
当用于训练的数据量非常大时,批量梯度下降算法变得不再适用(此时其速度会非常慢),为解决这个问题,人们又想出了随机梯度下降算法。随机梯度下降算法的核心思想并没有变,它仍是基于梯度,通过对目标函数中的参数不断迭代更新,使得目标函数逐渐靠近最小值。
具体代码实现如下:
先导入要用到的各种包:
%matplotlib notebook import pandas as pd import matplotlib.pyplot as plt import numpy as np读入数据并查看数据的相关信息:
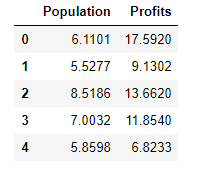
data = pd.read_csv('ex1data1.txt',header = None,names=['Population','Profits']) data.head() # 查看data中的前五条数据data中前五条数据如下图所示:

data.describe() # 查看data的各描述统计量信息绘制原始数据的散点图:
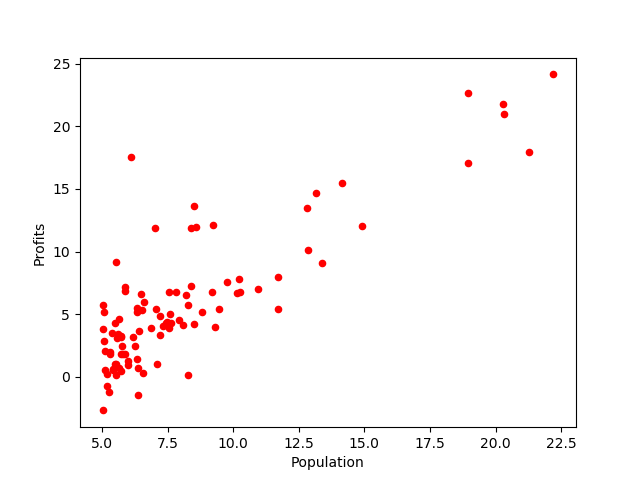
fig,axes = plt.subplots() data.plot(kind='scatter',x='Population',y='Profits',ax=axes,marker='o',color='r') axes.set(xlabel='Population',ylabel='Profits') fig.savefig('p1.png')绘制的散点图为:
向data中添加一列便于矩阵计算的辅助列:
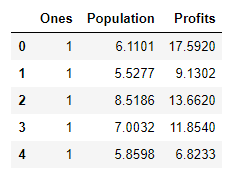
data.insert(0,'Ones',1) data.head()加入辅助列的data如下所示:
随机梯度下降的实现:
# 定义数据特征和标签的提取函数: def get_fea_lab(data): cols = data.shape[1] X = data.iloc[:,0:cols-1] # X是data中的前两列(不包括索引列) y = data.iloc[:,cols-1:cols] # y是data中的最后一列 # 将X和y都转化成矩阵的形式: X = np.matrix(X.values) y = np.matrix(y.values) return X,y # 定义代价函数: def computeCost(data,theta,i): X,y = get_fea_lab(data) inner = np.power(((X*theta.T)-y),2) return (float(inner[i]/2)) # 定义随机梯度下降函数: def stochastic_gradient_descent(data,theta,alpha,epoch): X0,y0 = get_fea_lab(data) # 提取X和y矩阵 temp = np.matrix(np.zeros(theta.shape)) parameters = int(theta.shape[1]) cost = np.zeros(len(X0)) avg_cost = np.zeros(epoch) for k in range(epoch): new_data = data.sample(frac=1) # 打乱数据 X,y = get_fea_lab(new_data) # 提取新的X和y矩阵 for i in range(len(X)): error = X[i:i+1]*theta.T-y[i] cost[i] = computeCost(new_data,theta,i) for j in range(parameters): temp[0,j] = theta[0,j] - alpha*error*X[i:i+1,j] theta = temp avg_cost[k] = np.average(cost) return theta,avg_cost # 初始化学习率、迭代轮次和参数theta: alpha = 0.001 epoch = 200 theta = np.matrix(np.array([0,0])) # 调用随机梯度下降函数来计算线性回归中的theat参数: g,avg_cost = stochastic_gradient_descent(data,theta,alpha,epoch) # g的值为matrix([[-3., 1.]])绘制每轮迭代中代价函数的平均值与迭代轮次的关系图像:
本例中因为数据集中一共只有97个样本,所以对于每轮迭代,我选择的是计算所有样本对应的的代价函数的平均值。在数据集非常大的情况下,我们可以选择计算每轮迭代中最后一部分样本对应的代价函数的平均值。
fig, axes = plt.subplots() axes.plot(np.arange(epoch), avg_cost, 'r') axes.set_xlabel('Epoch') axes.set_ylabel('avg_cost') axes.set_title('avg_cost vs. Epoch') fig.savefig('p2.png')具体如下图所示:
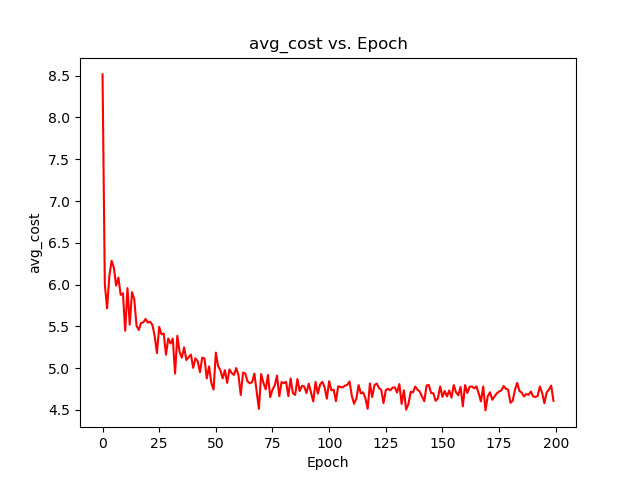
从上图中我们可以看到,大约从第90轮迭代开始,代价函数的平均值在某个值上下进行小范围波动(某个值其实就是值全局最小值)。前面,我们把最大迭代轮次设为了200,并据此计算除了线性回归参数theta的值为matrix([[-3., 1.]])。而用正规方程计算出的theta参数的精确值为matrix([[-3.],[ 1.]]),二者的差别在可接受范围内。关于用正规方程求解线性回归参数可以参考:https://blog.csdn.net/_/article/details/、https://blog.csdn.net/_/article/details/。
根据前文计算出的theta参数值,绘制原始数据的线性拟合图:
x = np.linspace(data.Population.min(),data.Population.max(),100) f = g[0,0] + g[0,1]*x fig,axes = plt.subplots() axes.plot(x,f,'r',label='Fitted') axes.scatter(x=data.Population,y=data.Profits,label='Trainning data') axes.legend(loc='best') axes.set(xlabel='Population',ylabel='Profits',title='Population vs. Profits') fig.savefig('p3.png')绘制的线性拟合图为:
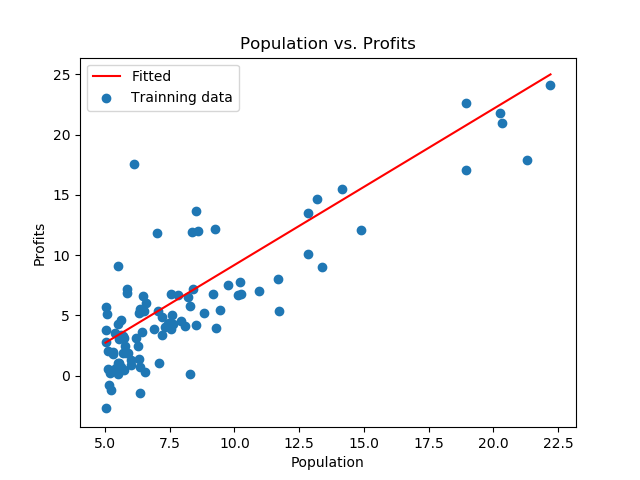
批量梯度下降算法与随机梯度下降算法的比较:
1)批量梯度下降算法在每次迭代更新目标函数的参数时,是将训练数据集中的所有样本都考虑进去,以此计算代价函数;而随机梯度下降算法在每次迭代更新目标函数的参数时,只考虑数据集中的一个样本并据此计算代价函数。因此,当训练数据集非常大时,随机梯度下降的迭代速度要比批量梯度下降的迭代速度快很多。
两者的代价函数具体如下图所示:
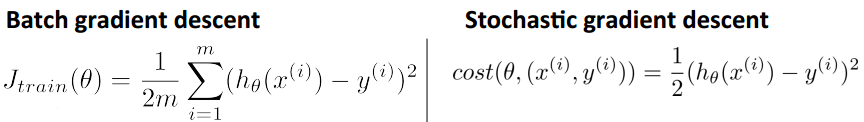
上图中,左边是批量梯度下降的代价函数,右边是随机梯度下降的代价函数。
2)不同于批量梯度下降,当迭代到一定轮次时,随机梯度下降计算出的代价函数是在某个靠近全局最小值的区域内徘徊,而不是直接逼近全局最小值并停留在那点。关于随机梯度下降的收敛性,可以参考:https://www.zhihu.com/question/。
其他参考资料:
《Python Machine Learning Second Edition》——Vahid Mirjalili&Sebastian Raschka
Andew Ng机器学习公开课
https://blog.csdn.net/_/article/details/
PS:本文为博主原创文章,转载请注明出处。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/223292.html原文链接:https://javaforall.net


