
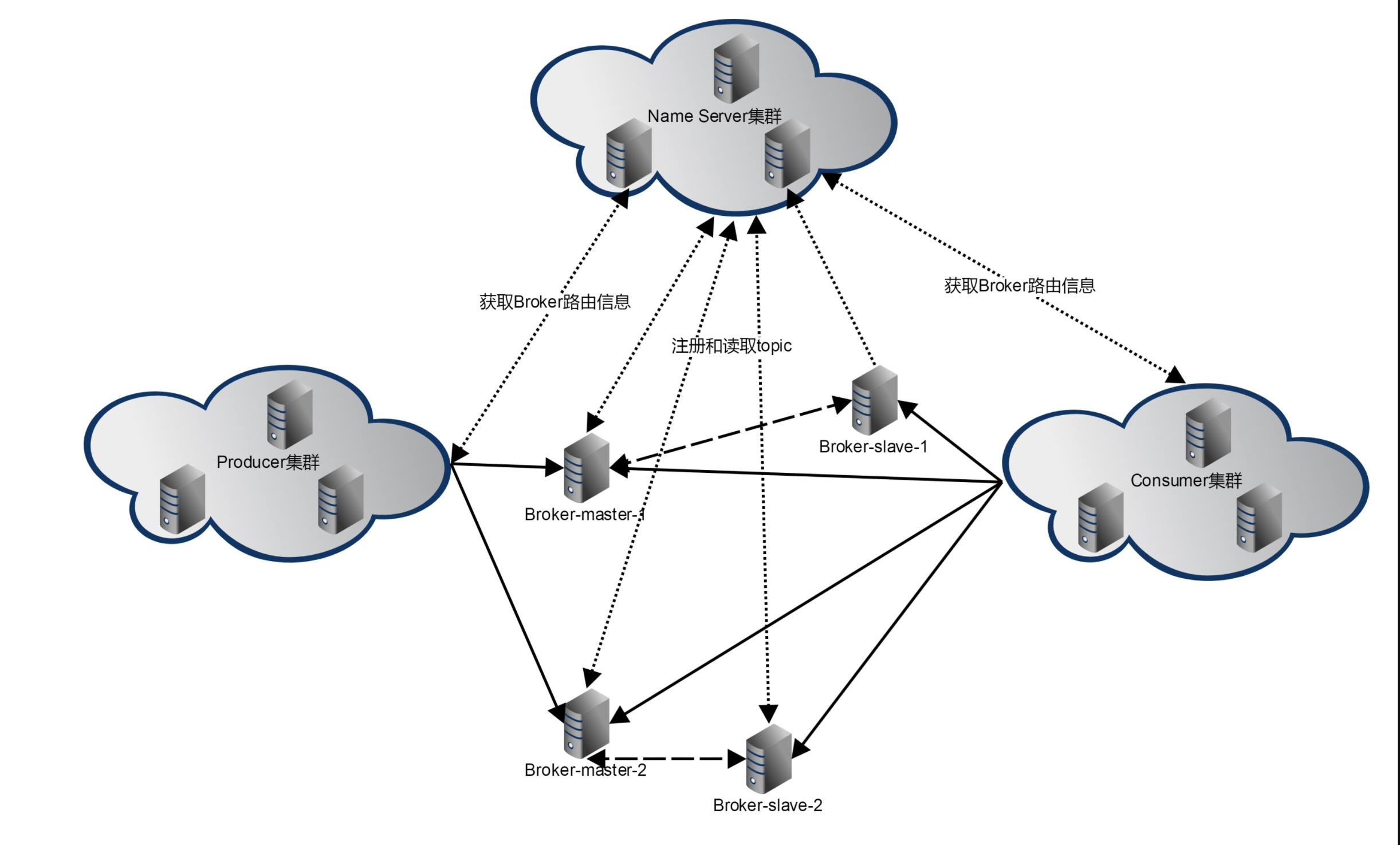

1.NameServer名称服务
2.Broker
Broker向NameServer注册topic配置信息,配置信息格式如下:
{ "perm":6, "readQueueNums":2, "topicFilterType":"SINGLE_TAG", "topicName":"Topic-Lance", "writeQueueNums":5 }3:Broker的消息存储
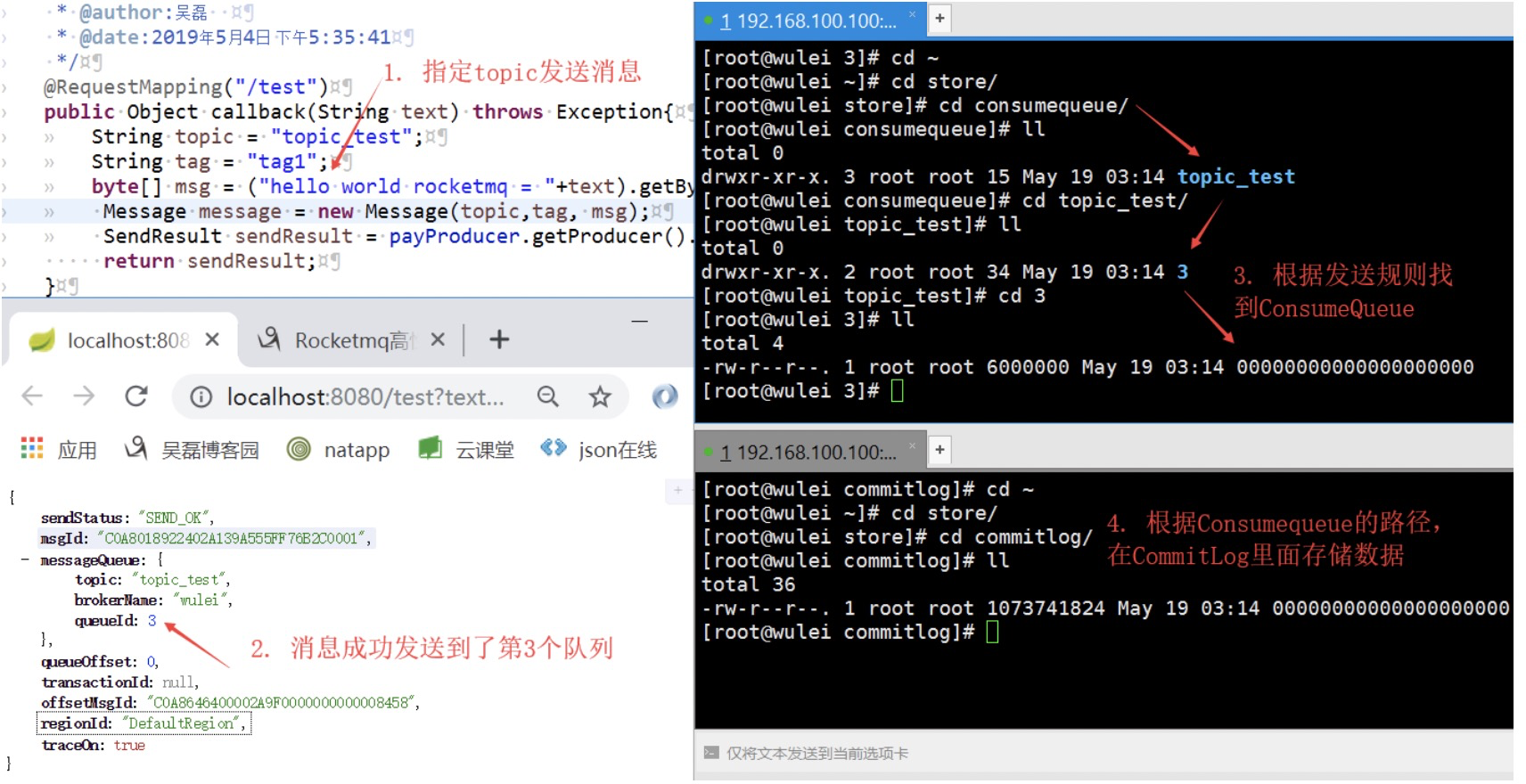
Rocketmq的消息的存储是由consumeQueue和 commitLog 配合完成的,commitLog保存消息的物理数据,consumeQueue是消息的逻辑队列,类似于索引,存储的是指向物理存储的地址。在一个Broker上,只有一个commitLog,所有consumeQueue共享同一个commitLog。
假如topic的名字是Topic-Lance,配置的读写队列有queue-1和queue-2,那么Topic-Lance和queue-1组成一个consumeQueue,Topic-Lance和queue-2组成另一个consumeQueue。
假如broker-A(包含queue-0,queue-1,queue-2), broker-B(包含queue-0,queue-1)两台broker机器都配置了Topic-Lance,那么broker启动的时候,注册到NameServer的Topic-Lance的路由有broker-A-queue-0,broker-A-queue-1,broker-A-queue-2,broker-B-queue-0,broker-B-queue-1共5个consumeQueue。
为了提高读写性能,commitLog采取顺序写,随机读(通过pagecache机制批量从磁盘读取到内存,加速后续的读取速度),consumeQueue大部分读入内存(如果consumeQueue因为重启等因素丢失,可以通过commitLog重建)
Page cache是通过将磁盘中的数据缓存到内存中,从而减少磁盘I/O操作,从而提高性能。此外,还要确保在page cache中的数据更改时能够被同步到磁盘上,后者被称为page回写(page writeback)。一个inode对应一个page cache对象,一个page cache对象包含多个物理page。
4.Producer 生产者
a.Producer发送消息时(必须制定topic),首先从本地的Producer集合中获取topic->broker的路由信息,如果没有,则从 nameserver中获取topic->broker路由,并缓存到本地集合;
b.定时从nameServer获取最新的topic路由信息;
c.Producer定时将Producer的group信息发送到对应的broker上;
d.Producer发送消息到Master的broker上,通过Broker的主从复制copy到slave的broker上。
5.Consumer 消费者
RocketMQ是基于pull模式拉取消息,consumer做负载均衡并通过长轮询向broker拉消息,长轮询拉取消息后回调MessageListener接口实现完成消费。
关于RocketMQ长轮询可参考:https://www.jianshu.com/p/48dbc9eee890
6.数据丢失问题处理
RocketMQ默认保存3天,commit log刷盘间隔,默认1秒
7.消费重试机制
Producer端重试 :
默认情况下是失败3次重试,可通过retryTimesWhenSendFailed定义重试次数;
Consumer端重试:
8. Rocketmq消费模型(实时性)
RocketMQ默认是采用pushConsumer方式消费的,从概念上来说是推送给消费者,它的本质是pull+长轮询。这样既通过长轮询达到了push的实时性,又有了pull的可控性。系统收到消息后会自动处理消息和offset(消息偏移量),如果期间有新的consumer加入会自动做负载均衡(集群模式下offset存在broker中; 广播模式下offset存在consumer里)。当然我们也可以设置为pullConsumer模式,这样灵活性会提高,但是代码却会很复杂,需要手动维护offset,消息存储和状态。
* offset:简单粗暴的理解就是数组下标。message queue是无限长的数组,每次消息进来就会涨1,下标就是offset。consumer可以通过指定offse位置开始读取数据。queue的maxOffset是消息的最大offset,不是最新消息的offset 而是最新消息的offset+1,minOffset则是现存的最小offset。
9. Rocketmq消息存储(顺序写,随机读)
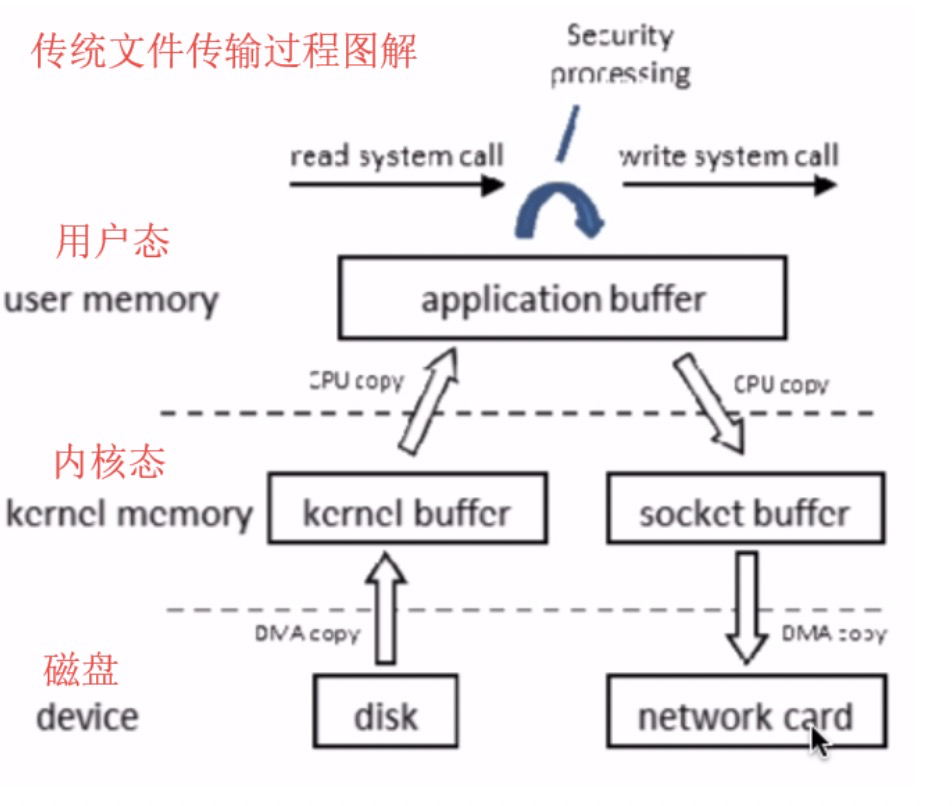
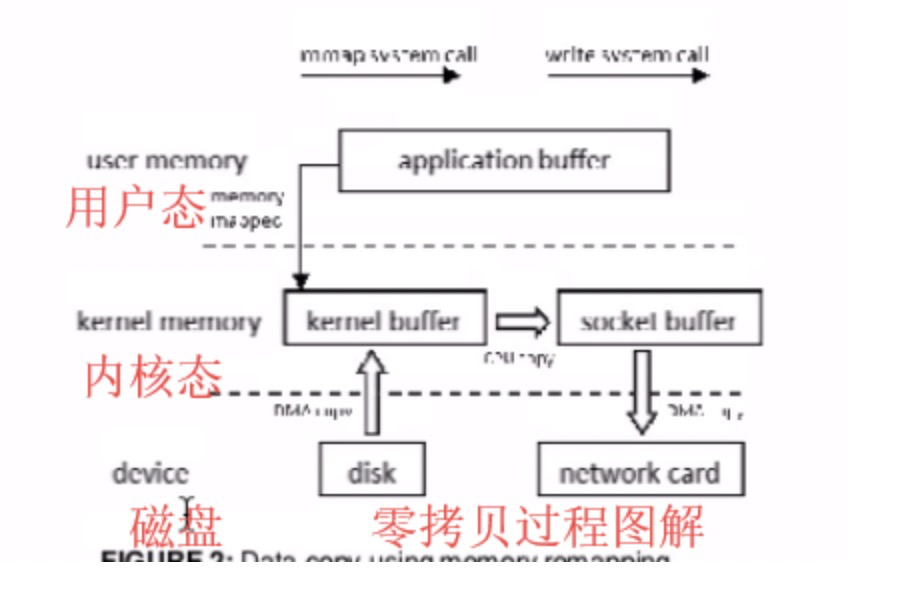
10. ZeroCopy高性能零拷贝
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/233722.html原文链接:https://javaforall.net


