
人工智能-机器学习-算法-半监督学习:半监督学习(Semi-supervised Learning)算法
- 一、半监督学习算法提出的背景
- 二、学术名词区分
- 三、半监督学习的基本假设
- 四、半监督学习算法的主要方法
- 五、半监督学习算法应用实例
- 六、半监督学习中待研究的问题
一、半监督学习算法提出的背景
1、监督学习算法
- 监督学习:训练样本集不仅包含样本,还包含这些样本对应的标签,即样本和样本标签成对出现。监督学习的目标是从训练样本中学习一个从样本到标签的有效映射,使其能够预测未知样本的标签。监督学习是机器学习中最成熟的学习方法,代表性的算法包括神经网络、支持向量机(SVM)等。
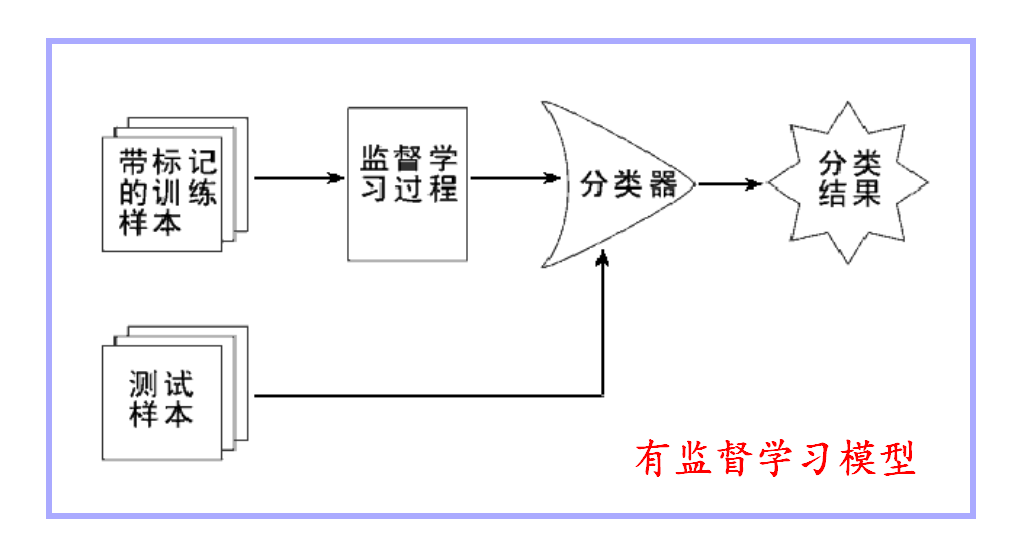

2、无监督学习算法
- 无监督学习:只能利用训练样本的数据分布或样本间的关系将样本划分到不同的聚类簇或给出样本对应的低维结构。- 因此,无监督学习常被用于对样本进行聚类或降维,典型的算法包括尺均值聚类和主成分分析等。

3、监督学习的特征选择方法
- 监督学习的特征选择方法通常根据样本特征与样本标签之间的相关性对特征进行排序。
- 基于监督学习的特征选择方法虽然能够根据样本标签选择出可以区分不同标签样本的特征子集,但是该类方法的性能取决于是否有充足的有标签样本。
4、无监督学习的特征选择方法
- 无监督特征方法利用训练样本的数据分布信息(如训练样本的方差以及局部结构等)去评估特征的关联性,大部分是利用到统计信息。
- 由于缺少样本标签的引导,无监督特征选择方法可能无法选择出有效的特征,也就是会缺乏先验知识,无法自主决策判断真假,显得比较“笨拙”。
5、问题的提出
- 在许多实际问题中,有标签样本和无标签样本往往同时存在,且无标签样本较多,而有标签样本则相对较少。
- 标记数据可能很耗时。假设我们有张狗图像,我们想将它们输入到分类算法中,目的是预测每个图像是否包含波士顿狗。如果我们想将所有这些图像用于监督分类任务,我们需要一个人查看每个图像并确定是否存在波士顿狗。
- 标记数据可能很昂贵。原因一:要想让人费尽心思去搜100万张狗狗照片,我们可能得掏钱。
- 虽然充足的有标签样本能够有效提升学习性能,但是获取样本标签往往是非常困难的,因为标记样本可能需要专家知识、特殊的设备以及大量的时间。
- 相比于有标签样本,大量的无标签样本广泛存在且非常容易收集。但是,监督学习算法无法利用无标签样本,在有标签样本较少时,难以取得较强的泛化性能。
- 虽然无监督学习算法能够使用无标签样本,但准确性较差。
- 在有标签样本较少时,如何利用无标签样本提升学习性能己成为机器学习及其应用中的重要研究问题。
- 针对以上问题,学者们想:能否在训练过程中同时使用有标签样本和无标签样本,由此提出了半监督学习。

二、学术名词区分
- 主动学习(active learning)
- 归纳式学习(inductive learning)
- 监督学习(supervised learning)
- 半监督学习(semi-supervised learning)
- 无监督学习(unsupervised learning)
- 直推式学习(transductive learning)
1、主动学习(active learning)
- 主动学习是指:大多数情况下,有类标的数据比较稀少而没有类标的数据是相当丰富的,但是对数据进行人工标注又非常昂贵,此时学习算法可以主动地提出一些标注请求,将一些经过筛选的数据提交给专家进行标注,因此需要一个外在的专业人员能够对其进行标注的实体,即主动学习是交互进行的。这个筛选过程是主动学习主要研究点。
2、归纳式学习(inductive learning)
Induction is reasoning from observed training cases to general rules, which are then applied to the test cases.
- 简而言之,归纳式学习是从训练样本中学习规则然后应用在测试样本中。监督学习就是一种归纳学习。
3、直推式学习(transductive learning)
Transduction is reasoning from observed, specific training cases to specific test cases.
- 直推式学习是同时使用训练样本和测试样本来训练模型,然后再次使用测试样本来测试模型效果。
4、监督学习、半监督归纳式学习、半监督直推式学习区别

- 假设:整个数据集中有两类样本集,一个有标记,一个没有标记。分别记作 D L a b e l e d D_{Labeled} DLabeled、 D U n l a b e l e d D_{Unlabeled} DUnlabeled,且 C D U n l a b e l e d ≫ C D L a b e l e d C_{D_{Unlabeled}}≫C_{D_{Labeled}} CDUnlabeled≫CDLabeled : D L a b e l e d = { X t r a i n , y t r a i n } D_{Labeled}=\{\textbf{X}_{train},\textbf{y}_{train}\} DLabeled={
Xtrain,ytrain}、 D U n l a b e l e d = { X u n k n o w n , X t e s t } D_{Unlabeled}=\{\textbf{X}_{unknown},\textbf{X}_{test}\} DUnlabeled={
Xunknown,Xtest} - 监督学习:训练数据集为 D t r a i n = { X t r a i n , y t r a i n } D_{train}=\{\textbf{X}_{train},\textbf{y}_{train}\} Dtrain={
Xtrain,ytrain} ,测试数据集(未标记) X t e s t \textbf{X}_{test} Xtest ,当 X t e s t \textbf{X}_{test} Xtest 不出现在训练数据集 D t r a i n D_{train} Dtrain 中时,这种情况是监督学习(归纳式学习)。 - 半监督归纳式(inductive )学习:训练集为 D t r a i n = { X t r a i n , y t r a i n , X u n k n o w n } D_{train}=\{\textbf{X}_{train},\textbf{y}_{train},\textbf{X}_{unknown}\} Dtrain={
Xtrain,ytrain,Xunknown} , X u n k n o w n \textbf{X}_{unknown} Xunknown 与 X t e s t \textbf{X}_{test} Xtest 都是未标记的,且测试的 X t e s t \textbf{X}_{test} Xtest 在训练时没有见过,即: X u n k n o w n ≠ X t e s t \textbf{X}_{unknown}≠\textbf{X}_{test} Xunknown=Xtest,这种情况是 半监督归纳式学习。 - 半监督直推式(transductive )学习:训练集为 D t r a i n = { X t r a i n , y t r a i n , X u n k n o w n } D_{train}=\{\textbf{X}_{train},\textbf{y}_{train},\textbf{X}_{unknown}\} Dtrain={
Xtrain,ytrain,Xunknown}, X u n k n o w n \textbf{X}_{unknown} Xunknown是未标记的, X u n k n o w n = X t e s t \textbf{X}_{unknown}=\textbf{X}_{test} Xunknown=Xtest,而且训练模型的目的只是想利用模型对 X u n k n o w n \textbf{X}_{unknown} Xunknown 数据集进行分类,由于此时在训练的时利用了 X u n k n o w n \textbf{X}_{unknown} Xunknown 的特征信息,这种情况称为半监督直推式学习。
5、半监督归纳式(induction)学习
- 归纳式半监督算法除了使用有标签样本集 D = { X t r a i n , y t r a i n } D=\{\textbf{X}_{train},\textbf{y}_{train}\} D={
Xtrain,ytrain} 和无标签样本集 X u n k n o w n \textbf{X}_{unknown} Xunknown 外,还使用独立的测试样本集 X t e s t \textbf{X}_{test} Xtest。 - 归纳式半监督算法能够处理整个样本空间中的样本。
- 归纳式半监督算法在有标签样本和无标签样本上训练学习模型。
- 该模型不仅可以预测训练无标签样本的标签,还能直接预测新测试样本的标签。
- 归纳学习试图基于观察到的一组训练数据点,建立一个可以预测任何新数据点的通用模型。 在这里,您可以预测点空间中除未标记点之外的任何点。
- 半监督归纳式学习的过程如下:

6、半监督直推式(transductive)学习
- 直推式半监督中只包含有标签样本集 D = { X t r a i n , y t r a i n } D=\{\textbf{X}_{train},\textbf{y}_{train}\} D={
Xtrain,ytrain} 和测试样本集 X u n k n o w n \textbf{X}_{unknown} Xunknown,且测试样本集 X u n k n o w n \textbf{X}_{unknown} Xunknown 也是无标签样本。 - 直推式半监督算法的测试样本为无标签样本 X u n k n o w n \textbf{X}_{unknown} Xunknown,然后利用有标签样本和无标签样本 X u n k n o w n \textbf{X}_{unknown} Xunknown 训练模型,并在训练过程中预测无标签样本 X u n k n o w n \textbf{X}_{unknown} Xunknown。
- 因此,直推式半监督算法只能处理当前的无标签样本(测试样本),不能直接进行样本外的扩展。
- 直推式学习不能建立预测模型。对于新的测试样本,直推式半监督算法需要重新训练模型才能预测其标签。
- 直推式学习建立一个模型,该模型适合已经观察到的训练和测试数据点。 这种方法使用标记点的知识和其他信息来预测未标记点的标记。

三、半监督学习的基本假设
- 由于有标签样本较少,为了有效利用大量的无标签样本,半监督学习需要采用合适的半监督假设将学习模型和无标签样本的数据分布联系起来。
- 研究也表明:半监督学习方法的性能依赖于所用的半监督假设!
- 目前的机器学习技术大多基于独立同分布假设,即数据样本独立地采样于同一分布。
- 除了独立同分布假设,为了学习到泛化的结果,监督学习技术大多基于平滑(smoothness)假设,即相似或相邻的样本点的标记也应当相似。而在半监督学习中这种平滑假设则体现为两个较为常见的假设:聚类(cluster)假设与流型(manifold)假设。
- 半监督算法仅在数据的结构保持不变的假设下起作用,没有这样的假设,不可能从有限的训练集推广到无限的不可见的集合。具体地假设有:平滑假设(smoothness assumption)、聚类假设(cluster assumption)、流型假设(maniford assumption)
- 聚类假设(cluster assumption)与流型假设(maniford assumption)这两种假设一般是一致的,属于监督学习中平滑假设的在半监督学习中的推广。
- 流型假设比聚类假设更为一般,因为流型假设是相似的样本点具有相似的性质而不是聚类假设所认为的相同的标记,对于聚类假设无法成立的回归问题上流型假设却可以成立。
1、平滑假设(smoothness assumption)
- 如果两个样本 x 1 , x 2 x_1,x_2 x1,x2 相似,则它们的相应输出 y 1 , y 2 y_1,y_2 y1,y2 也应如此。这意味着如果两个输入相同类,并且属于同一簇,则它们相应的输出需要相近,反之亦成立。
- 即相似或相邻的样本点的标记也应当相似。
2、聚类假设(cluster assumption)
- 聚类假设是指同一聚类中的样本点很可能具有同样的类别标记。
- 这个假设可以通过另一种等价的方式进行表达,那就是决策边界所穿过的区域应当是数据点较为稀疏的区域,因为如果决策边界穿过数据点较为密集的区域那就很有可能将一个聚类中的样本点分为不同的类别这与聚类假设矛盾。
- 聚类假设关注样本空间的整体特征,它利用大量无标签样本探测样本分布稠密和稀疏的区域,从而更好地约束决策边界。
- 基于聚类假设的半监督算法通常要求决策边界穿过样本分布稀疏的区域,并能最大化不同聚类簇间的类间间隔。
- 通过利用无标签样本约束目标函数,基于聚类假设的算法能够同时优化有标签样本和无标签样本的类间间隔。
3、流型假设(maniford assumption)
- 流型假设是指高维中的数据存在着低维的特性。
- 另一种类似的表述为:“处于一个很小的局部邻域内的示例具有相似的性质”。
- 高维数据中的数据的低维的特性是通过局部邻域相似性体现的,比如一个在三维空间卷曲的二维纸带,高维的数据全局的距离度量由于维度过高而显得没有区分度,但是如果只考虑局部范围的距离度量,那就会有一定意义。
- 流形假设主要关注样本空间的局部特征,它利用大量的无标签样增加样本空间的密度,从而更准确地获取样本的局部近邻关系。
- 基于流形假设的半监督算法要求决策边界在数据嵌入到的低维流形上平稳地变化。
四、半监督学习算法的主要方法
- 半监督学习:在少量样本标签的引导下,能够充分利用大量无标签样本提高学习性能,避免了数据资源的浪费,同时解决了有标签样本较少时监督学习方法泛化能力不强和缺少样本标签引导时无监督学习方法不准确的问题。
- 由于能够同时使用有标签和无标签样本,半监督学习己成为近年来机器学习领域的热点研究方向,并被应用于图像识别、自然语言处理和生物数据分析等领域。
- 根据不同的学习场景,现有的半监督学习算法可分为四类:
- 半监督分类
- 半监督回归
- 半监督聚类
- 半监督降维
- 其中,半监督分类是半监督学习中研宄最多的问题。
- 半监督学习的主要目标是利用隐藏在大量无标签样本中的数据分布信息来提升仅使用少量有标签样本时的学习性能。
1、生成式模型(Generative Model)/最大期望法(EM算法)
- 最大期望法(EM)与朴素贝叶斯算法有着共同的理论基础。
- 最大期望法是一种基于循环过程的最大似然参数估计方法,用于解决带缺失数据的参数估计问题,是最早的半监督学习方法。

1.1 生成模型与判别模型
- 判别式学习对条件概率建模

- 生成式学习对联合概率建模

- 生成式假定样本数据服从某一潜在分布(模型泛化能力强),需要充分可靠的知识.
1.2 高斯混合模型的似然函数
- 高斯混合模型的概率密度函数

- 采用最大后验概率预测 x \pmb{x} xxx 的标记, Y = { 1 , 2 , ⋯ , K } \mathcal Y=\{1, 2, \cdots, K\} Y={
1,2,⋯,K},则

式中
– p ( y ∣ θ k , x ) p(y|θ_k, \pmb{x}) p(y∣θk,xxx),表示 x \pmb{x} xxx由第 k k k 个分布生成且标记为 y y y 的概率,当且仅当 y = k y = k y=k 时,概率为1;
– p ( θ k ∣ x ) p(θ_k|\pmb{x}) p(θk∣xxx),表示 x \pmb{x} xxx由第 k k k 分布生成的后验概率,利用大数据量的未标记数据可提高该概率的准确率;
- 若类簇与真实类别一一对应,标记样本 x ∈ D l \pmb{x} ∈ D_l xxx∈Dl ,仅属于特定簇,则

- 上式中仅当 i = k i = k i=k时, p ( y = k ∣ θ i , x ) p (y=k∣θ_ i , \pmb{x} ) p(y=k∣θi,xxx) 为1,否则为0. 无标记样本 x ∈ D u \pmb{x} ∈ D_u xxx∈Du ,可能属于任何类簇,则

- 对数似然函数

1.3 参数估计
- GMM的参数估计使用EM算法,即

- 其中隐变量期望,或者样本 x j \pmb{x}_j xxxj 属于第 k k k 个分布的概率,即E步

- 令 N k N_k Nk 表示第 k k k 类有标记的样本数,M步

2、低密度分割算法(Low-density Separation):自训练(Self-training)

2.1 Self-training步骤
- 在概念层面上,自训练的工作原理如下:
- 步骤1:将标记的数据实例拆分为训练集和测试集。然后,对标记的训练数据训练一个分类算法。
- 步骤2:使用经过训练的分类器来预测所有未标记数据实例的类标签。在这些预测的类标签中,正确率最高的被认为是“伪标签”。
(第2步的几个变化:a)所有预测的标签可以同时作为“伪标签”使用,而不考虑概率;或者b)“伪标签”数据可以通过预测的置信度进行加权。) - 步骤3:将“伪标记”数据与正确标记的训练数据连接起来。在组合的“伪标记”和正确标记训练数据上重新训练分类器。
- 步骤4:使用经过训练的分类器来预测已标记的测试数据实例的类标签。使用你选择的度量来评估分类器性能。
(可以重复步骤1到4,直到步骤2中的预测类标签不再满足特定的概率阈值,或者直到没有更多未标记的数据保留。)


2.2 Self-training损失函数


3、转导支持向量机(Transductive Support Vector Machines)-聚类假设
- 基于最大间隔准则的半监督支持向量机算法
- 半监督支持向量机通过优化有标签和无标签样本到决策边界的最小间隔,使决策边界在区分有标签样本的前提下穿过样本分布稀疏的区域。
4、先聚类后标注算法(Cluster and then Label)
4.1 Smoothness Assumption
- Assumption: “similar” ? has the same ? ̂
- More precisely:
- x x x is not uniform.
- If x 1 x^1 x1 and x 2 x^2 x2 are close in a high density region, y ^ 1 \hat{y}^1 y^1 and y ^ 2 \hat{y}^2 y^2 are the same.

4.2 Cluster and then Label

5、基于图的方法(Graph-Based Approach)
- 流形假设-直推式
- 基于流形假设的半监督算法要求决策边界在数据嵌入到的低维流形上平稳地变化。
- 由于实际训练样本的流形结构通常是未知的,研究者使用定义在训练样本的数据图去刻画数据的低维流形结构,由此提出了基于图的半监督学习算法。
5.1 Graph Construction

5.2 Smoothness of the labels on the graph

6、协同训练(Co-training)
五、半监督学习算法应用实例
1、语音识别(Speech Recognition)
2、文本分类(Text categorization)
3、语义解析(Parsing)
4、视频监控(Video surveillance)
5、蛋白质结构预测(Protein structure prediction)
六、半监督学习中待研究的问题
1、无标签样本的有效利用问题
- 常用的半监督学习算法在训练阶段直接使用所有的无标签样本,没有考虑无标签样本的可靠性。
- 例如,半监督支持向量机算法使用所有的无标签样本去约束目标函数,基于图的半监督学习算法利用所有的无标签样本去构建近邻图。
- 实际上,大量无标签样本中通常存在一些低质且无关的样本。直接使用这些无标签样本会影响算法的性能,当所用半监督假设不满足数据分布时,甚至会降低算法的性能。
- 因此,如何更加有效地使用无标签样本,降低无关的无标签样本对算法性能的影响,是半监督学习亟需解决的问题。
- ——我的理解是,简单来说就说无标签样本里没用的垃圾怎么处理掉。但这些垃圾不是真的一无是处,可能只是不存在于已有标签范围内的物品,比如我们有的标签是cat,dog,无标签样本里有个pig,pig也是一个有尊严的类别,不是垃圾物,直接丢掉?不合适;放进来训练?那它到底归成cat还是dog呢?
2、大量无标签样本的高效使用问题
- 在算法训练过程中,直接使用所有的无标签样本不仅会影响算法的性能,还会显著降低算法的计算效率。
- 常用的半监督学习算法具有较高的时间复杂度,只能处理小规模数据,且可扩展性较差。
- 因此,在有效利用无标签样本的前提下,如何高效使用大量的无标签样本,从而提升算法的性能和可扩展性,是使用半监督学习技术处理大规模数据时亟需解决的问题。
- ——如何考虑/评估不同无标签样本对算法整体的的贡献。
3、特征选择中的有效性问题
- 在特征选择领域,基于现有半监督学习范式的特征选择算法不加区别地使用少量有标签样本和大量无标签样本设计用于选择特征的评估标准或目标函数,同样没有考虑无标签样本的可靠性。
- 此外,这些算法不能同时选择特征并基于所选特征训练分类器。这些问题严重影响了半监督特征选择算法的有效性。
- 因此,如何有效地区分无标签样本的质量差异,增强算法对无标签噪声样本的鲁棒性,实现相关特征子集的自动选择,是半监督学习在特征选择应用中亟待解决的问题。
- ——如何自适应地选取有效的特征。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/230369.html原文链接:https://javaforall.net

![Android DrawerLayout 高仿QQ5.2双向侧滑菜单[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
