可以 # 计算非方形的相关矩阵 # 当你对某一组变量与另外一组变量之间的关系感兴趣时,cor()函数的这种用法是非常实用 # 的。注意,上述结果并未指明相关系数是否显著不为0(即,根据样本数据是否有足够的证据得 # 出总体相关系数不为0的结论)。由于这个原因,你需要对相关系数进行显著性检验( # # 2. 偏相关 # 偏相关是指在控制一个或多个定量变量时,另外两个定量变量之间的相互关系。你可以使用 # ggm包中的pcor()函数计算偏相关系数。ggm包没有被默认安装,在第一次使用之前需要先进行 # 安装。函数调用格式为:pcor(u,s)其中的u是一个数值向量,前两个数值表示要计算相关系数的变量下标,其余的数值为条件变量 # (即要排除影响的变量)的下标。S为变量的协方差阵。 library(ggm) pcor(c(1,5,2,3,6),cov(states)) # > pcor(c(1,5,2,3,6),cov(states)) # [1] 0. # 本例中,在控制了收入、文盲率和高中毕业率的影响时,人口和谋杀率之间的相关系数为 # 0.346。偏相关系数常用于社会科学的研究中。 # # 3. 其他类型的相关 # polycor包中的hetcor()函数可以计算一种混合的相关矩阵,其中包括数值型变量的 # Pearson积差相关系数、数值型变量和有序变量之间的多系列相关系数、有序变量之间的多分格相 # 关系数以及二分变量之间的四分相关系数。多系列、多分格和四分相关系数都假设有序变量或二 # 分变量由潜在的正态分布导出。请 # # 相关性的显著性检验 # 在计算好相关系数以后,如何对它们进行统计显著性检验呢?常用的原假设为变量间不相关(即总体的相关系数为0)。 # # cor.test()函数对单个的Pearson、Spearman和Kendall相 # 关系数进行检验:cor.test(x,y,alternative=,method=) # 其中的x和y为要检验相关性的变量,alternative则用来指定进行双侧检验或单侧检验(取值 # 为"two.side"、"less"或"greater"),而method用以指定要计算的相关类型("pearson"、 # "kendall"或"spearman")。 #当研究的假设为总体的相关系数小于0时,请使用alternative="less" # 在研究的假设为总体的相关系数大于0时,应使用alternative="greater"。 #默认情况下:为alternative="two.side"(总体相关系数不等于0) cor.test(states[,3],states[,5]) # # > cor.test(states[,3],states[,5]) # # Pearson's product-moment correlation # # data: states[, 3] and states[, 5] # t = 6.8479, df = 48, p-value = 1.258e-08 # alternative hypothesis: true correlation is not equal to 0 # 95 percent confidence interval: # 0. 0. # sample estimates: # cor # 0. # # 这段代码检验了预期寿命和谋杀率的Pearson相关系数为0的原假设。假设总体的相关度为0, # 则预计在一千万次中只会有少于一次的机会见到0.703这样大的样本相关度(即p = 1.258e08)。 # 由于这种情况几乎不可能发生,所以你可以拒绝原假设,从而支持了要研究的猜想,即预期寿命 # 和谋杀率之间的总体相关度不为0。 # # 遗憾的是,cor.test每次只能检验一种相关关系。但幸运的是,psych包中提供的 # corr.test()函数可以一次做更多事情。。corr.test()函数可以为Pearson、Spearman或Kendall #相关计算相关矩阵和显著性水平 # # corr.test计算相关矩阵并进行显著性检验 corr.test(states,use = "complete") # # > corr.test(states,use = "complete") # Call:corr.test(x = states, use = "complete") # Correlation matrix # Population Income Illiteracy Life Exp Murder HS Grad # Population 1.00 0.21 0.11 -0.07 0.34 -0.10 # Income 0.21 1.00 -0.44 0.34 -0.23 0.62 # Illiteracy 0.11 -0.44 1.00 -0.59 0.70 -0.66 # Life Exp -0.07 0.34 -0.59 1.00 -0.78 0.58 # Murder 0.34 -0.23 0.70 -0.78 1.00 -0.49 # HS Grad -0.10 0.62 -0.66 0.58 -0.49 1.00 # Sample Size # [1] 50 # Probability values (Entries above the diagonal are adjusted for multiple tests.) # Population Income Illiteracy Life Exp Murder HS Grad # Population 0.00 0.59 1.00 1.0 0.10 1 # Income 0.15 0.00 0.01 0.1 0.54 0 # Illiteracy 0.46 0.00 0.00 0.0 0.00 0 # Life Exp 0.64 0.02 0.00 0.0 0.00 0 # Murder 0.01 0.11 0.00 0.0 0.00 0 # HS Grad 0.50 0.00 0.00 0.0 0.00 0 # # To see confidence intervals of the correlations, print with the short=FALSE option # 参数use=的取值可为"pairwise"或"complete"(分别表示对缺失值执行成对删除或行删 # 除)。参数method=的取值可为"pearson"(默认值)、"spearman"或"kendall"。人口数 # 量和高中毕业率的相关系数(-0.10)并不显著地不为0(p = 0.5) # # 其他显著性检验 # 在7.4.1节中,我们关注了偏相关系数。在多元正态性的假设下,psych包中的pcor.test() # 函数①可以用来检验在控制一个或多个额外变量时两个变量之间的条件独立性。使用格式为: # 其中的r是由pcor()函数计算得到的偏相关系数,q为要控制的变量数(以数值表示位置),n为 # 样本大小。 # 在结束这个话题之前应当指出的是,psych包中的r.test()函数提供了多种实用的显著性 # 检验方法。此函数可用来检验: # 某种相关系数的显著性; # 两个独立相关系数的差异是否显著; # 两个基于一个共享变量得到的非独立相关系数的差异是否显著; # 两个基于完全不同的变量得到的非独立相关系数的差异是否显著。补充知识:
一 、相关性和显著性的关系:
1 关系的显著性(the significance of the relationship):指两(或多)变量之间关系的统计显著水平,一般要求p < 0.05。这是解释的第一步,如果不显著(p > 0.05)、不管其相关系数(回归系数或其它描述关系强度的统计量)多强(这在小样本的情况下会发生),都没有继续讨论的意义,因为在总体中这种关系存在的可能性很低,如接受这种关系的风险太大(即Type I错误)。
2. 关系的强度(the strength of the relationship):指相关系数(或其它类似统计量)的大小。以相关系数为例,一般认为0.3以下为弱相关、0.3-0.7之间为中相关、0.7-1.0为强相关。这种分类也适用于其它标准化统计量(如标准回归系数, standardized regression coefficient,在SPSS中叫BETA)。大家知道,这些标准化的统计量的平方描述了两(或多)个变量之间的重合部分(如我最近详细解释的回归模型R2描述了自变量对因变量的解释部分),从那个角度来看,弱相关的变量之间的重合不到10%、中相关变量之间的重合在10-50%,强相关变量之间的重合在50%以上。
3. 关系的方向(the direction of the relationship):指相关系数(或其它类似统计量)的正负符号。如果原先的假设是单尾(one-tailed),如“上网会减少社交时间”、“上网会增加孤独感”等,那么其相关系数的方向就十分重要。(从可证伪性原则来看,单尾假设比双尾假设更好。)当一对变量的关系是显著并强烈、但是其方向与假设相反,该研究假设也必须被拒绝。当然研究者应该深入分析这种情况为何会发生。
4. 关系的形式(the form of the relationship):指变量之间的关系是线性(linear)还是非线性(nonlinear)。上述统计量描述的都是线性关系,如果不显著、显著而弱、显著并强烈但反方向,也许其真正的关系不是线性而是非线性,所以我们不能简单地收工回家,而要探索其非线性关系。当然,后者更复杂、对于没有良好的理论和方法训练的研究者更是容易掉进种种陷阱。
二 、只有显著性水平显著时,相关系数才是可信的
也就说只看相关系数是说明不了问题的,还得看显著性,而且还是显著性水平显著的时候,就可以说明相关系数论证的点可信的,我们知道相关系数有以下含义:
这里,

,

是一个可以表征

和

之间线性关系紧密程度的量。它具有两个性质:
(1)
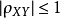
(2)

的充要条件是,存在常数a,b,使得
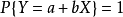
由性质衍生:
a. 相关系数定量地刻画了 X 和 Y的相关程度,即

越大,相关程度越大;
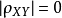
对应相关程度最低;
b. X 和Y 完全相关的含义是在概率为1的意义下存在线性关系,于是
是一个可以表征X 和Y 之间线性关系紧密程度的量。当
较大时,通常说X 和Y相关程度较好;当
较小时,通常说X 和Y相关程度较差;当X和Y不相关,通常认为X和Y之间不存在线性关系,但并不能排除X和Y之间可能存在其他关系。
若X和Y不相关,
,通常认为X和Y之间不存在线性关系,但并不能排除X和Y之间可能存在其他关系;若
,则X和Y不相关。若X和Y独立,则必有
,因而X和Y不相关;若X和Y不相关,则仅仅是不存在线性关系,可能存在其他关系,如

,X和Y不独立。
看例图:
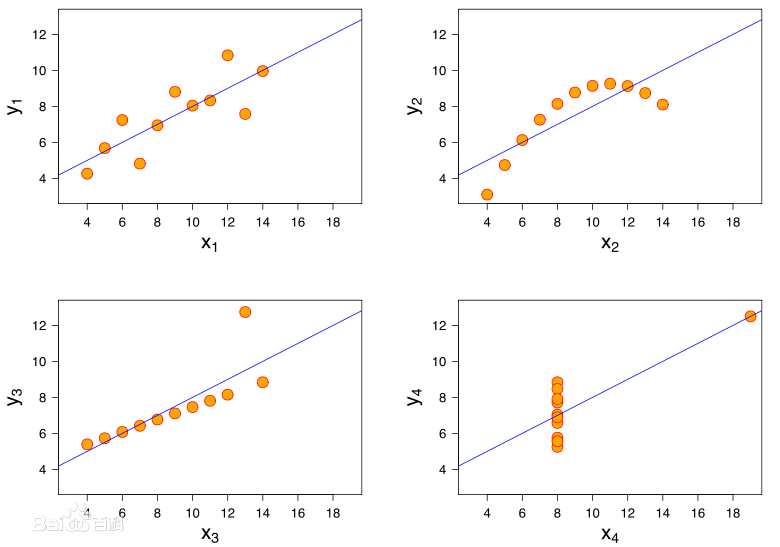
显著系数P:
P值即概率,反映某一事件发生的可能性大小。统计学根据显著性检验方法所得到的P 值,一般以P < 0.05 为有统计学差异, P<0.01 为有显著统计学差异,P<0.001为有极其显著的统计学差异。
|
P值 |
碰巧的概率 |
对无效假设 |
统计意义 |
|
P>0.05 |
碰巧出现的可能性大于5% |
不能否定无效假设 |
两组差别无显著意义 |
|
P<0.05 |
碰巧出现的可能性小于5% |
可以否定无效假设 |
两组差别有显著意义 |
|
P <0.01 |
碰巧出现的可能性小于1% |
可以否定无效假设 |
两者差别有非常显著意义 |
.
看看知乎上的解释:https://www.zhihu.com/question//answer/
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/221025.html原文链接:https://javaforall.net


