
目录
1. 实验内容与方法
- 初始化数组。初始化三个double矩阵matrix_a,matrix_b和result,矩阵的行和列可以根据数据量大小自行调整。数组中的值使用c++11中的random类随机生成0到1之间的double值。
- 程序计时。使用c++11中的std::chrono库,使用system_clock表示当前的系统时钟,系统中运行的所有进程使用now()得到的时间是一致的。
- 串行执行数组相乘。遍历两个矩阵,使用矩阵乘法,将存储的结果放到
- 并行执行数组相乘。使用openmp将for循环设置为多线程,线程数根据实验内容进行调整。
- 线程数不变,修改矩阵大小。从6000 * 6000修改为8000 * 6000和8000 * 8000,统计运行时间。
- 矩阵大小不变,修改线程数。分别设置线程数为2、4、8个,统计运行时间。
2. 实验过程
实验设备CPU(i7-7700 3.6GHz, 8核),内存16G,操作系统Ubuntu 18.04,IDE CLion。
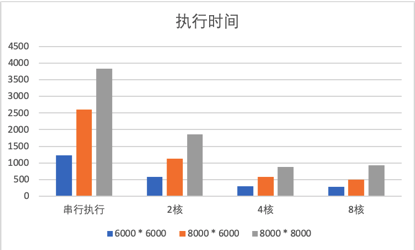
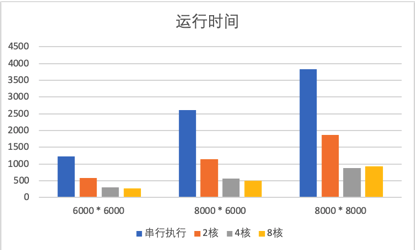
2.1 运行时间
分别控制矩阵大小和并行线程数进行实验。经过长时间的代码运行计时,得到以下的实验结果表格。
|
运行时间/秒 |
6000 * 6000 |
8000 * 6000 |
8000 * 8000 |
|
串行执行 |
1222.05 |
2603.9 |
3835.77 |
|
2核 |
575.985 |
1133.83 |
1859.81 |
|
4核 |
295.408 |
568.993 |
869.143 |
|
8核 |
273.935 |
497.045 |
921.517 |
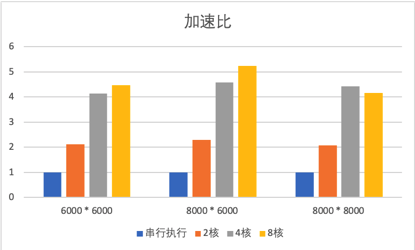
2.2 加速比
|
加速比 |
6000 * 6000 |
8000 * 6000 |
8000 * 8000 |
|
串行执行 |
1 |
1 |
1 |
|
2核 |
2. |
2. |
2.0 |
|
4核 |
4. |
4. |
4. |
|
8核 |
4. |
5. |
4. |
2.3 图表
绘制成图表,如下图所示。

3. 实验分析
从实验结果和加速比可以看出:
- 随着矩阵的增大,串行和并行算法运行时间也在增大;
- Openmp并行程序可有效提高矩阵运行的速度;
- 在4核并行内,矩阵运行的加速比与核心数近似成正比;当并行线程数大于4后,矩阵运行的时间较4线程提升不大,实验中存在8个线程运行时间多于4线程的情况。
4. 源代码
#include <iostream> #include "cstdlib" #include "random" #include "ctime" #include "chrono" #include "omp.h" using namespace std; using namespace std::chrono; #define M 6000 #define N 6000 #define ThreadNumber 4 double matrix_a[M][N], matrix_b[N][M], result[M][M]; void init_matrix(); void serial_multiplication(); void parallel_multiplication(); int main() { init_matrix(); auto start = system_clock::now(); serial_multiplication(); auto end = system_clock::now(); auto duration = duration_cast<microseconds>(end - start); cout << "serial multiplication takes " << double(duration.count()) * microseconds::period::num / microseconds::period::den << " seconds" << endl; start = system_clock::now(); parallel_multiplication(); end = system_clock::now(); duration = duration_cast<microseconds>(end - start); cout << "parallel multiplication takes " << double(duration.count()) * microseconds::period::num / microseconds::period::den << " seconds" << endl; return 0; } //generate the same matrix everytime void init_matrix() { default_random_engine engine; uniform_real_distribution<double> u(0.0, 1.0); for (int i = 0; i < M; ++i) { for (int j = 0; j < N; ++j) { matrix_a[i][j] = u(engine); } } for (int i = 0; i < N; ++i) { for (int j = 0; j < M; ++j) { matrix_b[i][j] = u(engine); } } } void serial_multiplication() { for (int i = 0; i < M; ++i) { for (int j = 0; j < M; ++j) { double temp = 0; for (int k = 0; k < N; ++k) { temp += matrix_a[i][k] * matrix_b[k][j]; } result[i][j] = temp; } } } void parallel_multiplication() { #pragma omp parallel for num_threads(ThreadNumber) for (int i = 0; i < M; ++i) { for (int j = 0; j < M; ++j) { double temp = 0; for (int k = 0; k < N; ++k) { temp += matrix_a[i][k] * matrix_b[k][j]; } result[i][j] = temp; } } }
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/233013.html原文链接:https://javaforall.net


