
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
map->reduce
map和reduce之间的过程,成为shuffling,官方图是这样介绍的.(这样描述不是很准确)

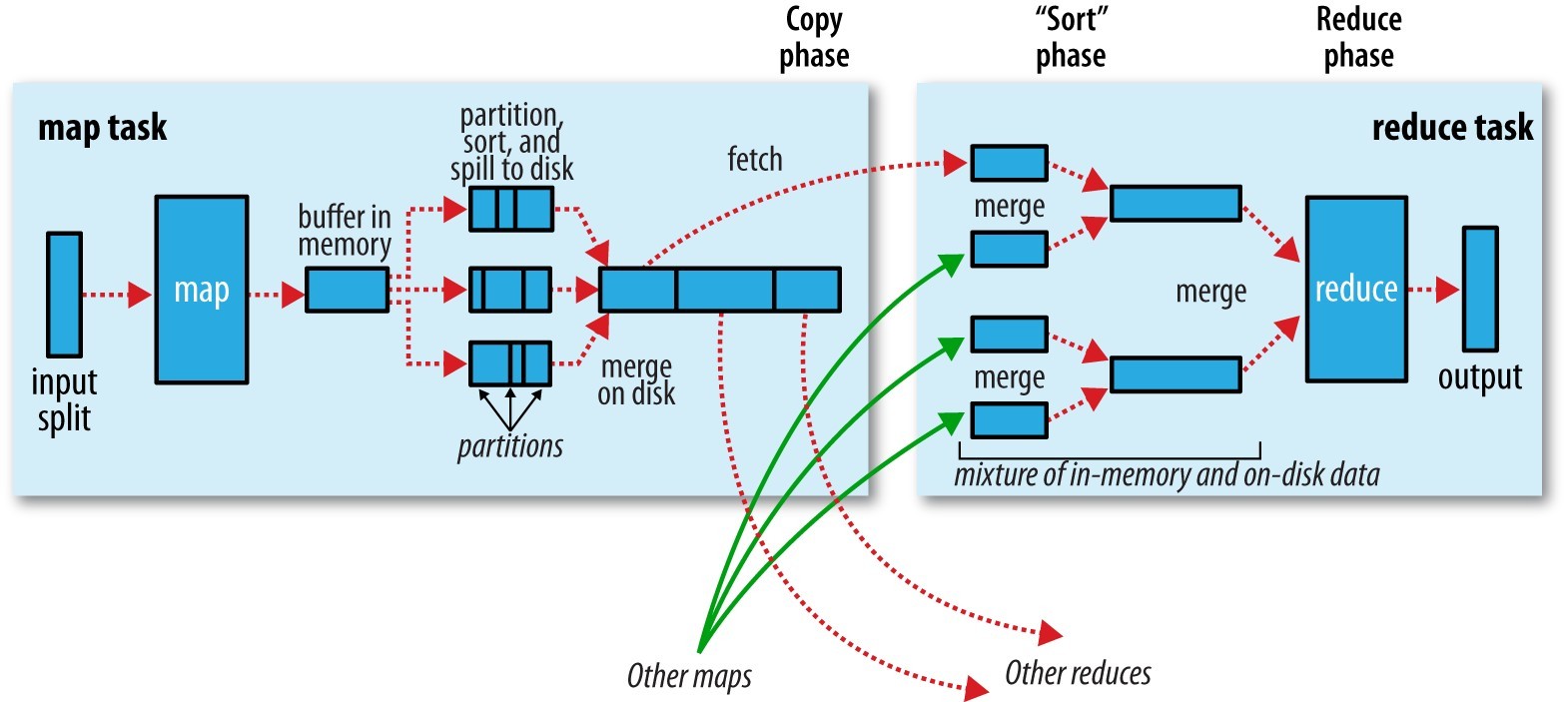
MapTask
每个map任务都有一个环形内存缓冲区用于存储任务的输出.默认100MB(MRJobConfig.IO_SORT_MB修改)
一旦缓冲达到阈值(MRJobConfig.MAP_SORT_SPILL_PERCENT)0.8,后台线程将内容spill到硬盘,将缓缓冲区写到MRJobConfig.JOB_LOCAL_DIR指定目录.
查看MRJobConfig.JOB_LOCAL_DIR值为mapreduce.job.local.dir,查看org.apache.hadoop.mapreduce包下的mapred-default.xml(hadoop-mapreduce-client-core.2.7.1.jar中)文件搜索local.dir,得到配置
<property>
<name>mapreduce.cluster.local.dir</name>
<value>${hadoop.tmp.dir}/mapred/local</value>
<description>The local directory where MapReduce stores intermediate
data files. May be a comma-separated list of
directories on different devices in order to spread disk i/o.
Directories that do not exist are ignored.
</description>
</property>ok,现在从hadoop-common-2.7.1.jar中的core-default.xml中搜索hadoop.tmp.dir
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-${user.name}</value>
<description>A base for other temporary directories.</description>
</property>现在我们得到了spill的临时路径/tmp/hadoop-${user.name}/mapred/local.
在spill之前,首先进行partition,每个分区进行sort,如果有combiner,它就在排序后,执行combiner。
如果溢出文件超过三个(JobContext.MAP_COMBINE_MIN_SPILLS),将会再次执行combiner
MapTask.MapOutputBuffer中源码
if (combinerRunner == null || numSpills < minSpillsForCombine) {
Merger.writeFile(kvIter, writer, reporter, job);
} else {
combineCollector.setWriter(writer);
combinerRunner.combine(kvIter, combineCollector);
}注: map spill到磁盘时,可以设置压缩来节省磁盘和网络IO
设置 MAP_OUTPUT_COMPRESS 为true ,MRJobConfig.MAP_OUTPUT_COMPRESS_CODEC值为codec
例如:
conf.set(MRJobConfig.MAP_OUTPUT_COMPRESS, "true");
conf.set(MRJobConfig.MAP_OUTPUT_COMPRESS_CODEC, "org.apache.hadoop.io.compress.DefaultCodec");
ReduceTask
ReduceTask要从各个MapTask上读取数据,ReduceTask大体流程分为5个阶段。
- Shuffle
ReduceTask从MapTask上远程拷贝数据。超过阈值写道磁盘。 - Merge
ReduceTask启动两个线程,对内存和硬盘数据进行合并。 - Sort
将MapTask的结果归并排序。 - Reduce
用户自定义Reduce -
Write
reduce结果写到HDFS源码分析
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/226581.html原文链接:https://javaforall.net


