
一、参考资料
环境搭建01-Ubuntu16.04如何查看显卡信息及安装NVDIA显卡驱动
Linux安装NVIDIA显卡驱动的正确姿势
二、环境配置
系统:Ubuntu16.04 显卡:NVIDIA GeForce GTX 1650,4GB 三、准备工作
1. 根据电脑显卡型号,下载对应显卡驱动 下载链接
# 博主对应下载的驱动版本 NVIDIA-Linux-x86_64-470.57.02.run 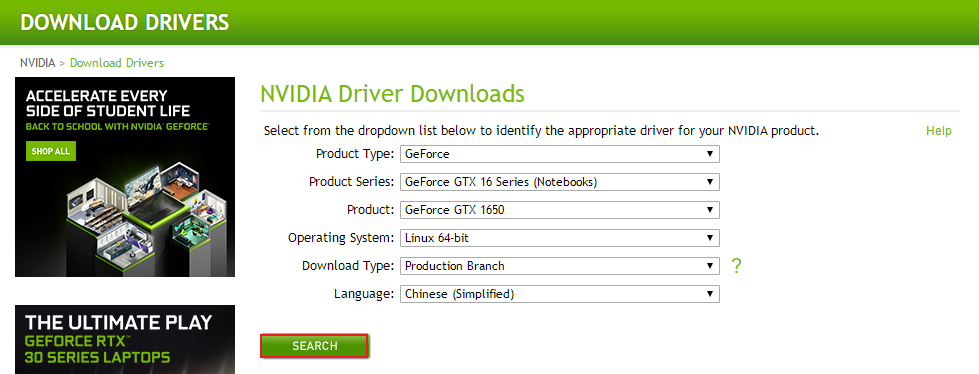

2. 将显卡驱动放到 /home/yichao/Downloads 目录
四、关键步骤
1. 查看显卡型号、驱动
# 查看显卡型号 ubuntu-drivers devices 如果没有输出,继续下面的操作
2. 禁用nouveau
# (1)验证是否禁用 nouveau lsmod | grep nouveau # (2)若有输出,说明没有禁用,进行以下操作禁用 sudo gedit /etc/modprobe.d/blacklist.conf # (3)在文件末尾中添加两条: blacklist nouveau options nouveau modeset=0 # (4)更新配置 sudo update-initramfs -u # (5)重启系统 # (6)查看是否禁用 nouveau,若无输出,则已禁用 lsmod | grep nouveau 3. nvidia驱动更新
# (1)添加ppa源 sudo add-apt-repository ppa:graphics-drivers/ppa #(2)更新apt-get sudo apt update # (3)查看更新后可以安装的显卡驱动版本 ubuntu-drivers devices # (4)安装推荐的显卡驱动 sudo apt-get install nvidia-430 4. 安装nvidia显卡驱动
# 1. 将显卡驱动文件拷贝到 /home/yichao/Downloads 目录 # 1.1 按 CTRL + ALT + F1 键登录,从 GUI 转至终端tty1(TUI文本用户界面) # 1.2 输入自己的login(我的是yichao)和password # 2. 临时关闭图形界面 sudo service lightdm stop # 3. 删除已安装的显卡驱动 sudo apt-get remove --purge nvidia* sudo apt-get autoremove (加上才能卸载干净原驱动) # 4. 修改显卡驱动文件的权限 sudo chmod a+x NVIDIA-Linux-x86_64-396.18.run # 5. 安装显卡驱动 sudo ./NVIDIA-Linux-x86_64-470.57.02.run -no-x-check -no-nouveau-check -no-opengl-files 参数说明: 1) –no-x-check:表示安装驱动时不检查X服务,非必需,我们已经禁用图形界面。 2) –no-nouveau-check:表示安装驱动时不检查nouveau,非必需,我们已经禁用驱动。 3) –no-opengl-files:表示只安装驱动文件,不安装OpenGL文件。这个参数不可省略,否则会导致登陆界面死循环,英语一般称为”login loop”或者”stuck in login”。 # 5.1 安装过程中的选项 (1)The distribution-provided pre-install script failed! Are you sure you want to continue? 选择 yes 继续。 (2)Would you like to register the kernel module souces with DKMS? This will allow DKMS to automatically build a new module, if you install a different kernel later? 选择NO继续 (3)Would you like to run the nvidia-xconfigutility to automatically update your x configuration so that the NVIDIA x driver will be used when you restart x? Any pre-existing x confile will be backed up. 选择 Yes 继续 (4)Install 32-Bit compatibility libraries? 选择 No 继续 开始会显示大量点点(......),然后进入图形化安装界面: 如果提示是否接受(accept),选接受; 如果提示检测到xxx不完整,是否退出安装,选不退出(continue); 如果提示有旧驱动,询问是否删除旧驱动,选Yes; 如果提示缺少某某模块(modules),询问是否上网下载,选no; 如果提示编译模块,询问是否进行编译,选ok; 如果提示将要修改Xorg.conf,询问是否允许,选Yes; 这些选项如果选择错误可能会导致安装失败,没关系,只要前面不出错,多尝试几次就好。 # 6. 开启图形界面,没自动跳的话 crtl+alt+f7退回到GUI图形用户界面 sudo service lightdm start # 7. 若弹出设置对话框,亦表示驱动安装成功 nvidia-settings 5. 查看已安装显卡驱动
nvidia-smi 五、可能出现的问题
- 缺少软链接
/sbin/ldconfig.real: /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8 is not a symbolic link /sbin/ldconfig.real: /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8 is not a symbolic link /sbin/ldconfig.real: /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8 is not a symbolic link /sbin/ldconfig.real: /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8 is not a symbolic link /sbin/ldconfig.real: /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8 is not a symbolic link /sbin/ldconfig.real: /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8 is not a symbolic link /sbin/ldconfig.real: /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8 is not a symbolic link 解决办法: 创建软链接 sudo ln -sf /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.1 /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8 sudo ln -sf /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.1 /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8 sudo ln -sf /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.1 /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8 sudo ln -sf /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.1 /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8 sudo ln -sf /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.1 /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8 sudo ln -sf /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.1 /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8 - 测试cuDNN错误
# 进入mnistCUDNN目录 cd /usr/src/cudnn_samples_v7/mnistCUDNN # 编译mnistCUDNN sudo make 或者 sudo make -j8 mnistCUDNN.cpp:538:53: error: ‘CUDNN_CONVOLUTION_FWD_PREFER_FASTEST’ was not declared in this scope CUDNN_CONVOLUTION_FWD_PREFER_FASTEST, ^ error_util.h:66:9: note: in definition of macro ‘checkCUDNN’ if (status != CUDNN_STATUS_SUCCESS) { \ ^ mnistCUDNN.cpp:541:53: error: there are no arguments to ‘cudnnGetConvolutionForwardAlgorithm’ that depend on a template parameter, so a declaration of ‘cudnnGetConvolutionForwardAlgorithm’ must be available [-fpermissive] ) ); ^ error_util.h:66:9: note: in definition of macro ‘checkCUDNN’ if (status != CUDNN_STATUS_SUCCESS) { \ ^ mnistCUDNN.cpp:541:53: note: (if you use ‘-fpermissive’, G++ will accept your code, but allowing the use of an undeclared name is deprecated) ) ); ^ error_util.h:66:9: note: in definition of macro ‘checkCUDNN’ if (status != CUDNN_STATUS_SUCCESS) { \ ^ mnistCUDNN.cpp:541:53: error: there are no arguments to ‘cudnnGetConvolutionForwardAlgorithm’ that depend on a template parameter, so a declaration of ‘cudnnGetConvolutionForwardAlgorithm’ must be available [-fpermissive] ) ); ^ error_util.h:67:65: note: in definition of macro ‘checkCUDNN’ _error << "CUDNN failure\nError: " << cudnnGetErrorString(status); \ ^ mnistCUDNN.cpp: In instantiation of ‘void network_t<value_type>::convoluteForward(const Layer_t<value_type>&, int&, int&, int&, int&, value_type*, value_type) [with value_type = float]’: mnistCUDNN.cpp:739:25: required from ‘int network_t<value_type>::classify_example(const char*, const Layer_t<value_type>&, const Layer_t<value_type>&, const Layer_t<value_type>&, const Layer_t<value_type>&) [with value_type = float]’ mnistCUDNN.cpp:831:75: required from here mnistCUDNN.cpp:533:60: error: ‘cudnnGetConvolutionForwardAlgorithm’ was not declared in this scope checkCUDNN( cudnnGetConvolutionForwardAlgorithm(cudnnHandle, ^ error_util.h:66:9: note: in definition of macro ‘checkCUDNN’ if (status != CUDNN_STATUS_SUCCESS) { \ ^ mnistCUDNN.cpp:533:60: error: ‘cudnnGetConvolutionForwardAlgorithm’ was not declared in this scope, and no declarations were found by argument-dependent lookup at the point of instantiation [-fpermissive] checkCUDNN( cudnnGetConvolutionForwardAlgorithm(cudnnHandle, ^ error_util.h:67:65: note: in definition of macro ‘checkCUDNN’ _error << "CUDNN failure\nError: " << cudnnGetErrorString(status); \ ^ mnistCUDNN.cpp:533:60: note: ‘cudnnGetConvolutionForwardAlgorithm’ declared here, later in the translation unit checkCUDNN( cudnnGetConvolutionForwardAlgorithm(cudnnHandle, ^ error_util.h:66:9: note: in definition of macro ‘checkCUDNN’ if (status != CUDNN_STATUS_SUCCESS) { \ ^ mnistCUDNN.cpp: In instantiation of ‘void network_t<value_type>::convoluteForward(const Layer_t<value_type>&, int&, int&, int&, int&, value_type*, value_type) [with value_type = __half]’: mnistCUDNN.cpp:739:25: required from ‘int network_t<value_type>::classify_example(const char*, const Layer_t<value_type>&, const Layer_t<value_type>&, const Layer_t<value_type>&, const Layer_t<value_type>&) [with value_type = __half]’ mnistCUDNN.cpp:898:83: required from here mnistCUDNN.cpp:533:60: error: ‘cudnnGetConvolutionForwardAlgorithm’ was not declared in this scope checkCUDNN( cudnnGetConvolutionForwardAlgorithm(cudnnHandle, ^ error_util.h:66:9: note: in definition of macro ‘checkCUDNN’ if (status != CUDNN_STATUS_SUCCESS) { \ ^ mnistCUDNN.cpp:533:60: error: ‘cudnnGetConvolutionForwardAlgorithm’ was not declared in this scope, and no declarations were found by argument-dependent lookup at the point of instantiation [-fpermissive] checkCUDNN( cudnnGetConvolutionForwardAlgorithm(cudnnHandle, ^ error_util.h:67:65: note: in definition of macro ‘checkCUDNN’ _error << "CUDNN failure\nError: " << cudnnGetErrorString(status); \ ^ mnistCUDNN.cpp:533:60: note: ‘cudnnGetConvolutionForwardAlgorithm’ declared here, later in the translation unit checkCUDNN( cudnnGetConvolutionForwardAlgorithm(cudnnHandle, ^ error_util.h:66:9: note: in definition of macro ‘checkCUDNN’ if (status != CUDNN_STATUS_SUCCESS) { \ ^ Makefile:235: recipe for target 'mnistCUDNN.o' failed make: * [mnistCUDNN.o] Error 1 Linking agains cublasLt = true CUDA VERSION: 11000 TARGET ARCH: x86_64 HOST_ARCH: x86_64 TARGET OS: linux SMS: 30 35 50 53 60 61 62 70 72 75 /usr/local/cuda/bin/nvcc -ccbin g++ -I/usr/local/cuda/include -I/usr/local/cuda/include -IFreeImage/include -m64 -gencode arch=compute_30,code=sm_30 -gencode arch=compute_35,code=sm_35 -gencode arch=compute_50,code=sm_50 -gencode arch=compute_53,code=sm_53 -gencode arch=compute_60,code=sm_60 -gencode arch=compute_61,code=sm_61 -gencode arch=compute_62,code=sm_62 -gencode arch=compute_70,code=sm_70 -gencode arch=compute_72,code=sm_72 -gencode arch=compute_75,code=sm_75 -gencode arch=compute_75,code=compute_75 -o fp16_dev.o -c fp16_dev.cu nvcc fatal : Unsupported gpu architecture 'compute_30' Makefile:238: recipe for target 'fp16_dev.o' failed make: * [fp16_dev.o] Error 1 解决办法: 修改Makefile文件 sudo gedit /home/yichao/MyDocuments/cudnn_samples_v7/mnistCUDNN/Makefile $(foreach sm,$(SMS),$(eval GENCODE_FLAGS += -gencode arch=compute_$(sm),code=sm_$(sm))) 修改为 GENCODE_FLAGS += -gencode arch=compute_35,code=sm_35 -gencode arch=compute_50,code=sm_50 -gencode arch=compute_53,code=sm_53 -gencode arch=compute_60,code=sm_60 -gencode arch=compute_61,code=sm_61 -gencode arch=compute_62,code=sm_62 -gencode arch=compute_70,code=sm_70 -gencode arch=compute_72,code=sm_72 -gencode arch=compute_75,code=sm_75 -gencode arch=compute_75,code=compute_75 参考资料 [](https://stackoverflow.com/questions//unsupported-gpu-architecture-compute-30-on-a-cuda-5-capable-gpu) [NVIDIA CUDA Toolkit 10.2.89](https://docs.nvidia.com/cuda/archive/10.2/pdf/CUDA_Toolkit_Release_Notes.pdf) 错误原因: CUDA 11.x no longer supports compute capability 3.0 CUDA11.x不再支持compute_30 解决办法: cd /usr/local/cuda-11.0/nvvm/libnvvm-samples/cuda-c-linking/CMakeLists.txt Makefile.config #>> nvcc -m64 -gencode=compute_20,code=sm_20 ... -dc math-funcs.cu -o math-funcs64.o add_custom_command(OUTPUT "${CMAKE_CURRENT_BINARY_DIR}/math-funcs64.o" COMMAND ${NVCC} -m64 -gencode arch=compute_20,code=sm_20 -gencode arch=compute_30,code=sm_30 -gencode arch=compute_35,code=sm_35 -gencode arch=compute_50,code=sm_50 -dc "${CMAKE_CURRENT_SOURCE_DIR}/math-funcs.cu" -o "${CMAKE_CURRENT_BINARY_DIR}/math-funcs64.o" DEPENDS "${CMAKE_CURRENT_SOURCE_DIR}/math-funcs.cu" COMMENT "Building math-funcs64.o") 改为 #>> nvcc -m64 -gencode=compute_20,code=sm_20 ... -dc math-funcs.cu -o math-funcs64.o add_custom_command(OUTPUT "${CMAKE_CURRENT_BINARY_DIR}/math-funcs64.o" COMMAND ${NVCC} -m64 -gencode arch=compute_35,code=sm_35 -gencode arch=compute_50,code=sm_50 -dc "${CMAKE_CURRENT_SOURCE_DIR}/math-funcs.cu" -o "${CMAKE_CURRENT_BINARY_DIR}/math-funcs64.o" DEPENDS "${CMAKE_CURRENT_SOURCE_DIR}/math-funcs.cu" COMMENT "Building math-funcs64.o") 删除 -gencode=arch=compute_20,code=sm_20 -gencode=arch=compute_30,code=sm_30 - 测试cuDNN错误
Makefile:163: ../samples_common.mk: 没有那个文件或目录 CUDA VERSION: TARGET ARCH: x86_64 HOST_ARCH: x86_64 TARGET OS: linux SMS: >>> WARNING - no SM architectures have been specified - waiving sample <<< make: * No rule to make target '../samples_common.mk'。 停止。 版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/233845.html原文链接:https://javaforall.net


