
1.概述
2.梯度下降算法
2.1场景假设


2.2梯度下降
梯度下降的基本过程就和下山的场景很类似。
2.2.1微分
看待微分的意义,可以有不同的角度,最常用的两种是:
1)函数图像中,某点的切线的斜率
2)函数的变化率

2.多变量的微分,当函数有多个变量的时候,即分别对每个变量进行求微分
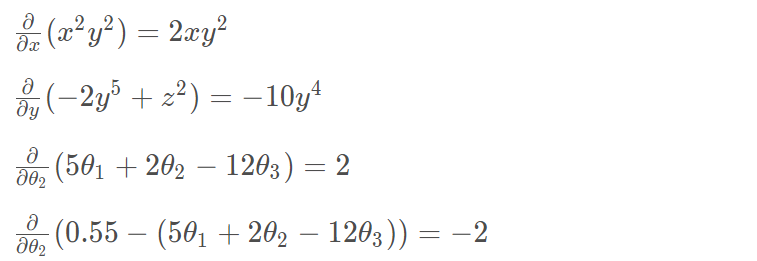
2.2.2 梯度
梯度实际上就是多变量微分的一般化。
下面这个例子:

我们可以看到,梯度就是分别对每个变量进行微分,然后用逗号分割开,梯度是用<>包括起来,说明梯度其实一个向量。
梯度是微积分中一个很重要的概念,之前提到过梯度的意义
在单变量的函数中,梯度其实就是函数的微分,代表着函数在某个给定点的切线的斜率
在多变量函数中,梯度是一个向量,向量有方向,梯度的方向就指出了函数在给定点的上升最快的方向
这也就说明了为什么我们需要千方百计的求取梯度!我们需要到达山底,就需要在每一步观测到此时最陡峭的地方,梯度就恰巧告诉了我们这个方向。梯度的方向是函数在给定点上升最快的方向,那么梯度的反方向就是函数在给定点下降最快的方向,这正是我们所需要的。所以我们只要沿着梯度的方向一直走,就能走到局部的最低点!
2.3 数学解释

2.3.1 α
α在梯度下降算法中被称作为学习率或者步长,意味着我们可以通过α来控制每一步走的距离,其实就是不要走太快,错过了最低点。同时也要保证不要走的太慢,导致太阳下山了,还没有走到山下。所以α的选择在梯度下降法中往往是很重要的!α不能太大也不能太小,太小的话,可能导致迟迟走不到最低点,太大的话,会导致错过最低点!
2.3.2 梯度要乘以一个负号
梯度前加一个负号,就意味着朝着梯度相反的方向前进!我们在前文提到,梯度的方向实际就是函数在此点上升最快的方向!而我们需要朝着下降最快的方向走,自然就是负的梯度的方向,所以此处需要加上负号;那么如果时上坡,也就是梯度上升算法,当然就不需要添加负号了。
3. 实例
我们已经基本了解了梯度下降算法的计算过程,那么我们就来看几个梯度下降算法的小实例,首先从单变量的函数开始,然后介绍多变量的函数。


如图,经过四次的运算,也就是走了四步,基本就抵达了函数的最低点,也就是山底
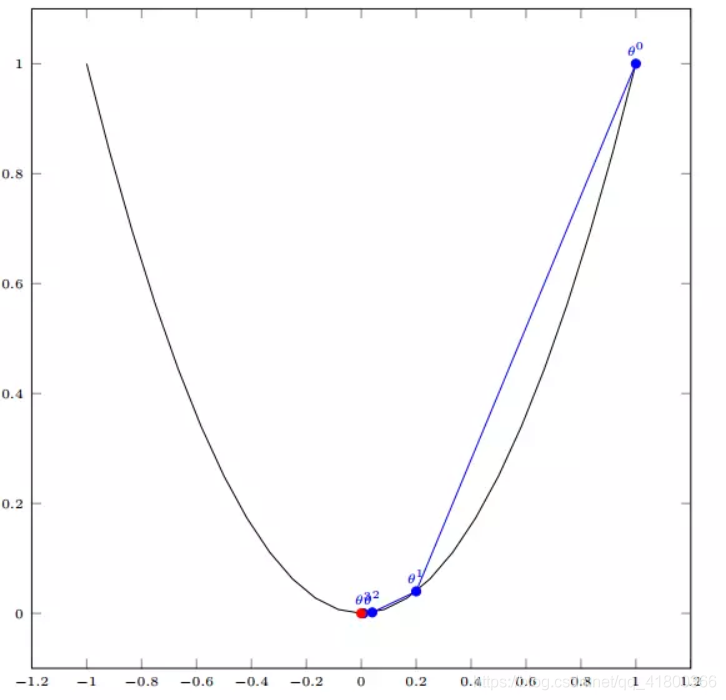
3.2多变量函数的梯度下降
我们假设有一个目标函数


初始的学习率为:α=0.1

我们发现,已经基本靠近函数的最小值点
4.代码实现
4.1场景分析
下面我们将用python实现一个简单的梯度下降算法。场景是一个简单的线性回归的例子:假设现在我们有一系列的点,如下图所示:
我们将用梯度下降法来拟合出这条直线!
首先,我们需要定义一个代价函数,在此我们选用均方误差代价函数(也称平方误差代价函数)
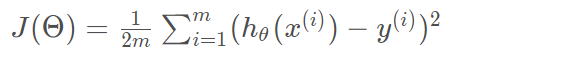
此公式中
1)m是数据集中数据点的个数,也就是样本数
3)y 是数据集中每个点的真实y坐标的值,也就是类标签
4)h 是我们的预测函数(假设函数),根据每一个输入x,根据Θ 计算得到预测的y值,即
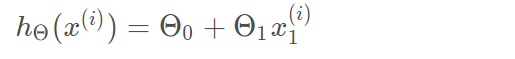
我们可以根据代价函数看到,代价函数中的变量有两个,所以是一个多变量的梯度下降问题,求解出代价函数的梯度,也就是分别对两个变量进行微分
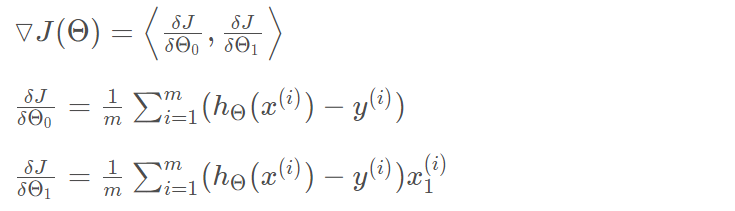
明确了代价函数和梯度,以及预测的函数形式。我们就可以开始编写代码了。但在这之前,需要说明一点,就是为了方便代码的编写,我们会将所有的公式都转换为矩阵的形式,python中计算矩阵是非常方便的,同时代码也会变得非常的简洁。
为了转换为矩阵的计算,我们观察到预测函数的形式
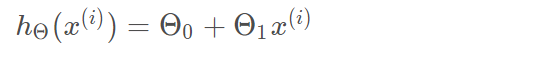
我们有两个变量,为了对这个公式进行矩阵化,我们可以给每一个点x增加一维,这一维的值固定为1,这一维将会乘到Θ0上。这样就方便我们统一矩阵化的计算
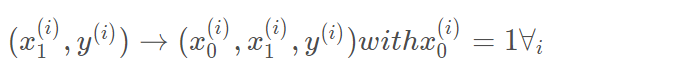
然后我们将代价函数和梯度转化为矩阵向量相乘的形式

4.2代码
首先,我们需要定义数据集和学习率
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # @Time : 2019/1/21 21:06 # @Author : Arrow and Bullet # @FileName: gradient_descent.py # @Software: PyCharm # @Blog :https://blog.csdn.net/_ from numpy import * # 数据集大小 即20个数据点 m = 20 # x的坐标以及对应的矩阵 X0 = ones((m, 1)) # 生成一个m行1列的向量,也就是x0,全是1 X1 = arange(1, m+1).reshape(m, 1) # 生成一个m行1列的向量,也就是x1,从1到m X = hstack((X0, X1)) # 按照列堆叠形成数组,其实就是样本数据 # 对应的y坐标 y = np.array([ 3, 4, 5, 5, 2, 4, 7, 8, 11, 8, 12, 11, 13, 13, 16, 17, 18, 17, 19, 21 ]).reshape(m, 1) # 学习率 alpha = 0.01 接下来我们以矩阵向量的形式定义代价函数和代价函数的梯度
# 定义代价函数 def cost_function(theta, X, Y): diff = dot(X, theta) - Y # dot() 数组需要像矩阵那样相乘,就需要用到dot() return (1/(2*m)) * dot(diff.transpose(), diff) # 定义代价函数对应的梯度函数 def gradient_function(theta, X, Y): diff = dot(X, theta) - Y return (1/m) * dot(X.transpose(), diff) 最后就是算法的核心部分,梯度下降迭代计算
# 定义代价函数 def cost_function(theta, X, Y): diff = dot(X, theta) - Y # dot() 数组需要像矩阵那样相乘,就需要用到dot() return (1/(2*m)) * dot(diff.transpose(), diff) # 定义代价函数对应的梯度函数 def gradient_function(theta, X, Y): diff = dot(X, theta) - Y return (1/m) * dot(X.transpose(), diff) java print('optimal:', optimal) # 结果 [[0.][0.]] print('cost function:', cost_function(optimal, X, Y)[0][0]) # 1.0 通过matplotlib画出图像
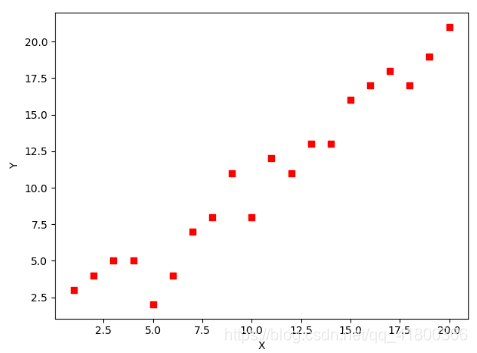
# 根据数据画出对应的图像 def plot(X, Y, theta): import matplotlib.pyplot as plt ax = plt.subplot(111) # 这是我改的 ax.scatter(X, Y, s=30, c="red", marker="s") plt.xlabel("X") plt.ylabel("Y") x = arange(0, 21, 0.2) # x的范围 y = theta[0] + theta[1]*x ax.plot(x, y) plt.show() plot(X1, Y, optimal) 所拟合出的直线如下

全部代码
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # @Time : 2019/1/21 21:06 # @Author : Arrow and Bullet # @FileName: gradient_descent.py # @Software: PyCharm # @Blog :https://blog.csdn.net/_ from numpy import * # 数据集大小 即20个数据点 m = 20 # x的坐标以及对应的矩阵 X0 = ones((m, 1)) # 生成一个m行1列的向量,也就是x0,全是1 X1 = arange(1, m+1).reshape(m, 1) # 生成一个m行1列的向量,也就是x1,从1到m X = hstack((X0, X1)) # 按照列堆叠形成数组,其实就是样本数据 # 对应的y坐标 Y = array([ 3, 4, 5, 5, 2, 4, 7, 8, 11, 8, 12, 11, 13, 13, 16, 17, 18, 17, 19, 21 ]).reshape(m, 1) # 学习率 alpha = 0.01 # 定义代价函数 def cost_function(theta, X, Y): diff = dot(X, theta) - Y # dot() 数组需要像矩阵那样相乘,就需要用到dot() return (1/(2*m)) * dot(diff.transpose(), diff) # 定义代价函数对应的梯度函数 def gradient_function(theta, X, Y): diff = dot(X, theta) - Y return (1/m) * dot(X.transpose(), diff) # 梯度下降迭代 def gradient_descent(X, Y, alpha): theta = array([1, 1]).reshape(2, 1) gradient = gradient_function(theta, X, Y) while not all(abs(gradient) <= 1e-5): theta = theta - alpha * gradient gradient = gradient_function(theta, X, Y) return theta optimal = gradient_descent(X, Y, alpha) print('optimal:', optimal) print('cost function:', cost_function(optimal, X, Y)[0][0]) # 根据数据画出对应的图像 def plot(X, Y, theta): import matplotlib.pyplot as plt ax = plt.subplot(111) # 这是我改的 ax.scatter(X, Y, s=30, c="red", marker="s") plt.xlabel("X") plt.ylabel("Y") x = arange(0, 21, 0.2) # x的范围 y = theta[0] + theta[1]*x ax.plot(x, y) plt.show() plot(X1, Y, optimal) 5.小结
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/226628.html原文链接:https://javaforall.net


