
一、kmeans聚类算法介绍:
kmeans算法是一种经典的无监督机器学习算法,名列数据挖掘十大算法之一。作为一个非常好用的聚类算法,kmeans的思想和实现都比较简单。kmeans的主要思想:把数据划分到各个区域(簇),使得数据与区域中心的距离之和最小。换个角度来说,kmeans算法把数据量化为聚类中心,其目标函数就是使量化过程中损失的“信息”最少。kmeans算法求解目标函数的过程也可以看做是EM(Expectation maximization)迭代优化。
二、kmeans目标函数及优化:
定义:数据集 XN×D ,聚类中心 UK×D ,指示矩阵 rN×K 。
其中 rnk=1 如果第n个样本属于第k个聚类,否则 rnk=0 。kmeans 聚类算法的目标是让数据与相应的聚类中心的距离之和最小:
迭代优化:未知变量是两个矩阵–聚类中心 UK×D 和指示矩阵 rN×K ,直接进行优化太困难(NP问题),所以需要迭代优化这两个变量来得到一个局部最优解。
1、固定聚类中心 UK×D ,优化指示矩阵 rN×K :如果第n个样本距离第k个聚类最近,则赋值 rnk=1 ,否则赋值 rnk=0 。
2、固定指示矩阵 rN×K ,优化聚类中心 UK×D :拆分目标函数,分开优化每一个聚类中心(聚类中心之间没有耦合关系),推导如下
从EM角度来看:把指示矩阵 rN×K 当做隐变量,聚类中心 UK×D 当做模型参数,更新 rN×K 和 UK×D 就分别对应于EM算法的E步和M步。
三、判停标准:
kmeans算法的迭代优化过程一直持续直到满足某个判停标准,如果在这一轮迭代中:
满足其中一个条件,即可停止训练。如果满足条件1或2,说明算法已经收敛。
四、K值的选取:
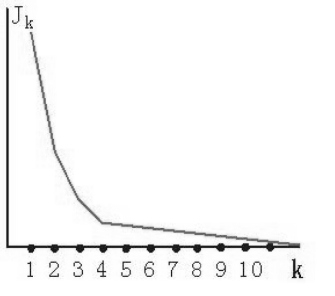

五、matlab计算数据与聚类中心之间的距离
matlab诞生的初衷就是为了矩阵运算的方便,所以如果用for循环来计算数据与聚类中心的距离从而得到指示矩阵 rN×K 这种速度极慢的方法是不可取的。对欧氏距离函数做个小小的变换:
matlab代码(借鉴一下大牛的代码):
function n2 = sp_dist2(x, c) % DIST2 Calculates squared distance between two sets of points. % Adapted from Netlab neural network software: % http://www.ncrg.aston.ac.uk/netlab/index.php % % Description % D = DIST2(X, C) takes two matrices of vectors and calculates the % squared Euclidean distance between them. Both matrices must be of % the same column dimension. If X has M rows and N columns, and C has % L rows and N columns, then the result has M rows and L columns. The % I, Jth entry is the squared distance from the Ith row of X to the % Jth row of C. % % % Copyright (c) Ian T Nabney (1996-2001) [ndata, dimx] = size(x); [ncentres, dimc] = size(c); if dimx ~= dimc error('Data dimension does not match dimension of centres') end n2 = (ones(ncentres, 1) * sum((x.^2)', 1))' + ... ones(ndata, 1) * sum((c.^2)',1) - ... 2.*(x*(c')); % Rounding errors occasionally cause negative entries in n2 if any(any(n2<0)) n2(n2<0) = 0; end 六、matlab实现kmeans
kmeans聚类算法实现:
function [centres, options, post, errlog] = sp_kmeans(centres, data, options) % KMEANS Trains a k means cluster model. % Adapted from Netlab neural network software: % http://www.ncrg.aston.ac.uk/netlab/index.php % % Description % CENTRES = KMEANS(CENTRES, DATA, OPTIONS) uses the batch K-means % algorithm to set the centres of a cluster model. The matrix DATA % represents the data which is being clustered, with each row % corresponding to a vector. The sum of squares error function is used. % The point at which a local minimum is achieved is returned as % CENTRES. The error value at that point is returned in OPTIONS(8). % % [CENTRES, OPTIONS, POST, ERRLOG] = KMEANS(CENTRES, DATA, OPTIONS) % also returns the cluster number (in a one-of-N encoding) for each % data point in POST and a log of the error values after each cycle in % ERRLOG. The optional parameters have the following % interpretations. % % OPTIONS(1) is set to 1 to display error values; also logs error % values in the return argument ERRLOG. If OPTIONS(1) is set to 0, then % only warning messages are displayed. If OPTIONS(1) is -1, then % nothing is displayed. % % OPTIONS(2) is a measure of the absolute precision required for the % value of CENTRES at the solution. If the absolute difference between % the values of CENTRES between two successive steps is less than % OPTIONS(2), then this condition is satisfied. % % OPTIONS(3) is a measure of the precision required of the error % function at the solution. If the absolute difference between the % error functions between two successive steps is less than OPTIONS(3), % then this condition is satisfied. Both this and the previous % condition must be satisfied for termination. % % OPTIONS(14) is the maximum number of iterations; default 100. % % Copyright (c) Ian T Nabney (1996-2001) [ndata, data_dim] = size(data); [ncentres, dim] = size(centres); if dim ~= data_dim error('Data dimension does not match dimension of centres') end if (ncentres > ndata) error('More centres than data') end % Sort out the options if (options(14)) niters = options(14); else niters = 100; end store = 0; if (nargout > 3) store = 1; errlog = zeros(1, niters); end % Check if centres and posteriors need to be initialised from data if (options(5) == 1) % Do the initialisation perm = randperm(ndata); perm = perm(1:ncentres); % Assign first ncentres (permuted) data points as centres centres = data(perm, :); end % Matrix to make unit vectors easy to construct id = eye(ncentres); % Main loop of algorithm for n = 1:niters % Save old centres to check for termination old_centres = centres; % Calculate posteriors based on existing centres d2 = sp_dist2(data, centres); % Assign each point to nearest centre [minvals, index] = min(d2', [], 1); post = id(index,:); num_points = sum(post, 1); % Adjust the centres based on new posteriors for j = 1:ncentres if (num_points(j) > 0) centres(j,:) = sum(data(find(post(:,j)),:), 1)/num_points(j); end end % Error value is total squared distance from cluster centres e = sum(minvals); if store errlog(n) = e; end if options(1) > 0 fprintf(1, 'Cycle %4d Error %11.6f\n', n, e); end if n > 1 % Test for termination if max(max(abs(centres - old_centres))) < options(2) & ... abs(old_e - e) < options(3) options(8) = e; return; end end old_e = e; end % If we get here, then we haven't terminated in the given number of % iterations. options(8) = e; if (options(1) >= 0) disp('Warning: Maximum number of iterations has been exceeded'); end 用法示例:
options = zeros(1,14); options(1) = 1; % display options(2) = 1; options(3) = 0.1; % precision options(5) = 1; % initialization options(14) = 100; % maximum iterations data = random('Normal',0,1,10000,1000); centres = zeros(100, 1000); [centres, options, post, errlog] = sp_kmeans(centres, data, options); Cycle 1 Error . Cycle 2 Error . Cycle 3 Error . Cycle 4 Error . Cycle 5 Error . Cycle 6 Error . Cycle 7 Error . Cycle 8 Error . Cycle 9 Error . Cycle 10 Error . Cycle 11 Error . Cycle 12 Error . Cycle 13 Error . Cycle 14 Error . Cycle 15 Error .019543 Cycle 16 Error . Cycle 17 Error . Cycle 18 Error . 发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/225302.html原文链接:https://javaforall.net


