
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
FreqDisk
nltk FreqDisk函数能够统计数组当中单词出现的次数。
text = ['hadoop','spark','hive','hadoop','hadoop'
,'spark','lucene','hadoop','spark','hive'
,'hadoop','hadoop','spark','pig','zookeeper'
,'flume','stream','hadoop','hadoop','spark'
,'pig','zookeeper','flume','stream','hadoop'
,'hadoop','spark','pig','zookeeper','flume'
,'stream','hadoop','hadoop','spark','pig'
,'zookeeper','flume','stream','hadoop','hadoop'
,'spark','pig','zookeeper','flume','stream']
fdist = nltk.FreqDist(text)
for k in fdist:
print(k+" "+str(fdist[k]))
hadoop 14
spark 8
hive 2
lucene 1
pig 5
zookeeper 5
flume 5
stream 5
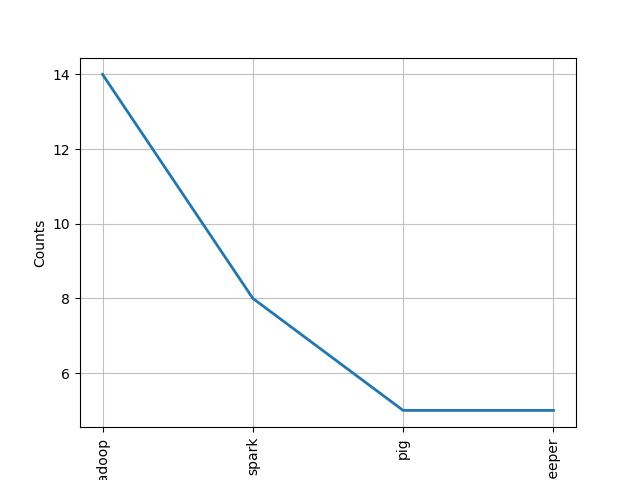
FreqDisk::plot(n)
参数n,以折线图的方式展示频数最大的前n项数据。
fdist.plot(4)

FreqDisk::tabulate(n)
参数n,以表格的方式展示频数最大的前n项数据。
fdist.tabulate(5)
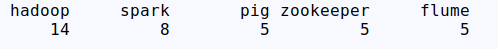
FreqDisk::most_common(n)
参数n,展示频数最大的前n项数据。
print(fdist.most_common(3))
[('hadoop', 14), ('spark', 8), ('pig', 5)]
FreqDisk::hapaxes()
展示频数最小的数据。
print(fdist.hapaxes())
['lucene']
FreqDisk::max()
展示频数最大的数据。
print(fdist.max())
hadoop
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/226787.html原文链接:https://javaforall.net


