
测试了C#中调用PaddleOCRSharp和PaddleSharp进行图片文字识别,由于正在学习python,也就同时学习使用python进行图片文字识别的方法。
百度关键词“python ocr”,搜出来的参考文献1中推荐用easyocr模块,同时在GitHub中搜索python编写的ocr库,easyocr也排名靠前,于是决定使用easyocr测试识别图片文字。

直接使用下列命令安装easyocr即可,虽然命令看着简单,但是下载速度不敢恭维,我后半夜电脑一直开着才下载安装成功的。
pip install easyocr easyocr安装完成后,根据参考文献2中的示例代码,只需几行代码即可完成图片文字识别,测试代码如下:
# coding=gbk import easyocr reader = easyocr.Reader(['ch_sim','en']) result = reader.readtext(r'd:\test\car2.jpg') print(result) 开始执行代码时,会看到如下提示,根据参考文献2中的说明,在windows平台中使用easyocr,可以在https://pytorch.org网站中安装torch和torchvision以支持GPU计算,这样能提高程序运行速度(本文只是初步测试,就没有安装)。
CUDA not available - defaulting to CPU. Note: This module is much faster with a GPU. 继续运行程序,又遇到了模型下载的问题。easyocr默认是运行时在线下载检测模型,但是下载速度很慢,一直卡在2.9%。根据参考文献3-4,可以自己下载检测模型,并放到Users\HP.EasyOCR\model文件夹下,本文是从参考文献4中下载的英文和中文检测模型。

模型下载完毕后,再次运行程序即可正常运行。下图是原图及识别出的文字结果(还没有学会如何用python向图片中绘制图形,暂时只是打印识别结果)。可以看到,大部分文字是可以正确识别,但识别效果没有PaddleOCRSharp和PaddleSharp,估计主要是还没有熟悉easyocr的参数配置造成的。
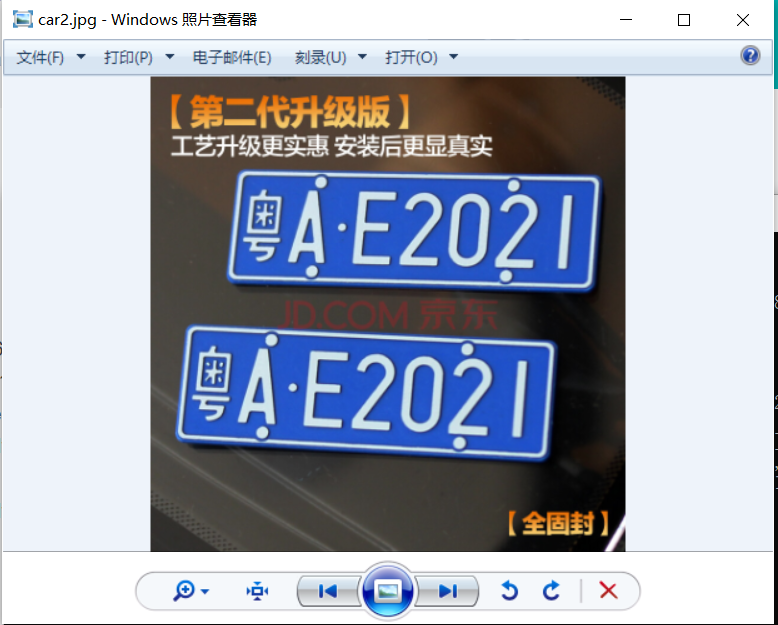
[([[26, 22], [446, 22], [446, 98], [26, 98]], '(第代升级版 ]', 0.9258), ([[30, 90], [584, 90], [584, 146], [30, 146]], '工艺升缏更实惠安装后更显真实', 0.), ([[149, 171], [735, 171], [735, 353], [149, 353]], '粤48202 |', 0.), ([[208, 362], [592, 362], [592, 436], [208, 436]], '', 0.0), ([[76, 466], [148, 466], [148, 586], [76, 586]], '粤', 0.03648), ([[130, 432], [664, 432], [664, 645], [130, 645]], 'AE2021', 0.), ([[595, 725], [781, 725], [781, 781], [595, 781]], '(全固封]', 0.97662)] 发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/230130.html原文链接:https://javaforall.net

![CMD命令行杀进程[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
