
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
信息熵
“信息熵”是度量样本集合纯度最常用的一种指标。假定当前样本集合D中第k类样本所占的比例为pk(k=1,2,…,|y|),则D的信息熵定义为:
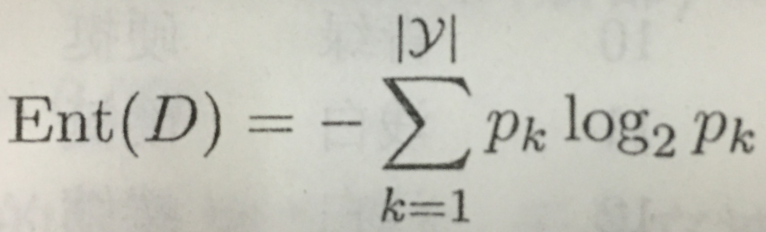

Ent(D)的值越小,则D的纯度越高。
如果上面的解释不容易理解,那么下面再通俗地解释一下:
首先来看一下信息熵这个公式在数轴上的表示:
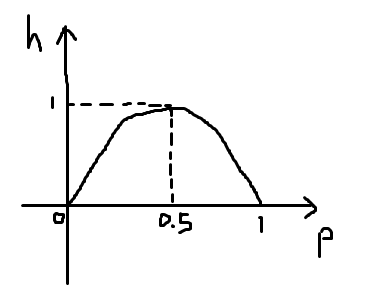
可以看到,在概率为0.5的时候,信息熵是最大的,为1。
我们可以把信息熵理解为“不确定性”,当概率为0.5时,比如抛硬币,出现正反两面的概率都是0.5,所以这个事件的不确定性是最大的;当一个事件发生的概率为0或1的时候,那这个事件就是必然事件了,不确定性为0,所以信息熵最低,为0。
信息增益
假定离散属性a有V个可能的取值{a1,a2,a3,…,aV},若使用a来对样本集D进行划分,则会产生V个分支结点,其中第v个分支结点包含了D中所有在属性a上取值为av的样本,记为Dv。我们可根据信息熵的式子计算出Dv的信息熵,再考虑到不同的分支结点所包含的样本数不同,给分支结点赋予权重|Dv|/|D|,即样本数越多的分支结点的影响越大,于是可计算出用属性a对样本集D进行划分所获得的“信息增益”:
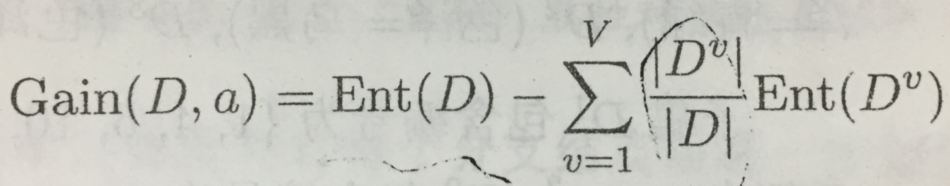
下面来看一个简单的数据集:

该数据集包含17个训练样例,显然|y|=2,即“好瓜”和“非好瓜”。
正例占p1=8/17,反例占p2=9/17。于是可计算出根结点的信息熵为:
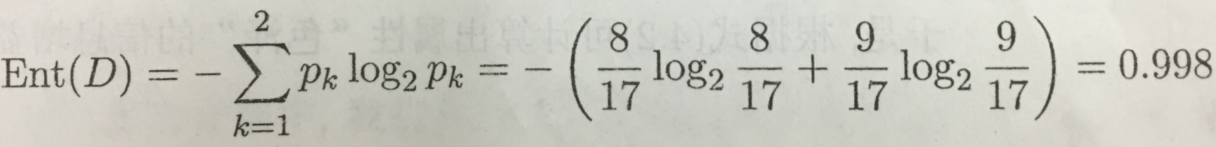
然后,我们要计算出当前属性集合{色泽,根蒂,敲声,纹理,脐部,触感}中每个属性的信息增益。以属性“色泽”为例,它有3个可能的取值。若使用该属性对D进行划分,则可得到3个子集,分别记为D1(色泽=青绿),有6个样本;D2(色泽=乌黑),有6个样本;D3(色泽=浅白),有5个样本。
则这3个分支结点的信息熵分别为: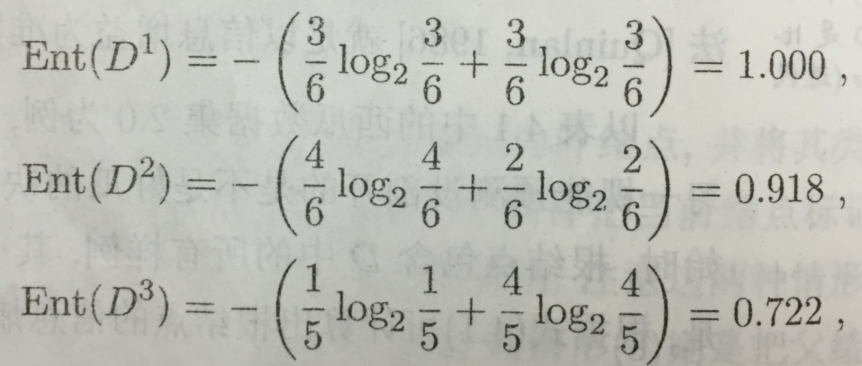
于是可计算出属性“色泽“的信息增益为:
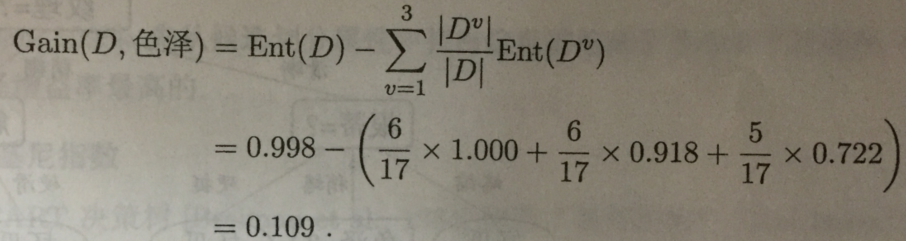
同理,我们可计算出其他属性的信息增益:

显然,“纹理”的信息增益最大。
这表示什么呢,通俗地讲,就是“纹理”这个属性是最能让我们买到好瓜的一个参照点。
信息增益比
在上面的介绍中,我们有意忽略了“编号”这一列,若把“编号”也作为一个候选划分属性,则可计算出它的信息增益为0.998,远大于其他候选划分属性。这很容易理解:
“编号”将产生17个分支,每个分支结点仅包含一个样本,这些分支结点的纯度已达最大,即分支结点的信息熵为0。
所以不难得出,信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,推出“信息增益比”来选择最优划分属性。
信息增益比的定义为:
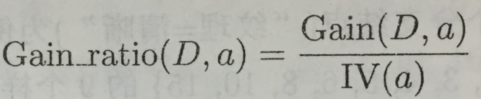
其中
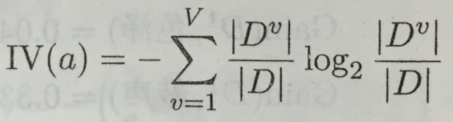
称为属性a的“固有值”。属性a的可能取值数目越多(即V越大),则IV(a)的值通常会越大。通过这种方式,来对可取值数目较多的属性作出惩罚。例如,对该西瓜数据集,有:
IV(触感)=0.874 (V=2),
IV(色泽)=1.580 (V=3),
IV(编号)=4.088 (V=17)。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/234836.html原文链接:https://javaforall.net


