
摘要
正则化的本质是在Cost Function中添加的p-范数。本文从正则化的本质p-范数入手,解释了L1正则化和L2正则化的区别。
正则化
在Cost Function上添加了正则化项,就能降低模型的过拟合程度,这就是正则化的作用。
关于正则化更细节的讲述,请参考为什么正则化能减少模型过拟合程度。
正则化项的不同,就产生了L1正则化和L2正则化。L1正则化和L2正则化的表达式,其实就是1-范数与2-范数
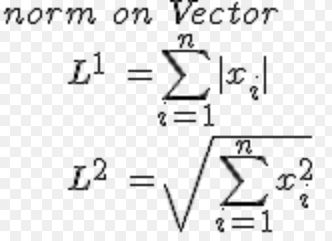

范数
正则化项的实质就是叠加到Cost Function中的范数。下面是p-范数的表达式:
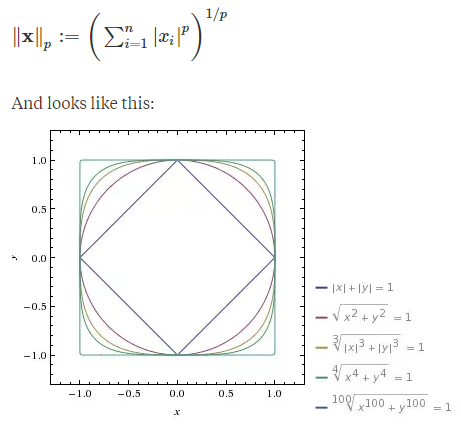
在上图中(x,y)相同的情况下,随着p值的增加,p-范数的值趋向于更大,对较大权重的惩罚力度加大(就是说W大的,p-范数的值也更大,所以表现在Cost Function的值变小)。
L1正则化
下面是整个Cost Function的表达式,红色部分就是L1正则化的表达式。
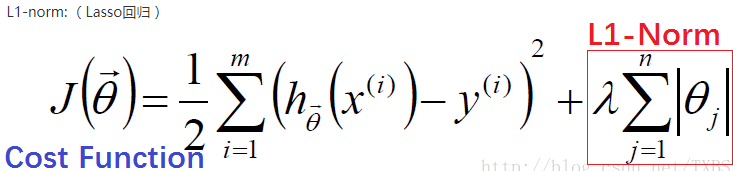
L1正则化对所有参数的惩罚力度都一样,可以让一部分权重变为零,因此产生稀疏模型,能够去除某些特征(权重为0则等效于去除)。
L2正则化
下面是整个Cost Function的表达式,红色部分就是L2正则化的表达式。
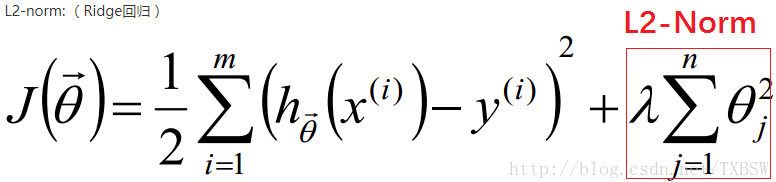
L2正则化减少了权重的固定比例,使权重平滑。L2正则化不会使权重变为0(不会产生稀疏模型),所以选择了更多的特征。
区别
- L1减少的是一个常量,L2减少的是权重的固定比例
- L1使权重稀疏,L2使权重平滑
- L1优点是能够获得sparse模型,对于large-scale的问题来说这一点很重要,因为可以减少存储空间
- L2优点是实现简单,能够起到正则化的作用。缺点就是L1的优点:无法获得sparse模型
参考
- https://blog.csdn.net/ybdesire/article/details/
- https://blog.csdn.net/TXBSW/article/details/
- https://blog.csdn.net/vincent2610/article/details/
- https://www.quora.com/What-is-the-difference-between-L1-and-L2-regularization-How-does-it-solve-the-problem-of-overfitting-Which-regularizer-to-use-and-when
- https://www.zhihu.com/question/
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/225462.html原文链接:https://javaforall.net


