
Python常用数据挖掘的工具包
python对于数据处理非常友好的语言,比如常用的scikit-learn和scipy都可以用来进行机器学习和数据挖掘。同时为了使得结果可视化,Python还提供了非常好用的可视化工具包matplotlib和seaborn。
使用Python进行层次聚类
我们首先用excle的随机函数RAND()生成一个随机数据列表,进行测试,取名为test.xlsx,表格内容如下图所示:

然后就可以开始写代码了,首先需要导入要用到的包:
import pandas as pd import seaborn as sns #用于绘制热图的工具包 from scipy.cluster import hierarchy #用于进行层次聚类,话层次聚类图的工具包 from scipy import cluster import matplotlib.pyplot as plt from sklearn import decomposition as skldec #用于主成分分析降维的包 1. 使用pandas里面的文件读取函数进行
pandas工具包是Python语言中专门进行数据结构化存储和数据分析的工具包,很多其他包都以pandas的结构化数据作为其函数的输入,因此数据处理的第一步大多使用pandas进行数据结构化存储,关于excel文件,pandas就要专门的读取函数read_excel,根据函数的说明文档,我们写下如下读取文件的代码
df = pd.read_excel("test.xlsx",index_col=0) #index_col=0指定数据中第一列是类别名称,PS:计算机程序一般从整数0开始计数,所以0就代表第一列 #df = df.T #python默认每行是一个样本,如果数据每列是一个样本的话,转置一下即可 2. 绘制层次聚类图
读取数据后,我们就可以进行层次聚类图的绘制了,首先进入scipy参考文档页面,然后找到聚类包Clustering package (scipy.cluster)->层次聚类scipy.cluster.hierarchy,在当前页面下,就可以看到所有层次聚类相关的函数了,我们找到可以画图的函数dendrogram,进入该函数的文档页面,发现该函数需要传入的第一个参数是linkage矩阵,这个矩阵需要函数linkage,进入该函数的文档页面我们看到linkage的说明文档上面的函数scipy.cluster.hierarchy.linkage(y, method='single', metric='euclidean', optimal_ordering=False),传入第一个参数是需要进行层次聚类的数据,这里即可用使用开始读取的数据变量df,第二个参数代表层次聚类选用的方法,底下罗列了七种方法,比如:
single方法代表将两个组合数据点中距离最近的两个数据点间的距离作为这两个组合数据点的距离。这种方法容易受到极端值的影响。
两个很相似的组合数据点可能由于其中的某个极端的数据点距离较近而组合在一起。
即两个簇之间的距离使用公式: d ( u , v ) = min ( d i s t ( u [ i ] , v [ j ] ) ) d(u,v) = \min(dist(u[i],v[j])) d(u,v)=min(dist(u[i],v[j])) 计算。complete方法代表与Single Linkage相反,将两个组合数据点中距离最远的两个数据点间的距离作为这两个组合数据点的距离。
Complete Linkage的问题也与Single Linkage相反,两个不相似的组合数据点可能由于其中的极端值距离较远而无法组合在一起。
即两个簇之间的距离使用公式: d ( u , v ) = max ( d i s t ( u [ i ] , v [ j ] ) ) d(u, v) = \max(dist(u[i],v[j])) d(u,v)=max(dist(u[i],v[j])) 计算。average方法代表是计算两个组合数据点中的每个数据点与其他所有数据点的距离。将所有距离的均值作为两个组合数据点间的距离。这种方法计算量比较大,但结果比前两种方法更合理。
即两个簇之间的距离使用公式: d ( u , v ) = ∑ i j d ( u [ i ] , v [ j ] ) ( ∣ u ∣ ∗ ∣ v ∣ ) d(u,v) = \sum_{ij} \frac{d(u[i], v[j])}{(|u|*|v|)} d(u,v)=ij∑(∣u∣∗∣v∣)d(u[i],v[j]) 计算。weighted即两个簇之间的距离使用公式: d ( u , v ) = ( d i s t ( s , v ) + d i s t ( t , v ) ) / 2 d(u,v) = (dist(s,v) + dist(t,v))/2 d(u,v)=(dist(s,v)+dist(t,v))/2 计算。centroid即两个簇之间的距离使用公式: d i s t ( s , t ) = ∥ c s − c t ∥ 2 dist(s,t) = \|c_s-c_t\|_2 dist(s,t)=∥cs−ct∥2 计算。median同centroidward即两个簇之间的距离使用公式: d ( u , v ) = ∣ v ∣ + ∣ s ∣ T d ( v , s ) 2 + ∣ v ∣ + ∣ t ∣ T d ( v , t ) 2 − ∣ v ∣ T d ( s , t ) 2 d(u,v) = \sqrt{\frac{|v|+|s|} {T}d(v,s)^2 + \frac{|v|+|t|} {T}d(v,t)^2 – \frac{|v|} {T}d(s,t)^2} d(u,v)=T∣v∣+∣s∣d(v,s)2+T∣v∣+∣t∣d(v,t)2−T∣v∣d(s,t)2 计算。
第三个参数代表距离计算的方法,即上面方法中的dist()函数具体的计算方式,具体方式可以见这个页面。
然后这里我随便选择两个,然后将返回的结果Z传入dendrogram函数,代码如下:
Z = hierarchy.linkage(df, method ='ward',metric='euclidean') hierarchy.dendrogram(Z,labels = df.index) 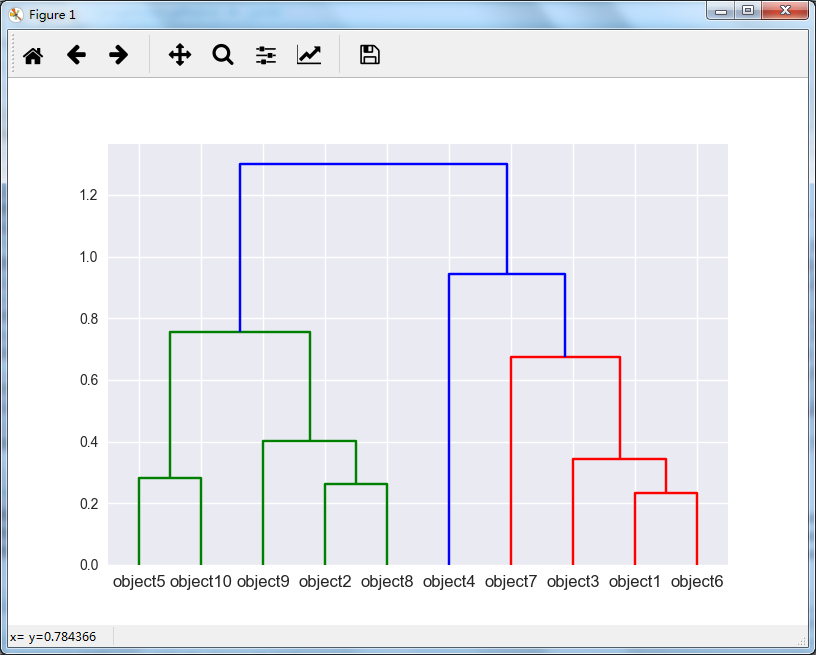
根据上图,我们即可看到在不同的位置裁剪即可得到不同的聚类数目。但是我们具体要聚集多少类呢?
我们先写上裁剪的代码:
label = cluster.hierarchy.cut_tree(Z,height=0.8) label = label.reshape(label.size,) 上面代码中的高度我取的是0.8,根据层次聚类图明显是聚成三类,为啥我要这样取值呢?下一小节给出答案。
3. 绘制两个主成分方向坐标的散点图
#根据两个最大的主成分进行绘图 pca = skldec.PCA(n_components = 0.95) #选择方差95%的占比 pca.fit(df) #主城分析时每一行是一个输入数据 result = pca.transform(df) #计算结果 plt.figure() #新建一张图进行绘制 plt.scatter(result[:, 0], result[:, 1], c=label, edgecolor='k') #绘制两个主成分组成坐标的散点图 for i in range(result[:,0].size): plt.text(result[i,0],result[i,1],df.index[i]) #在每个点边上绘制数据名称 x_label = 'PC1(%s%%)' % round((pca.explained_variance_ratio_[0]*100.0),2) #x轴标签字符串 y_label = 'PC1(%s%%)' % round((pca.explained_variance_ratio_[1]*100.0),2) #y轴标签字符串 plt.xlabel(x_label) #绘制x轴标签 plt.ylabel(y_label) #绘制y轴标签 运行代码,得到下图:
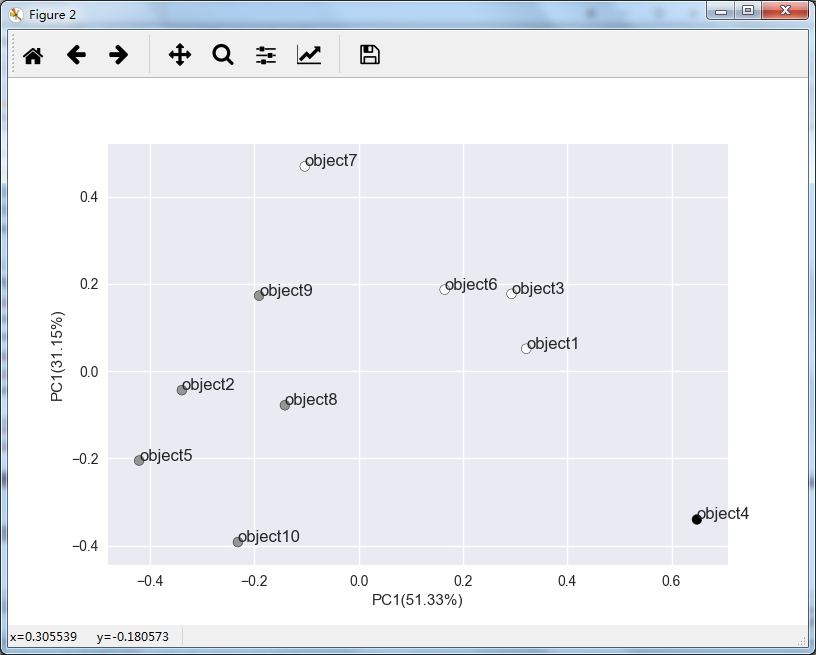
根据改图,我们可以看到大致分为三类比较合理,因此上一小节层次聚类裁剪的高度取了一个可以裁剪得到三类的高度0.8。
4. 绘制热图
热图的绘制非常简单,因为seaborn的工具包非常强大,我们使用clustermap函数即可,该函数的说明文档
中有详细介绍,仅需一行代码,即可搞定,代码如下:
sns.clustermap(df,method ='ward',metric='euclidean') 运行代码,得到下图:

(PS:最近有人问我“层次聚类中最后画的热力图颜色的深浅有什么含义”。注意左上角的颜色图示即可知道,实际上颜色深浅仅仅代表数值,可以和我前面的Excel表格里面的数字进行对照就知道啦~)
最后,本篇的全部代码在下面这个网页可以下载:
下一篇:使用Python进行层次聚类(二)——scipy中层次聚类的自定义距离度量问题
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/226530.html原文链接:https://javaforall.net


