
更新时间:2025-05-18 17:32:25
DeepSeek-R1是一款拥有671B参数规模的推理大模型,其在数学、编程和推理等复杂任务上的表现,已经与当前主流商业大模型不相上下。
本文详细介绍如何使用SGlang作为分布式推理方案,并基于Alaya NeW算力云的弹性容器集群,展示DeepSeek-R1私有化部署的最佳实践。通过这种组合,我们旨在提供一个灵活、可扩展且高性能的解决方案,以支持深度学习模型的高效部署与运行。这一方法不仅提升了模型推理的效率,还确保了在私有化环境下的稳定性和安全性。
- 用户已经获取Alaya New企业账户和密码,如果需要帮助或尚未注册,可参考注册账户完成注册。
- 当前企业账号的余额充裕,可满足用户使用推理计算服务的需要。点击可了解费用信息,如需了解更多请联系我们。
本次部署会用到 和 ,请先确保本地有可用的Kubernestes客户端工具kubectl,此次的最佳实践以系统添加环境为例,配置环境变量的操作步骤如下所示。
- 通过以下网址下载最新版本的kubectl,本实践下载“windows-amd64-v1.27.3-kubectl.exe”文件,在本地新建“kubectl”文件夹,将下载的文件名称修改为“kubectl”并移动到新建的文件夹下,如果用户需要获取其他版本安装包可通过更多kubectl版本获取。
- 通过以下网址下载最新版本的helm。本实践下载“helm-v3.17.1-windows-amd64.zip”文件,在本地解压上述文件,将文件名修改为“helm”,如果用户需要获取其他版本安装包可通过以下网址获取helm。
- 右键点击[此电脑/属性]菜单项,进入[系统/系统信息]配置页面,点击“高级系统设置”链接。
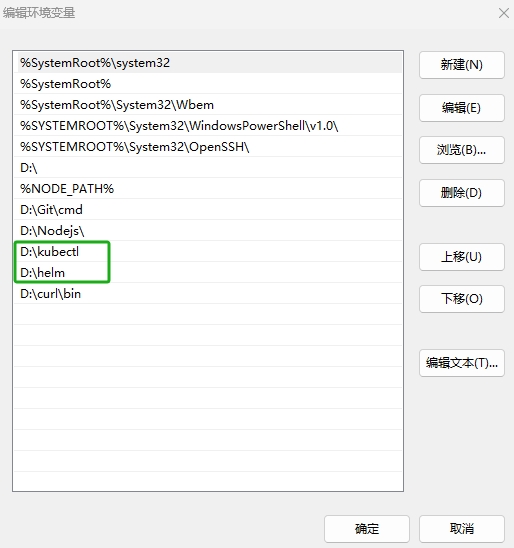
- 在[系统属性]页面中,点击[环境变量]按钮,进入环境变量配置页面。
- 在“系统变量”处双击 变量新建环境变量,新建如下图所示的环境。新建完成后,单击[确定]按钮,配置环境变量操作完成。

DeepSeek-R1模型的参数规模为6710亿,模型的文件大小约为642G。因此,在部署前需要准备足够的资源,用户需要保证资源至少满足下表中的配置要求。
开通弹性容器集群可参看开通弹性容器集群操作步骤章节所述。集群开通完成后可在使用弹性容器集群处查看弹性容器集群的使用方式。
此次的最佳实践配置弹性容器集群的操作步骤如下所示。
- 使用已注册的企业账号登录Alaya NeW系统,账户注册详情可参看注册账户章节所述,登录后进入[产品目录]页面。
- 单击“新建集群”按钮,进入[弹性容器集群]配置页面,配置基本信息,例如:集群名称,集群描述,智算中心,此次使用的集群配置如下所示。
配置项配置详情集群名称deeepseek-test智算中心北京一区算力配置1、型号:H800
2、配额:16卡GPU存储配置1、选择大容量存储
2、开启StorageClass开关对外服务开启对外服务开关
- 弹性容器集群参数配置完成后,单击“立即开通”按钮,资源开通操作完成,用户可在[资源中心/弹性容器集群]页面查看已创建的容器集群,弹性容器集群状态为“运行中”表示集群可正常使用,如下图蓝色高亮处所示。
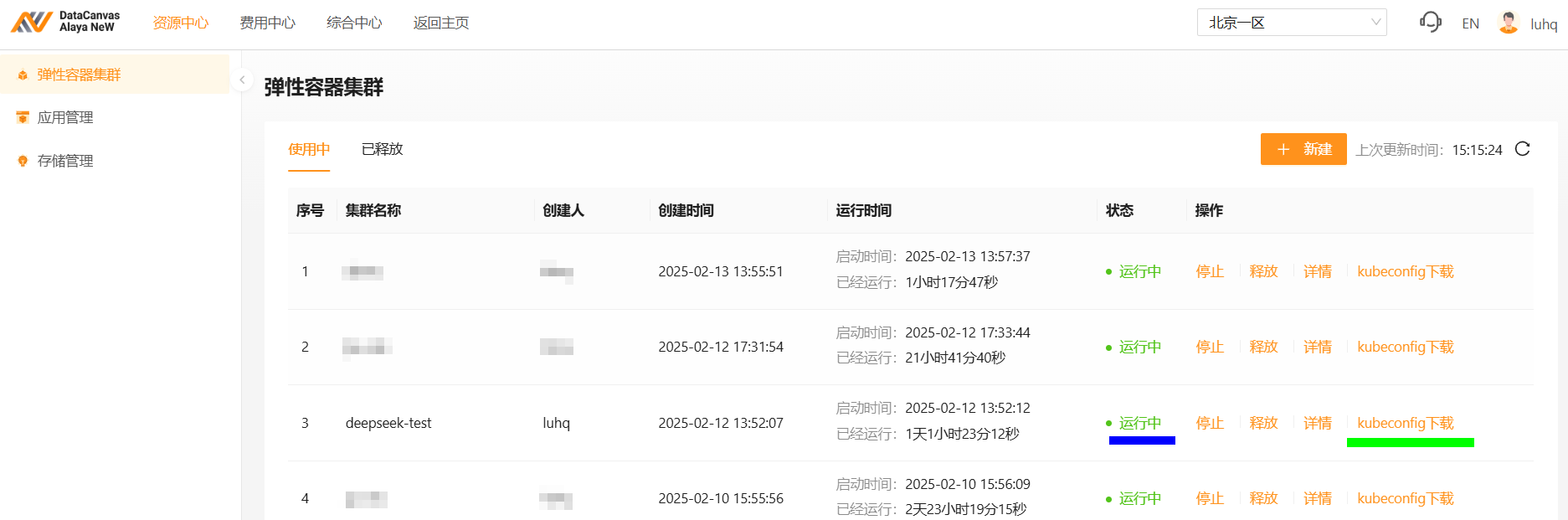
- 集群可正常使用后,点击“kubuconfig下载”链接,如上图绿色高亮处所示,将集群的kubeconfig配置文件下载到本机上。
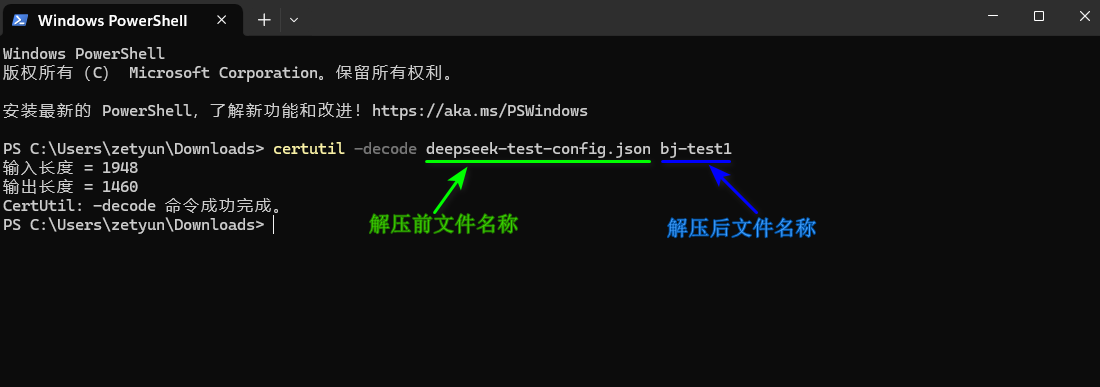
- 在本机上找到上步已经下载的文件,DeepSeek 教程本实践中为“deepseek-test-config.json”,使用命令解压该文件,如下图所示。
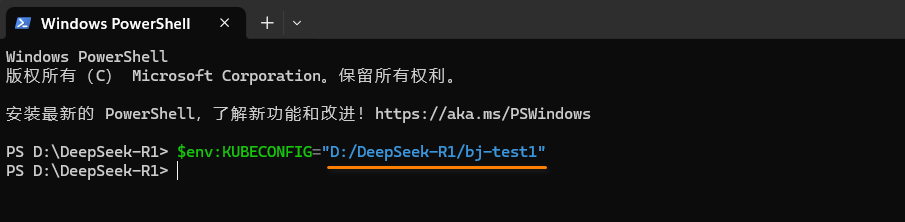
- 在终端页面,使用命令配置访问弹性容器集群的环境变量,本实践的路径如下图所示。
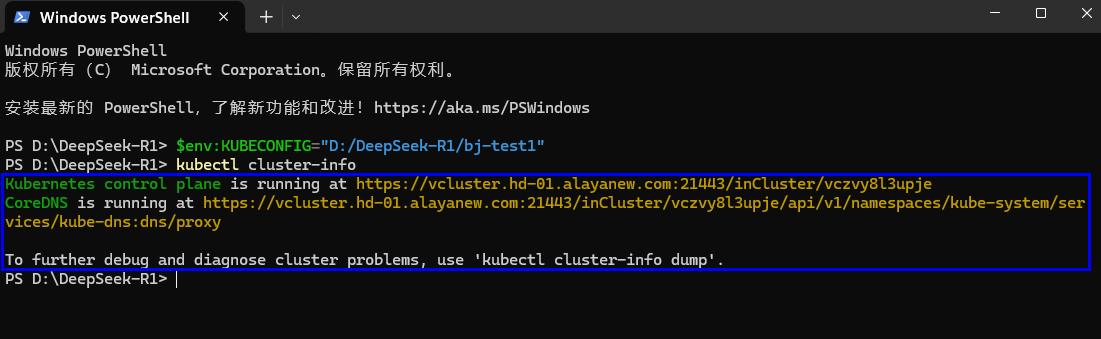
- 在终端页面执行如下命令,查看集群是否连接成功。若显示如下图所示,表示弹性容器集群连接成功。
- 为了方便操作,用户可点击此处下载配置文件及示例代码,下载并解压后的文件内容如下表所示。
- 双击进入上步已解压的“Deepseek-R1”文件夹,打开终端,执行如下的命令,创建一个名为“deepseek”的NameSpace。
- 执行如下命令将YAML文件中定义的资源配置应用到集群中。
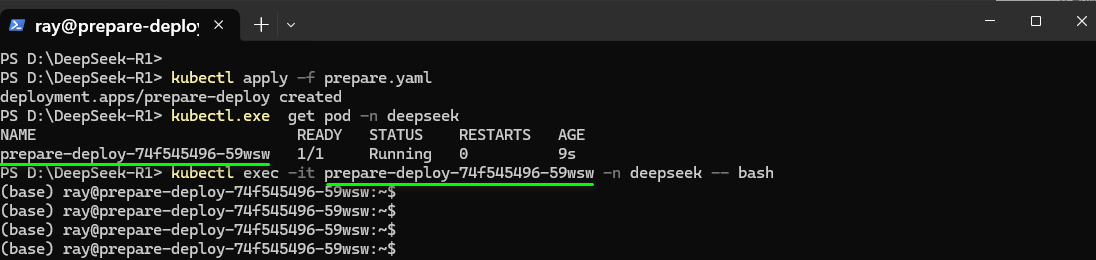
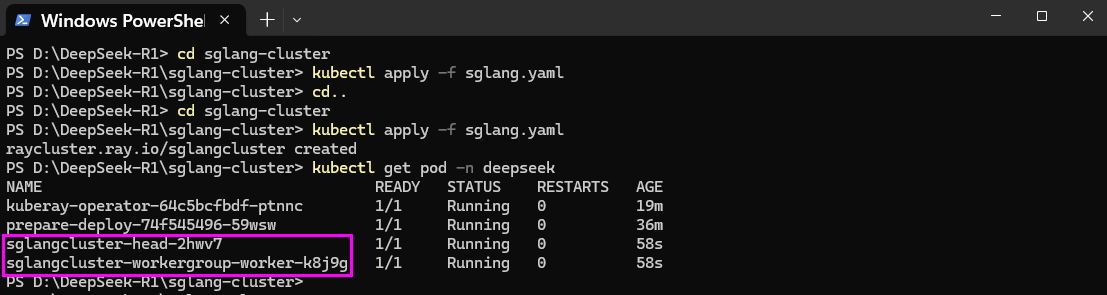
- 资源应用完成后,请执行以下命令查看“deepseek”命名空间下Pod的运行状态。当Pod的状态显示为“Running”时,表明其已成功启动并正常运行,即可用于后续配置。
- Pod启动成功后,在终端页面执行如下命令进入上一步骤创建的Pod。
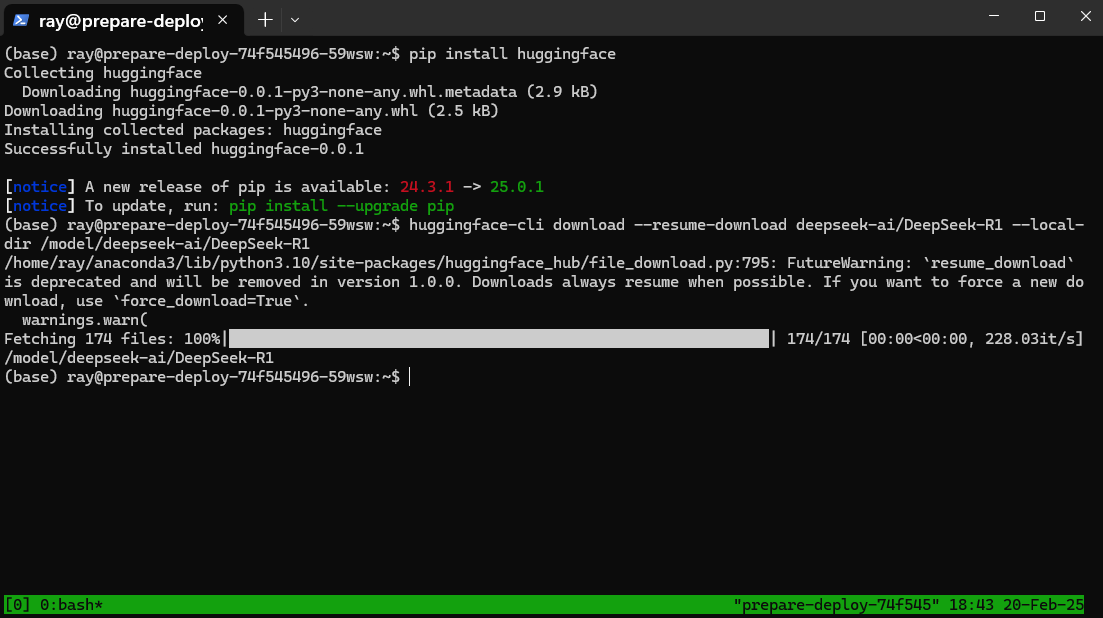
- 为了简化后续操作,建议在终端中执行命令以创建一个新的会话。有关此工具的详细使用方法,请参阅Tmux的使用的使用。然后,在新开启的Tmux会话中,在新开启的会话页面执行如下所示的命令安装huggingface工具。
- 上述工具安装完成后,在终端执行以下命令下载DeepSeek-R1模型,如下图所示。
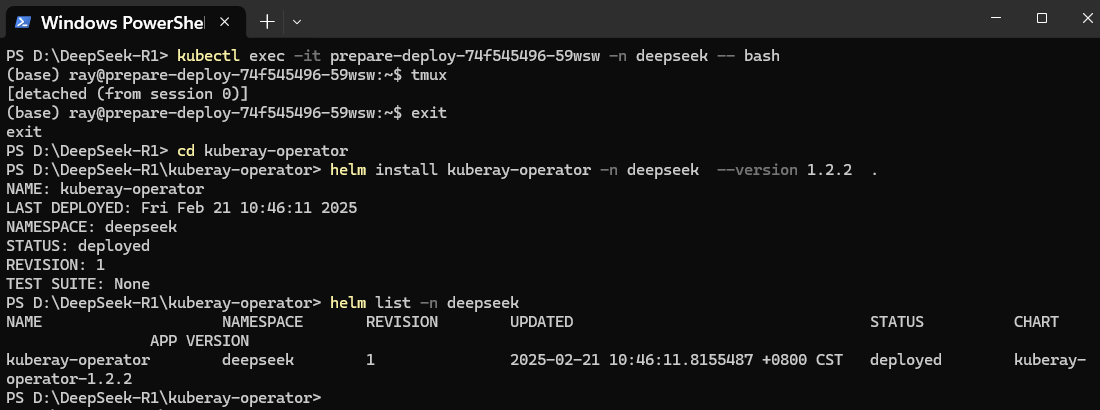
- 在终端页面进入kuberay-operator目录,使用如下的命令部署kuberay-operator集群。
- 成功部署kuberay-operator后,执行以下命令来检查已部署资源的状态。当kuberay-operator的“STATUS”显示为“deployed”时,表明该资源已成功部署并可正常使用。
- 在确认上一步的资源已成功部署并可正常使用后,请保持在同一个终端页面中,进入sglang-cluster文件夹目录,并执行以下命令,启动SGlang服务。
- 服务启动成功后,在终端页面执行如下命令查看服务运行情况,所有Pod运行状态均为“Running”,如下图所示,表示资源可正常使用。
在弹性容器集群中,对于需要外部访问的服务,我们可以使用。是弹性容器集群中用于将服务暴露到外部的组件,将其与需要对外提供服务的绑定,为用户提供外部访问的地址。获取访问地址的步骤如下所示。
- 在上一章节所用的同一终端页面中,执行如下命令创建ServiceExporter资源。
- 资源创建成功后,请在终端页面执行以下命令,以查看“deepseek”命名空间中运行的所有服务列表,并获取SGlang的服务名称。本实践名称为“sglangcluster-head-svc”。
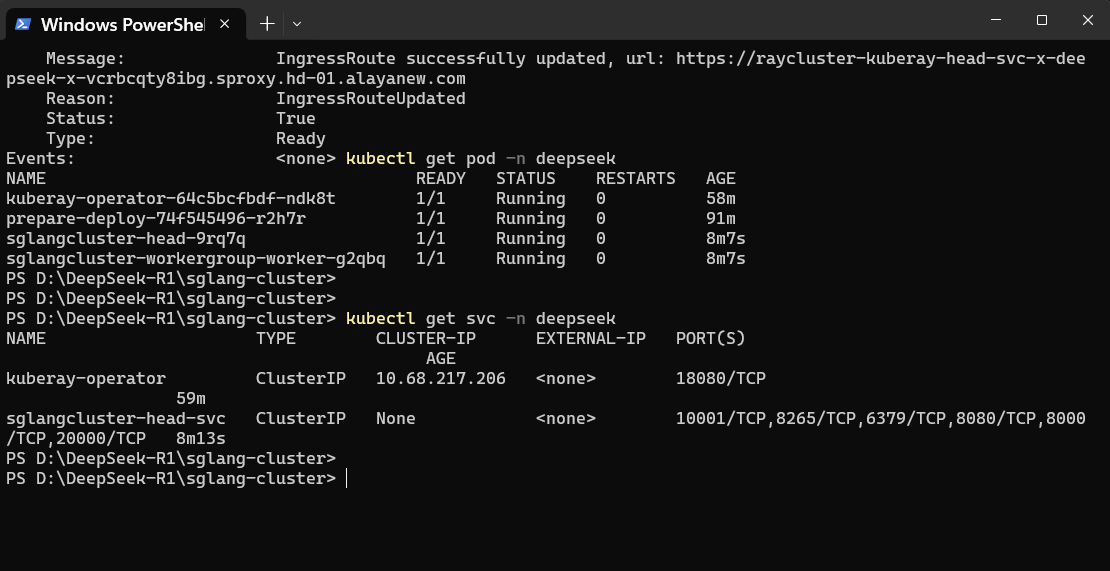
在终端页面查看 的信息获取服务访问的地址。通过 方式暴露的服务端口均为“22443”。
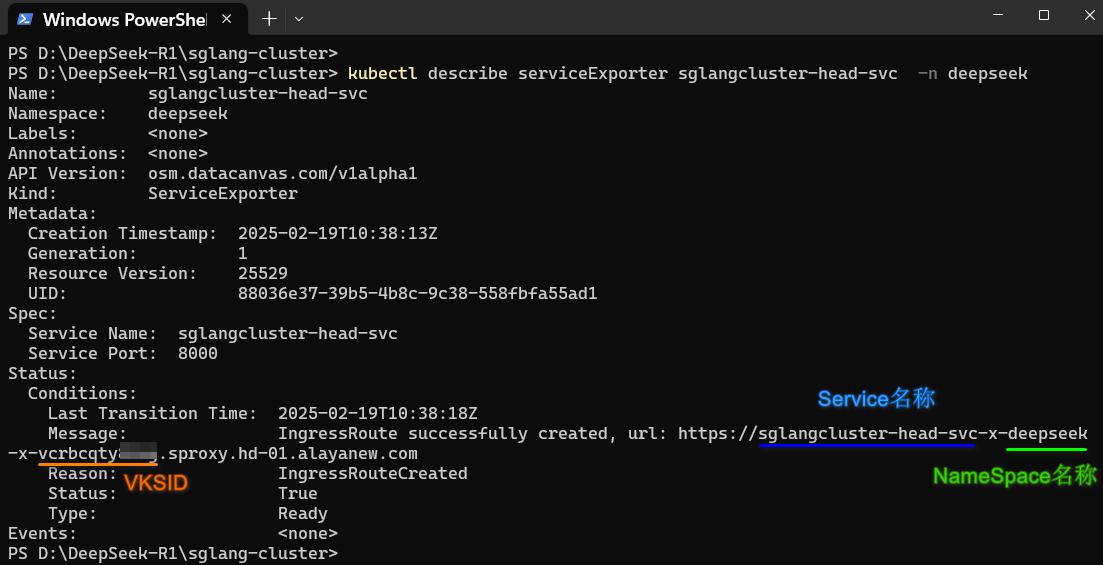 用户在实际的应用中,需要将本实践中的参数替换为实际的参数,以上图中高亮的URL地址为例,其组成有如下几个部分。
用户在实际的应用中,需要将本实践中的参数替换为实际的参数,以上图中高亮的URL地址为例,其组成有如下几个部分。
不同操作系统获取VKSID的命令行如下所示。
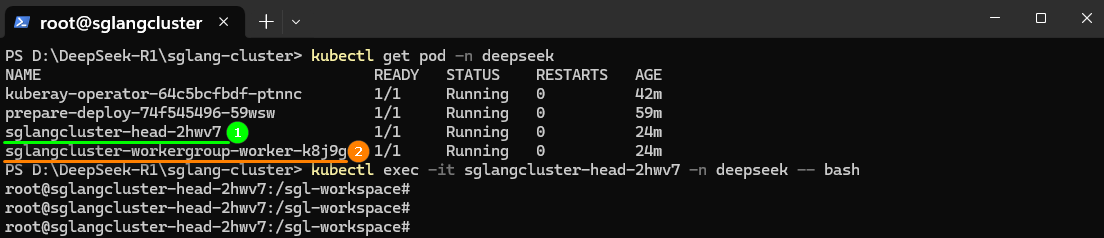
- SGlang服务启动成功后,在上一章节所用终端页面执行如下命令进入SGlang服务的其中一个容器,如下图所示。
- 执行命令打开新会话。在新会话页面执行以下命令部署DeepSeek-R1模型。
- 重新开启一个终端页面,执行如下命令连接弹性容器集群。
- 集群服务连接成功后,在上述终端页面进入SGlang服务的另一个Pod,Pod名称可从本章节第1步中获取。
- 执行命令打开新会话,在新会话页面执行以下命令部署DeepSeek-R1模型。
- 在本章节第2步的终端页面查看模型部署进度,部署页面如下图所示。
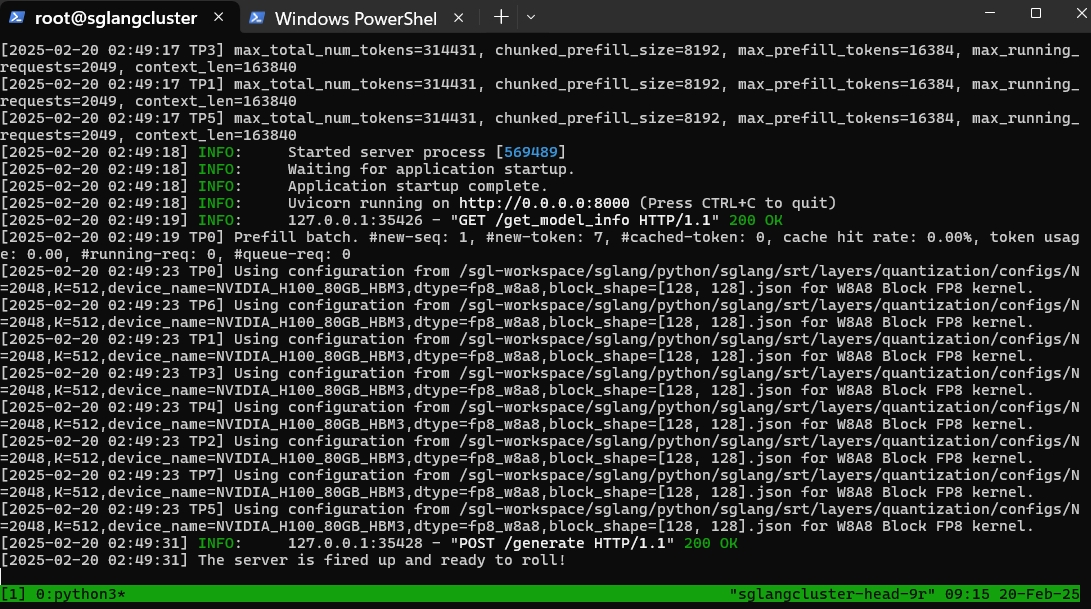
🎉️ 模型部署成功后,用户在终端管理页面可使用命令行工具向已部署的服务发送HTTP请求,观察数据响应情况,如下所示,以此来验证服务已经部署成功。
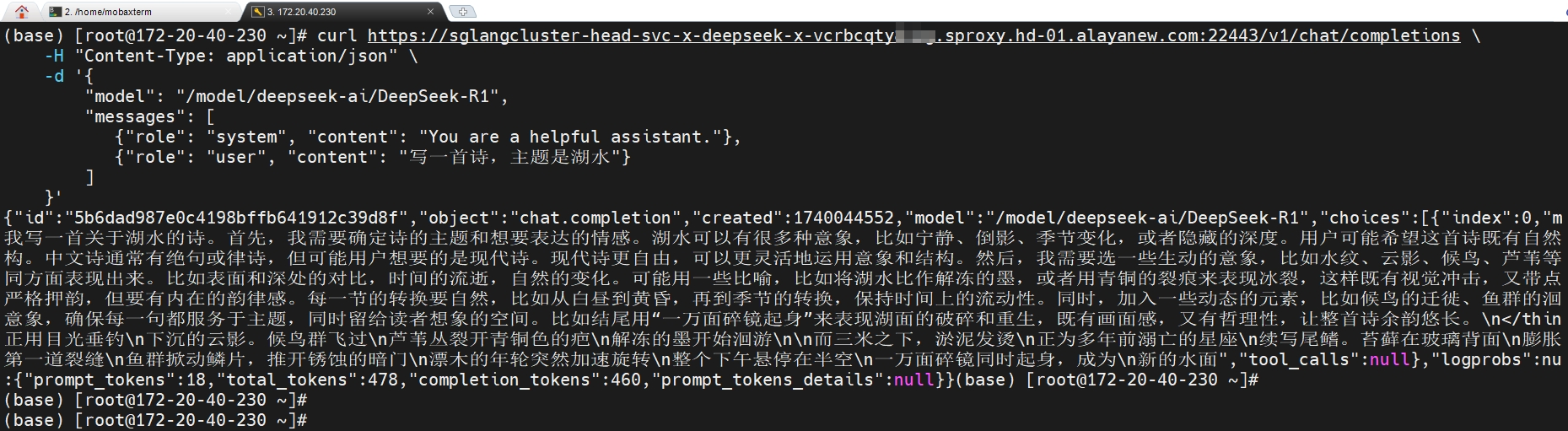
🎉️ 除了上述访问方式外,用户还可以通过Python代码使用已部署的服务。
🎉️ 此外用户也可使用跨平台AI客户端工具,例如AnythingLLM、Chatbox AI、Cherry Studio等客户端工具,调用已部署的服务。本实践以Chatbox AI工具为例,服务调用页面如下所示。
至此,我们已经完成了使用SGlang部署DeepSeek-R1模型的全部流程。本文档为DeepSeek-R1的私有化部署提供了一个全面的指南,内容涵盖了从环境配置到模型推理访问的各个技术环节。借助分布式推理模式,不仅能够充分发挥大型模型的性能潜力,还加速了AI应用的规模化实施。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/239660.html原文链接:https://javaforall.net


