
1.程序内存分区中的堆与栈
1.1栈简介
栈由操作系统自动分配释放 ,用于存放函数的参数值、局部变量等,其操作方式类似于数据结构中的栈。参考如下代码:
int main() { int b; //栈 char s[] = "abc"; //栈 char *p2; //栈 }- 1
- 2
- 3
- 4
- 5
- 6
其中函数中定义的局部变量按照先后定义的顺序依次压入栈中,也就是说相邻变量的地址之间不会存在其它变量。栈的内存地址生长方向与堆相反,由高到底,所以后定义的变量地址低于先定义的变量,比如上面代码中变量s的地址小于变量b的地址,p2地址小于s的地址。栈中存储的数据的生命周期随着函数的执行完成而结束。
1.2堆简介
堆由程序员分配释放, 若程序员不释放,程序结束时由OS回收,分配方式倒是类似于链表。参考如下代码:
int main() { //C中使用malloc函数申请 char* p1 = (char *)malloc(10); cout<<(int*)p1<
//输出:00000000003BA0C0
//使用free()释放
free(p1);
//C++中用new运算符申请
char p2 =
new
char[
10];
cout<<(
int*)p2<
//输出:00000000003BA0C0
//使用delete运算符释放
delete[] p2; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
其中p1所指的10字节的内存空间与p2所指的10字节内存空间都是存在于堆的。堆的内存地址生长方向与栈相反,由低到高,但需要注意的是,后申请的内存空间并不一定在先申请的内存空间的后面,即p2指向的地址并不一定大于p1所指向的内存地址,原因是先申请的内存空间一旦被释放,后申请的内存空间则会利用先前被释放的内存,从而导致先后分配的内存空间在地址上不存在先后关系。堆中存储的数据的若未释放,则其生命周期等同于程序的生命周期。
关于堆上内存空间的分配过程,首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻 找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
2.3堆与栈区别
从以上可以看到,堆和栈相比,由于大量malloc()/free()或new/delete的使用,容易造成大量的内存碎片,并且可能引发用户态和核心态的切换,效率较低。栈相比于堆,在程序中应用较为广泛,最常见的是函数的调用过程由栈来实现,函数返回地址、EBP、实参和局部变量都采用栈的方式存放。虽然栈有众多的好处,但是由于和堆相比不是那么灵活,有时候分配大量的内存空间,主要还是用堆。
无论是堆还是栈,在内存使用时都要防止非法越界,越界导致的非法内存访问可能会摧毁程序的堆、栈数据,轻则导致程序运行处于不确定状态,获取不到预期结果,重则导致程序异常崩溃,这些都是我们编程时与内存打交道时应该注意的问题。
2.数据结构中的堆与栈
数据结构中,堆与栈是两个常见的数据结构,理解二者的定义、用法与区别,能够利用堆与栈解决很多实际问题。
2.1栈简介
栈是一种运算受限的线性表,其限制是指只仅允许在表的一端进行插入和删除操作,这一端被称为栈顶(Top),相对地,把另一端称为栈底(Bottom)。把新元素放到栈顶元素的上面,使之成为新的栈顶元素称作进栈、入栈或压栈(Push);把栈顶元素删除,使其相邻的元素成为新的栈顶元素称作出栈或退栈(Pop)。这种受限的运算使栈拥有“先进后出”的特性(First In Last Out),简称FILO。
栈分顺序栈和链式栈两种。栈是一种线性结构,所以可以使用数组或链表(单向链表、双向链表或循环链表)作为底层数据结构。使用数组实现的栈叫做顺序栈,使用链表实现的栈叫做链式栈,二者的区别是顺序栈中的元素地址连续,链式栈中的元素地址不连续。
栈的基本操作包括初始化、判断栈是否为空、入栈、出栈以及获取栈顶元素等。下面以顺序栈为例,使用C语言给出一个简单的实现。
#include
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
运行上面的程序,输出结果:
当前栈中的元素: 7 5 4 top element is 7 pop top element is 7- 1
- 2
- 3
- 4
2.2堆简介
2.2.1堆的性质
堆的存储一般都用数组来存储堆,i结点的父结点下标就为(i–1)/2(i–1)/2。它的左右子结点下标分别为 2∗i+12∗i+1 和 2∗i+22∗i+2。如第0个结点左右子结点下标分别为1和2。 
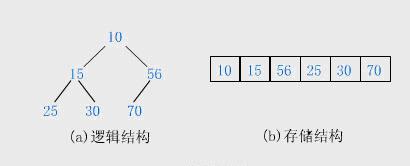
2.2.2堆的基本操作
2.2.3堆操作实现
//新加入i结点,其父结点为(i-1)/2 //参数:a:数组,i:新插入元素在数组中的下标 void minHeapFixUp(int a[], int i) { int j, temp; temp = a[i]; j = (i-1)/2; //父结点 while (j >= 0 && i != 0) { if (a[j] <= temp)//如果父节点不大于新插入的元素,停止寻找 break; a[i]=a[j]; //把较大的子结点往下移动,替换它的子结点 i = j; j = (i-1)/2; } a[i] = temp; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
因此,插入数据到最小堆时:
//在最小堆中加入新的数据data //a:数组,index:插入的下标, void minHeapAddNumber(int a[], int index, int data) { a[index] = data; minHeapFixUp(a, index); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
调整时先在左右儿子结点中找最小的,如果父结点不大于这个最小的子结点说明不需要调整了,反之将最小的子节点换到父结点的位置。此时父节点实际上并不需要换到最小子节点的位置,因为这不是父节点的最终位置。但逻辑上父节点替换了最小的子节点,然后再考虑父节点对后面的结点的影响。相当于从根结点将一个数据的“下沉”过程。下面给出代码:
//a为数组,从index节点开始调整,len为节点总数 从0开始计算index节点的子节点为 2*index+1, 2*index+2,len/2-1为最后一个非叶子节点 void minHeapFixDown(int a[],int len,int index) { if(index>(len/2-1))//index为叶子节点不用调整 return; int tmp=a[index]; lastIndex=index; while(index<=len/2-1) //当下沉到叶子节点时,就不用调整了 { if(a[2*index+1]
//如果左子节点小于待调整节点 { lastIndex =
2*
index+
1; }
//如果存在右子节点且小于左子节点和待调整节点
if(
2*
index+
2
2*
index+
2]
2*
index+
1]&& a[
2*
index+
2]
2*
index+
2; }
//如果左右子节点有一个小于待调整节点,选择最小子节点进行上浮
if(lastIndex!=
index) { a[
index]=a[lastIndex];
index=lastIndex; }
else
break;
//否则待调整节点不用下沉调整 } a[lastIndex]=tmp;
//将待调整节点放到最后的位置 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
根据思想,可以有不同版本的代码实现,以上是和孙凛同学一起讨论出的一个版本,在这里感谢他的参与,读者可另行给出。个人体会,这里建议大家根据对堆调整过程的理解,写出自己的代码,切勿看示例代码去理解算法,而是理解算法思想写出代码,否则很快就会忘记。
写出堆化数组的代码:
//建立最小堆 //a:数组,n:数组长度 void makeMinHeap(int a[], int n) { for (int i = n/2-1; i >= 0; i--) minHeapFixDown(a, i, n); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
2.2.4 堆的具体应用——堆排序
堆排序(Heapsort)是堆的一个经典应用,有了上面对堆的了解,不难实现堆排序。由于堆也是用数组来存储的,故对数组进行堆化后,第一次将A[0]与A[n – 1]交换,再对A[0…n-2]重新恢复堆。第二次将A[0]与A[n – 2]交换,再对A[0…n – 3]重新恢复堆,重复这样的操作直到A[0]与A[1]交换。由于每次都是将最小的数据并入到后面的有序区间,故操作完成后整个数组就有序了。有点类似于直接选择排序。
因此,完成堆排序并没有用到前面说明的插入操作,只用到了建堆和节点向下调整的操作,堆排序的操作如下:
//array:待排序数组,len:数组长度 void heapSort(int array[],int len) { //建堆 makeMinHeap(array,len); //最后一个叶子节点和根节点交换,并进行堆调整,交换次数为len-1次 for(int i=len-1;i>0;--i) { //最后一个叶子节点交换 array[i]=array[i]+array[0]; array[0]=array[i]-array[0]; array[i]=array[i]-array[0]; //堆调整 minHeapFixDown(array, 0, len-i-1); } } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
最坏情况:如果待排序数组是有序的,仍然需要O(N * logN)复杂度的比较操作,只是少了移动的操作;
最好情况:如果待排序数组是逆序的,不仅需要O(N * logN)复杂度的比较操作,而且需要O(N * logN)复杂度的交换操作。总的时间复杂度还是O(N * logN)。
因此,堆排序和快速排序在效率上是差不多的,但是堆排序一般优于快速排序的重要一点是数据的初始分布情况对堆排序的效率没有大的影响。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/224082.html原文链接:https://javaforall.net


