
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
1.概念介绍:
图像识别(Image Recognition)是指利用计算机对图像进行处理、分析和理解,以识别各种不同模式的目标和对像的技术。
图像识别的发展经历了三个阶段:文字识别、数字图像处理与识别、物体识别。机器学习领域一般将此类识别问题转化为分类问题。
手写识别是常见的图像识别任务。计算机通过手写体图片来识别出图片中的字,与印刷字体不同的是,不同人的手写体风格迥异,大小不一, 造成了计算机对手写识别任务的一些困难。
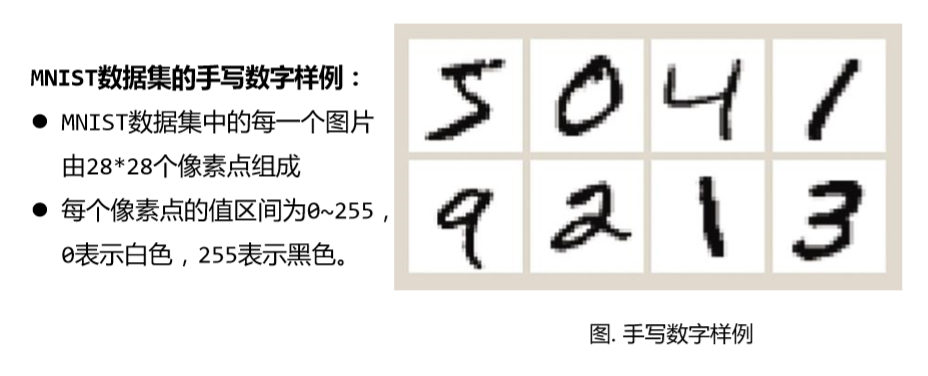
数字手写体识别由于其有限的类别(0~9共10个数字)成为了相对简单 的手写识别任务。DBRHD和MNIST是常用的两个数字手写识别数据集
2.数据介绍:
MNIST的下载链接:http://yann.lecun.com/exdb/mnist/。
MNIST是一个包含数字0~9的手写体图片数据集,图片已归一化为以手写数 字为中心的28*28规格的图片。
MNIST由训练集与测试集两个部分组成,各部分 规模如下:
训练集:60,000个手写体图片及对应标签
测试集:10,000个手写体图片及对应标签

DBRHD(Pen-Based Recognition of Handwritten Digits Data Set)是UCI的机器学习中心提供的数字手写体数据库: https://archive.ics.uci.edu/ml/datasets/PenBased+Recognition+of+Handwritten+Digits。
DBRHD数据集包含大量的数字0~9的手写体图片,这些图片来源于44位不同的人的手写数字,图片已归一化为以手写数字为中心的32*32规格的图片。
DBRHD的训练集与测试 集组成如下:
训练集:7,494个手写体图片及对应标签,来源于40位手写者
测试集:3,498个手写体图片及对应标签,来源于14位手写者


3.任务过程:

①输入

②输出

③MPL的结构
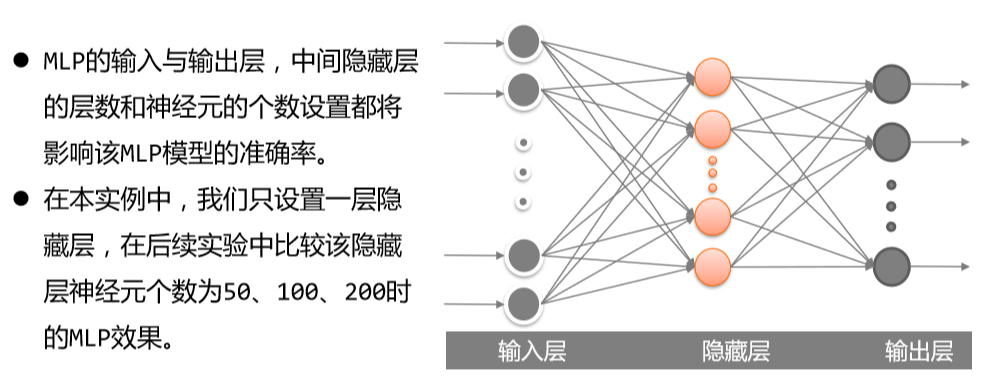
④步骤

import numpy as np #使用listdir模块,用于访问本地文件 from os import listdir from sklearn.neural_network import MLPClassifier
#定义img2vector函数,将加载的3232 的图片矩阵展开成一列向量
def img2vector(fileName):
retMat =np.zeros([1024],int)
fr = open(fileName) #打开包含3232大小的数字文件
lines =fr.readlines() #读取文件的所有行
for i in range(32):
for j in range(32): #将01数字存放在retMat
retMat[i*32+j]=lines[i][j];
return retMat
#并将样本标签转化为one-hot向量
def readDataSet(path):
fileList =listdir(path) #获取文件夹下所有文件
numFiles =len(fileList) #统计需要读取的文件的数目
dataSet =np.zeros([numFiles,1024],int) #用于存放所有的数字文件
hwLabels =np.zeros([numFiles,10]) #用于存放对应的标签one-hot
for i in range(numFiles):
filePath =fileList[i] #获取文件名称/路径
digit =int(filePath.split(’_’)[0])
hwLabels[i][digit]=1.0
dataSet[i]=img2vector(path+’/’+filePath)#读取文件内容
return dataSet,hwLabels
train_dataSet,train_hwLabels =readDataSet(‘trainingDigits’)
#构建神经网络:设置网络的隐藏层数、各隐藏层神经元个数、
# 激活函数、学习率、优化方法、最大迭代次数。
#hidden_layer_sizes 存放的是一个元组,表示第i层隐藏层里神经元的个数
# 使用logistic激活函数和adam优化方法,并令初始学习率为0.0001
clf =MLPClassifier(hidden_layer_sizes=(50,),activation=‘logistic’,
solver=‘adam’,learning_rate_init=0.0001,max_iter=2000)
#fit函数能够根据训练集及对应标签集自动设置多层感知机的输入与输出层的神经元个数。
#例如train_dataSet为n1024的矩阵,train_hwLabels为n10的矩阵,
# 则fit函数将MLP的输入层神经元个数设为1024,输出层神经元个数为 10.
clf.fit(train_dataSet,train_hwLabels)
#测试集评价
dataSet,hwlLabels =readDataSet(‘testDigits’)
res=clf.predict(dataSet) #对测试集进行预测
error_num =0 #统计预测错误的数目
num =len(dataSet) #测试集的数目
for i in range(num):
#比较长度为10的数组,返回包含01的数组,0为不同,1为相同
if np.sum(res[i]==hwlLabels[i])<10:
error_num+=1
print(“Total num:”,num,“Wrong num:”,error_num,” WrongRate:”,error_num/float(num))
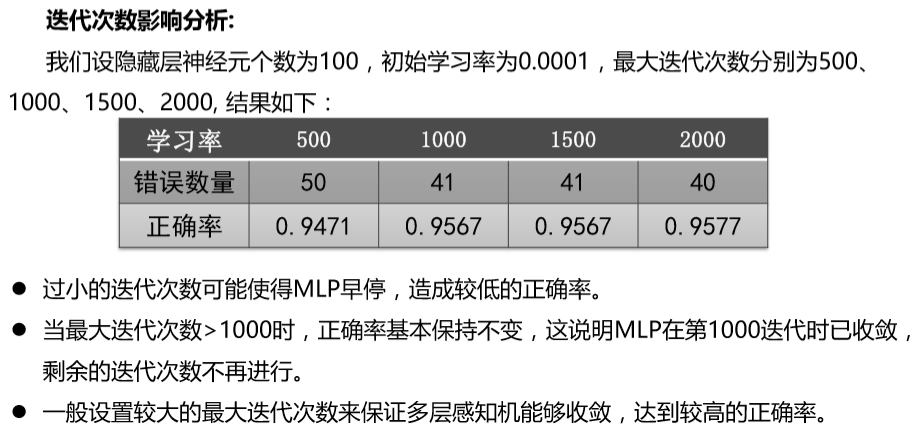
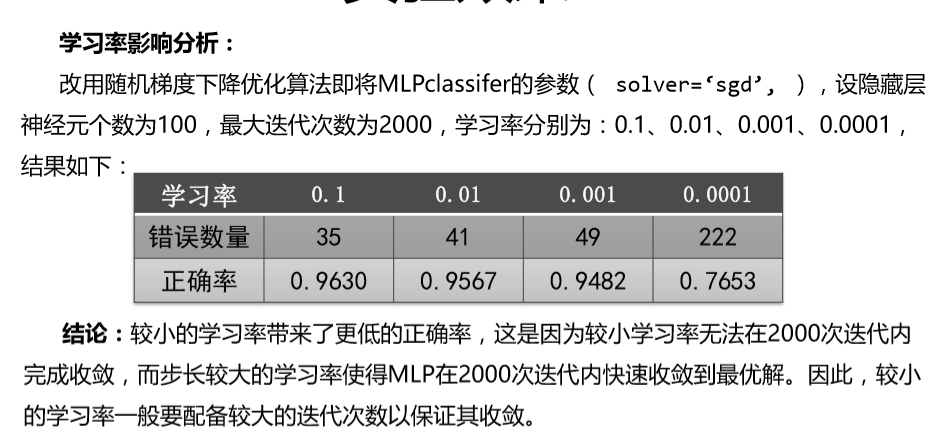
实验效果:
以下结果为课程结果,我自己实验的结果与这个结果相差不大。

2.使用KNN分类器识别数据集DBRHD的手写数字(内容与上面差不多,只是使用算法有些差别)

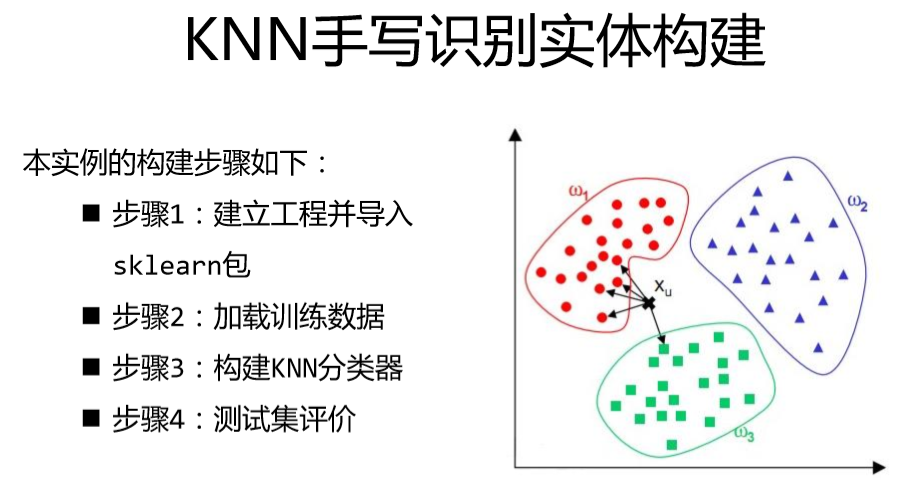
import numpy as np
#使用listdir模块,用于访问本地文件
from os import listdir
from sklearn import neighbors
#定义img2vector函数,将加载的3232 的图片矩阵展开成一列向量
def img2vector(fileName):
retMat =np.zeros([1024],int)
fr = open(fileName) #打开包含3232大小的数字文件
lines =fr.readlines() #读取文件的所有行
for i in range(32):
for j in range(32): #将01数字存放在retMat
retMat[i*32+j]=lines[i][j];
return retMat
#并将样本标签转化为one-hot向量
def readDataSet(path):
fileList =listdir(path) #获取文件夹下所有文件
numFiles =len(fileList) #统计需要读取的文件的数目
dataSet =np.zeros([numFiles,1024],int) #用于存放所有的数字文件
hwLabels =np.zeros([numFiles,10]) #用于存放对应的标签one-hot
for i in range(numFiles):
filePath =fileList[i] #获取文件名称/路径
digit =int(filePath.split(’_’)[0])
hwLabels[i][digit]=1.0
dataSet[i]=img2vector(path+’/’+filePath)#读取文件内容
return dataSet,hwLabels
train_dataSet,train_hwLabels =readDataSet(‘trainingDigits’)
#构建KNN分类器:设置查找算法以及邻居点 数量(k)值。
#KNN是一种懒惰学习法,没有学习过程,只在预测时去查找最近邻的点,
#数据集的输入就是构建KNN分类器的过程
knn =neighbors.KNeighborsClassifier(algorithm=‘kd_tree’,n_neighbors=3)
knn.fit(train_dataSet,train_hwLabels)
#测试集评价
dataSet,hwlLabels =readDataSet(‘testDigits’)
res=knn.predict(dataSet) #对测试集进行预测
error_num =np.sum(res!=hwlLabels) #统计预测错误的数目
num =len(dataSet) #测试集的数目
print(“Total num:”,num,“Wrong num:”,error_num,” WrongRate:”,error_num/float(num))
实验结果(同上)
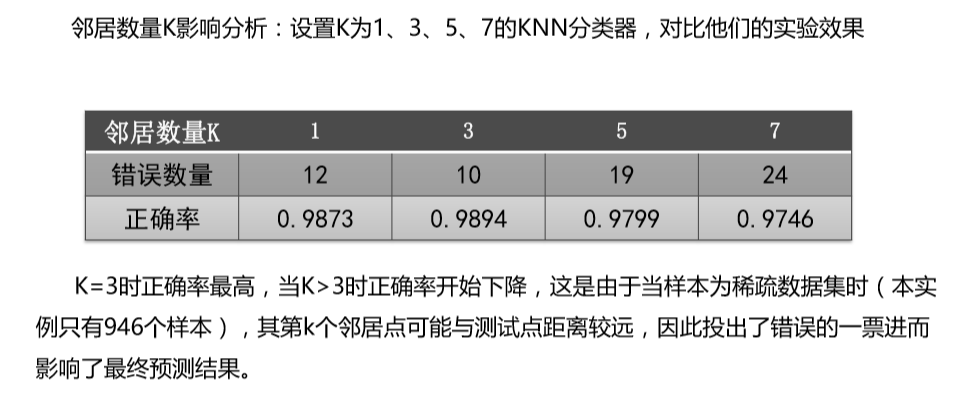
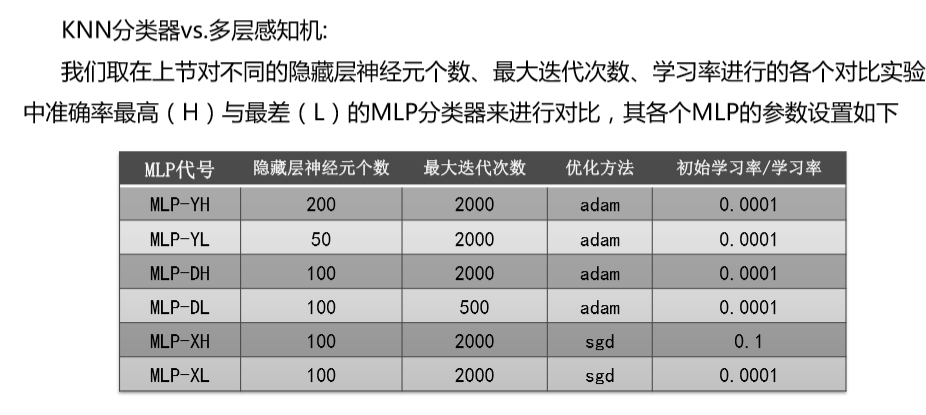
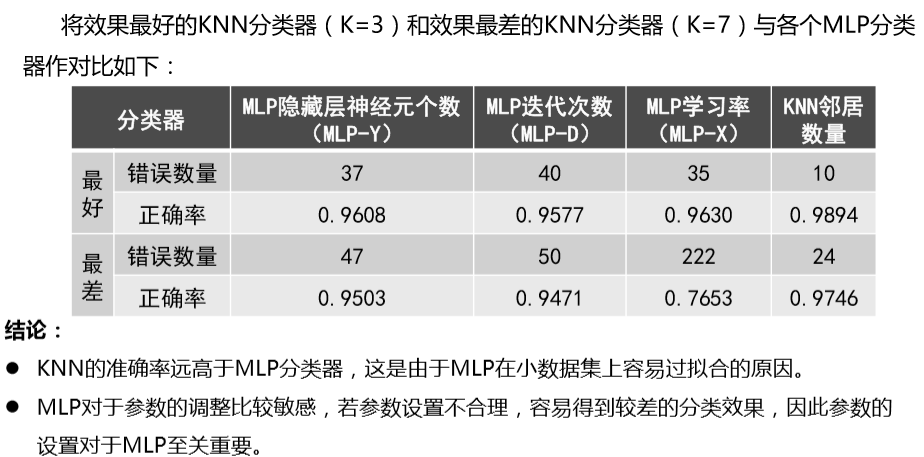
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/234904.html原文链接:https://javaforall.net


