
DeepSeek 是深度求索(DeepSeek Inc.)旗下的核心大语言模型(Large Language Models,简称 LLMs)品牌,围绕这一技术推出了多款具有广泛影响力的产品与服务,DeepSeek 教程涵盖文本生成、对话交互、多模态处理、企业级定制等多个领域,其核心优势在于全栈多模态融合、高效推理能力、端云协同部署、超大规模上下文窗口。


1. DeepSeek 大语言模型系列
这是深度求索最具代表性的技术成果,基于自主优化的 Transformer 架构,通过大规模多模态数据(文本、代码、音频、图像、视频)预训练,并采用全栈多模态统一建模技术——从底层打通模态间语义鸿沟,实现跨模态信息的精准对齐,大幅提升了模型的理解与交互能力,同时通过多维度安全对齐训练,降低有害信息生成概率,保障各类场景下的应用安全。
- DeepSeek 1.0 基础系列
2022 年发布,是深度求索首款全栈多模态大模型,首次展现了全栈多模态架构的技术优势,在文本理解、代码生成、多模态交互等场景中表现出色,奠定了 DeepSeek 系列的技术基础。 - DeepSeek 1.0 Pro
面向大众与开发者的主力模型,支持最长 64 万 tokens 的上下文窗口(约相当于 48 万字文本),可直接处理长篇文档、代码库等大体积内容;同时开放了网页版对话界面与 API 服务,支持复杂的推理任务(如数据分析、报告撰写、语言翻译),并具备高效的响应速度,是深度求索面向消费级与中小开发者的核心解决方案。
- DeepSeek 1.0 Ultra
2023 年发布的旗舰级模型,是当时国内能力领先的 AI 模型之一,在 MMLU(大规模多任务语言理解)基准测试中得分达 89.5%,接近人类专家水平。该模型支持最长 128 万 tokens 的上下文窗口,具备顶尖的多模态处理能力,可精准理解图像、视频中的复杂信息,擅长数理公式推导、大型代码库重构、金融合同审核等超复杂任务,主要面向企业级高端需求与科研场景。 - DeepSeek 2.0 系列
2024 年发布的重大升级版本,核心亮点是上下文窗口扩展至 1000 万 tokens(约 750 万字文本),可一次性处理整套技术文档、完整的会议录音转写文本、超大型代码库等超大规模内容;同时优化了多模态处理效率,支持数小时级别的长视频理解,大幅降低了“幻觉”概率,提升了事实准确性,在企业级文档处理、科研数据分析、金融量化分析等场景中优势更为突出。 - DeepSeek Lite/Mini
面向移动设备的轻量化模型,专为国产终端系统优化,可在手机、平板等设备本地离线运行,实现低延迟响应。其中 DeepSeek Lite 主要集成于多款国产智能手机的 AI 功能中,支持语音助手增强、本地文档总结、实时翻译等轻量场景;DeepSeek Mini 则进一步提升了移动端运行效率,拓展了本地代码辅助、离线多模态问答等更多交互功能,推动 AI 能力向终端设备深度渗透。
针对国内用户,由于部分海外服务访问限制,可以通过国内平台“能用AI”获取API Key。
优化建议:
如果你的项目访问量较大,建议增加缓存机制。我们团队在优化后,接口响应时间从800ms降到了50ms, 效果非常明显。具体的缓存策略可以根据业务场景调整。
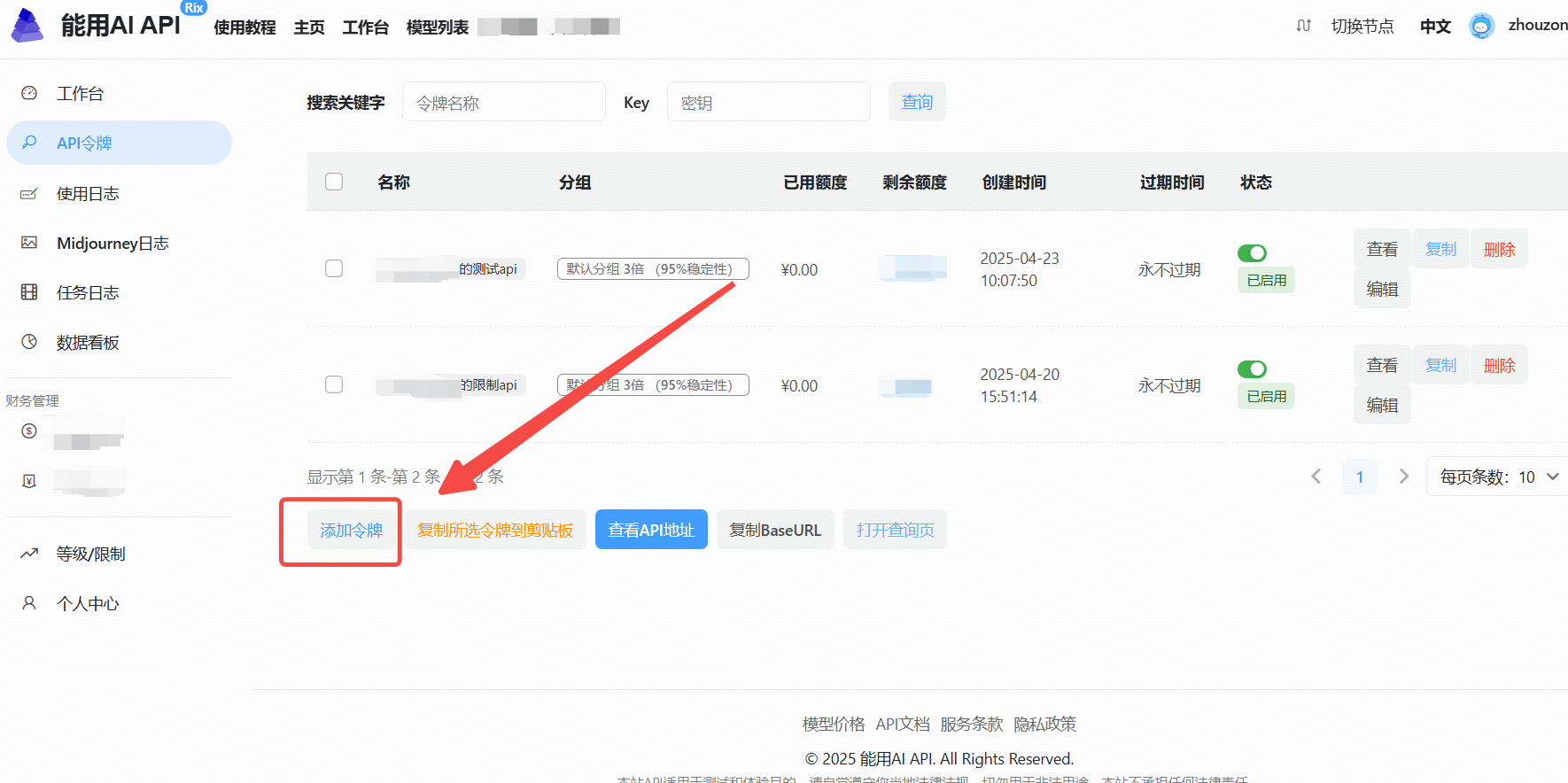
1. 访问能用AI工具
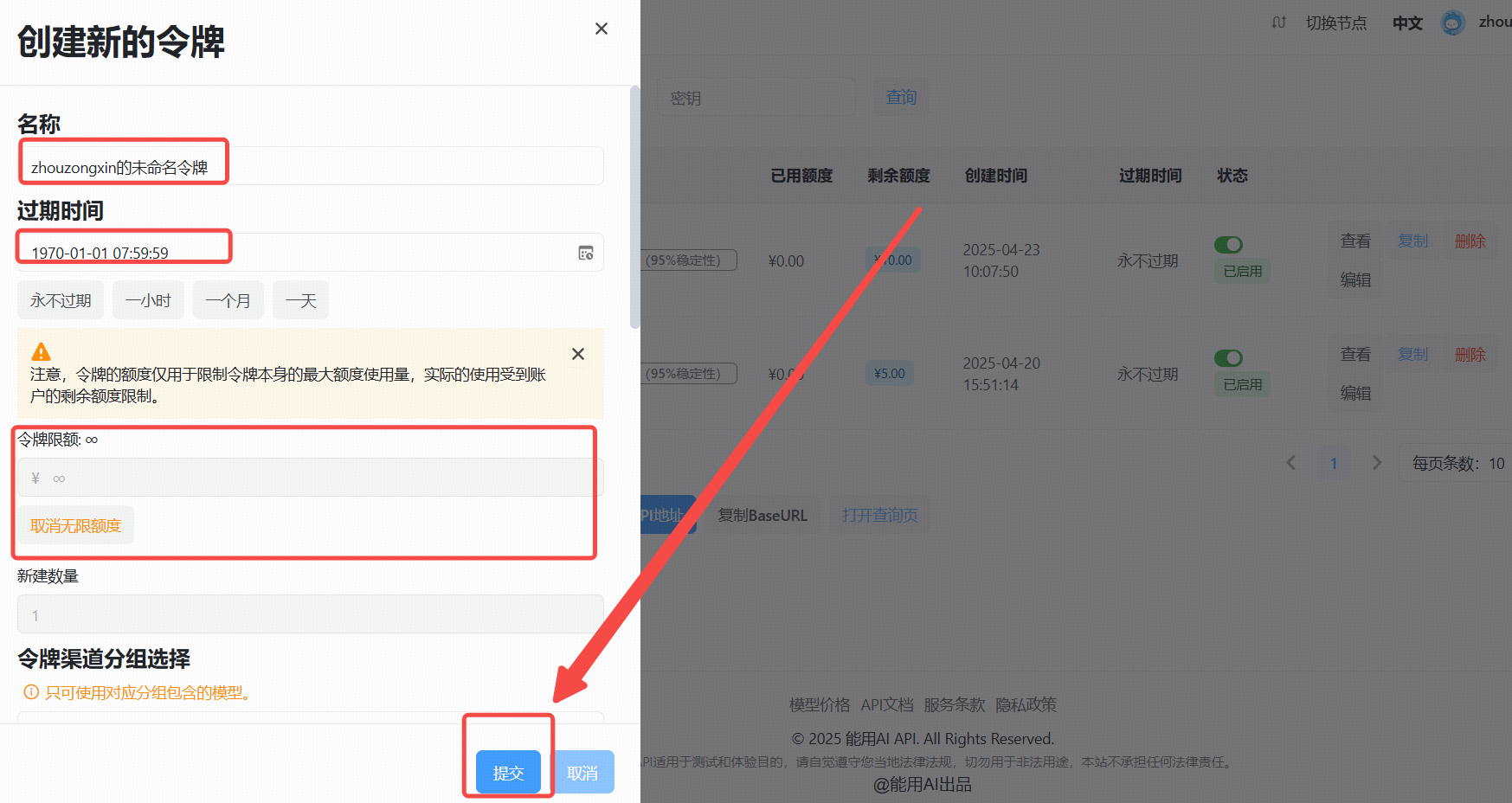
2、生成API Key
- 点击“添加令牌”按钮。
- 创建成功后,点击“查看KEY”按钮,获取你的API Key。
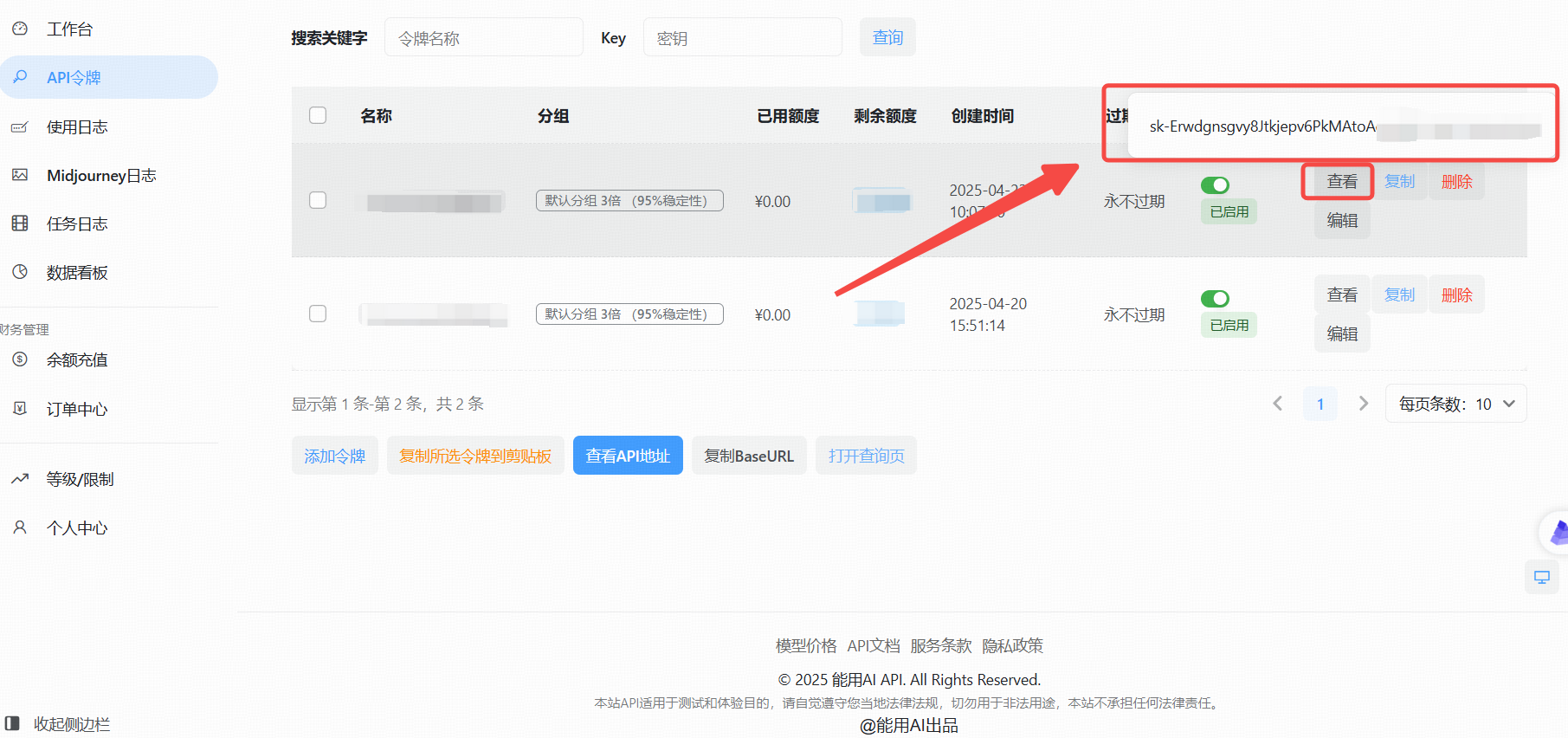
3、使用大模型 API的实战教程
拥有了API Key后,接下来就是如何在你的项目中调用大模型 API了。以下以Python为例,详细展示如何进行调用。
(1).可以调用的模型
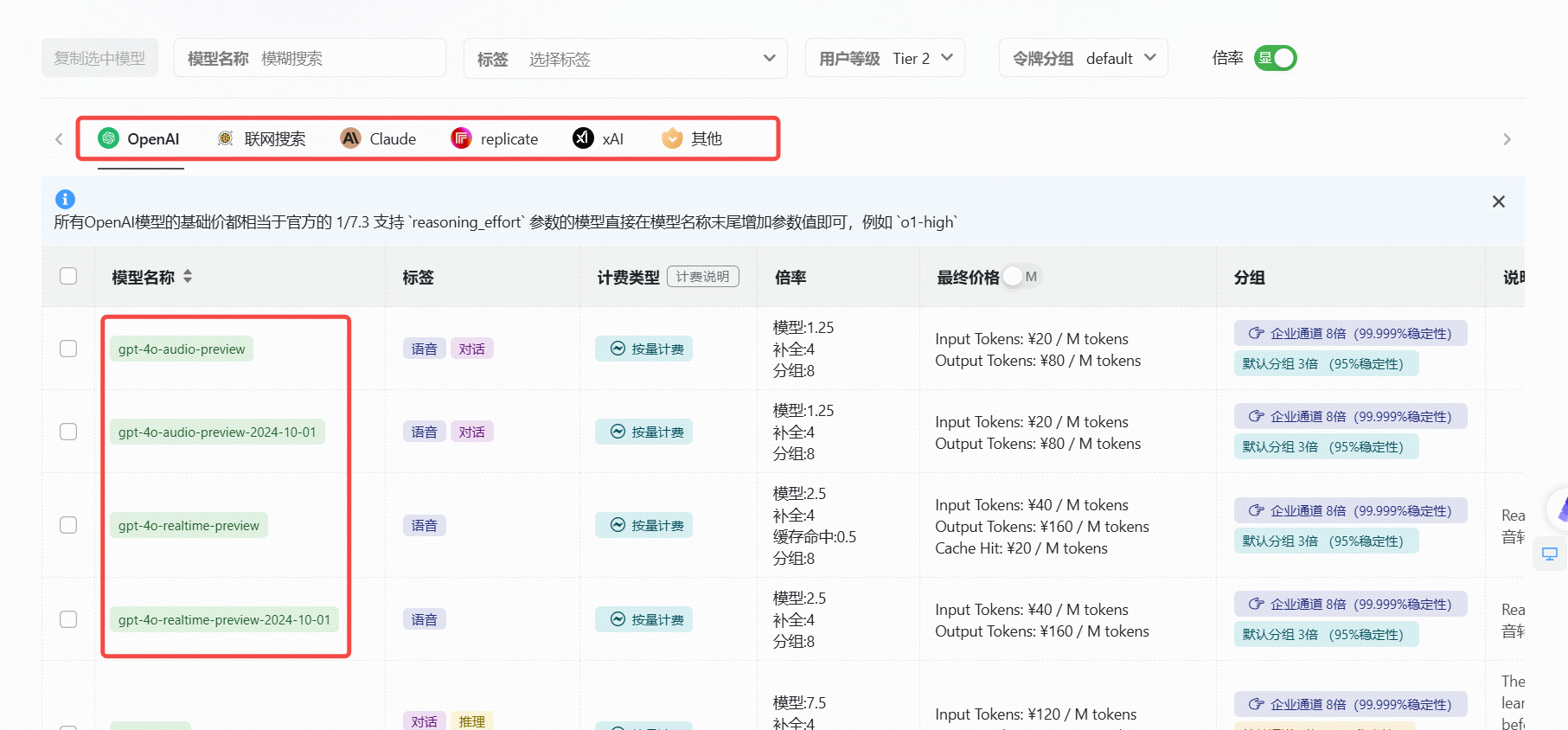
(2).Python示例代码(基础)
基本使用:直接调用,没有设置系统提示词的代码
(3).Python示例代码(高阶)
进阶代码:根据用户反馈的问题,用Claude进行问题分类

通过这段代码,你可以轻松地与AI模型进行交互,获取所需的文本内容。✨
【OpenAI】获取OpenAI API Key的多种方式全攻略:从入门到精通,再到详解教程!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:Ai探索者,转载请注明出处:https://javaforall.net/237653.html原文链接:https://javaforall.net


