
这两天Manus团队披露了不少Manus的技术细节,包括没有使用MCP,而是使用了CodeAct。

使用CodeAct的原因:
- 编程并非终极目标,而是解决通用问题的一种普适方法。
- 由于大语言模型(LLMs)在编程方面表现出色,因此让Agent执行与其训练分布最接近的任务是合理的。
- 这种方法显著减少了上下文长度,并能够组合复杂的操作。
我把CodeAct的论文和资料简单过了一下:
代码地址:https://github.com/xingyaoww/code-act
运行效果:
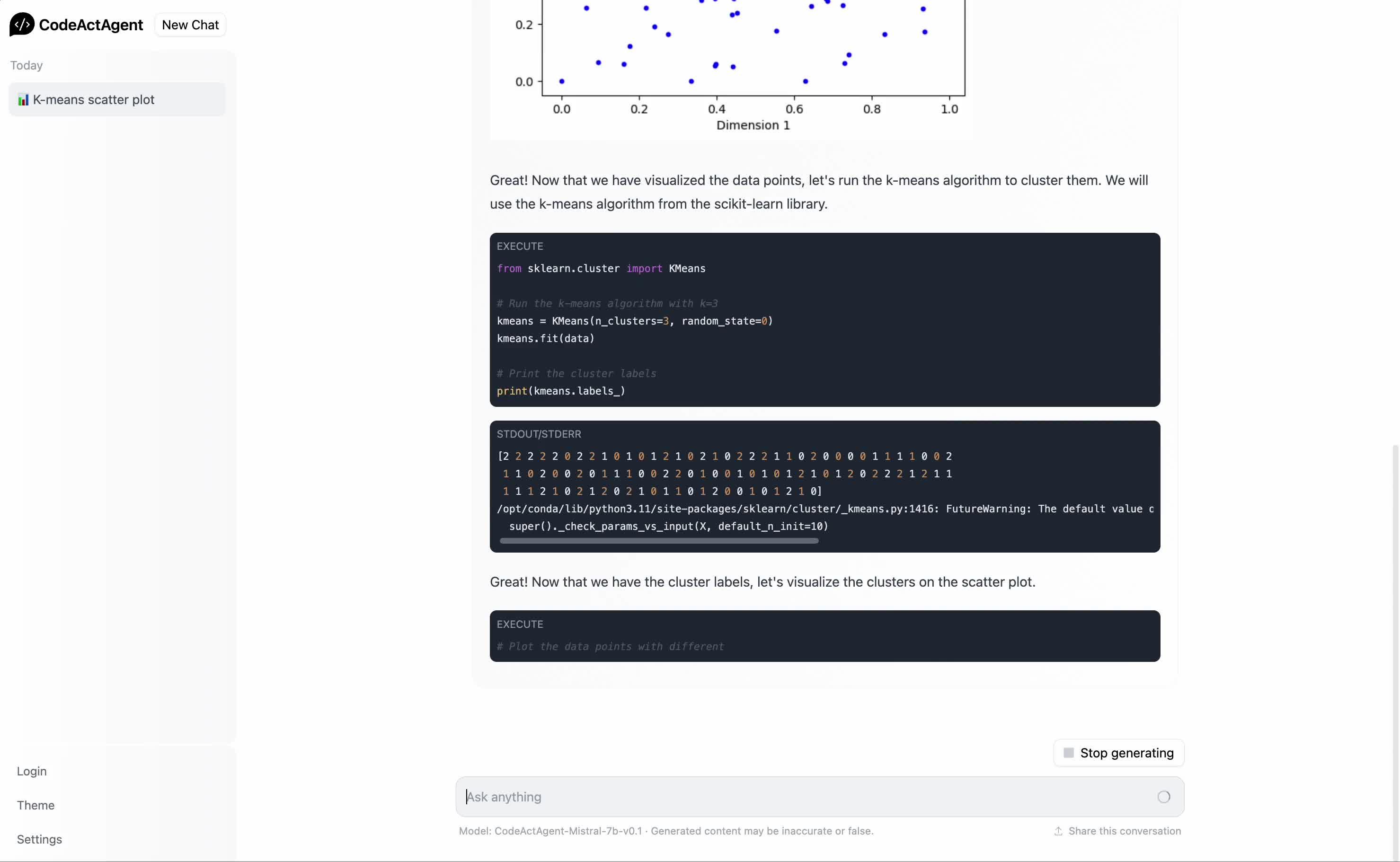
https://www.zhihu.com/video/
论文地址:Executable Code Actions Elicit Better LLM Agents
大语言模型(LLM)在自然语言处理(NLP)领域取得了突破性进展。通过增加行动模块,LLM的行动空间不再局限于文本处理,而是能够调用API、管理内存,甚至控制机器人(如Ahn等,2022;Huang等,2023;Ma等,2023)。然而,现有的LLM Agent通常通过生成JSON或预定义格式的文本来产生行动,这种方式在行动空间和灵活性上存在局限。本文提出了一种新的框架——CodeAct,通过生成可执行的Python代码来统一LLM Agent的行动空间。CodeAct集成了Python解释器,能够执行代码并根据多轮交互中的新观察动态调整行动。实验表明,CodeAct在多个基准测试中表现优异,成功率达到20%的提升。
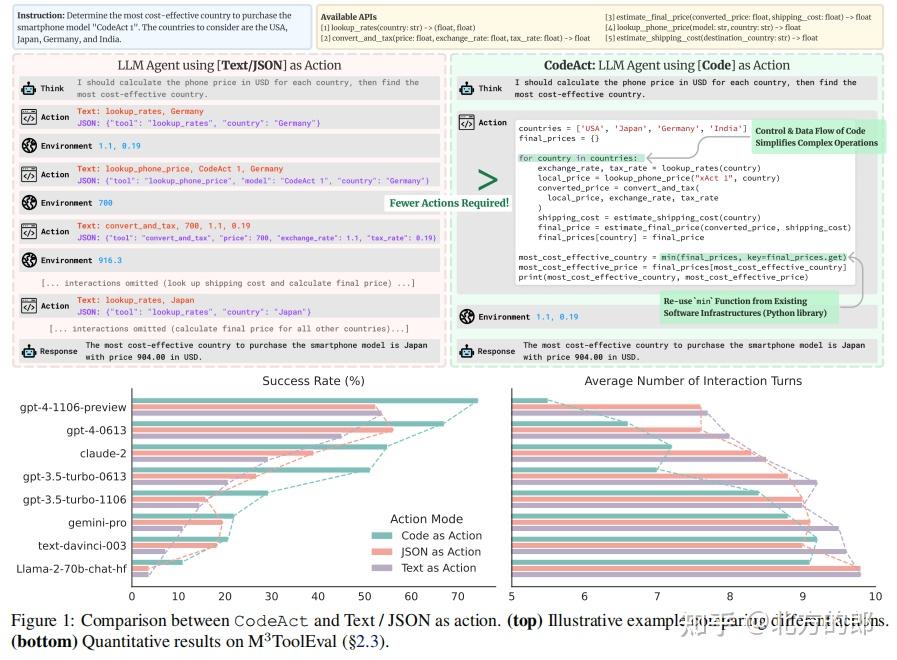

CodeAct是一个通用的多轮交互框架,适用于LLM Agent的实际应用。它定义了三个角色:Agent、用户和环境。Agent通过与用户或环境的交互接收观察(输入),并通过生成Python代码来执行行动(输出)。CodeAct的核心思想是将所有与环境交互的行动统一为Python代码,Agent通过执行代码并接收执行结果来进行多轮交互。

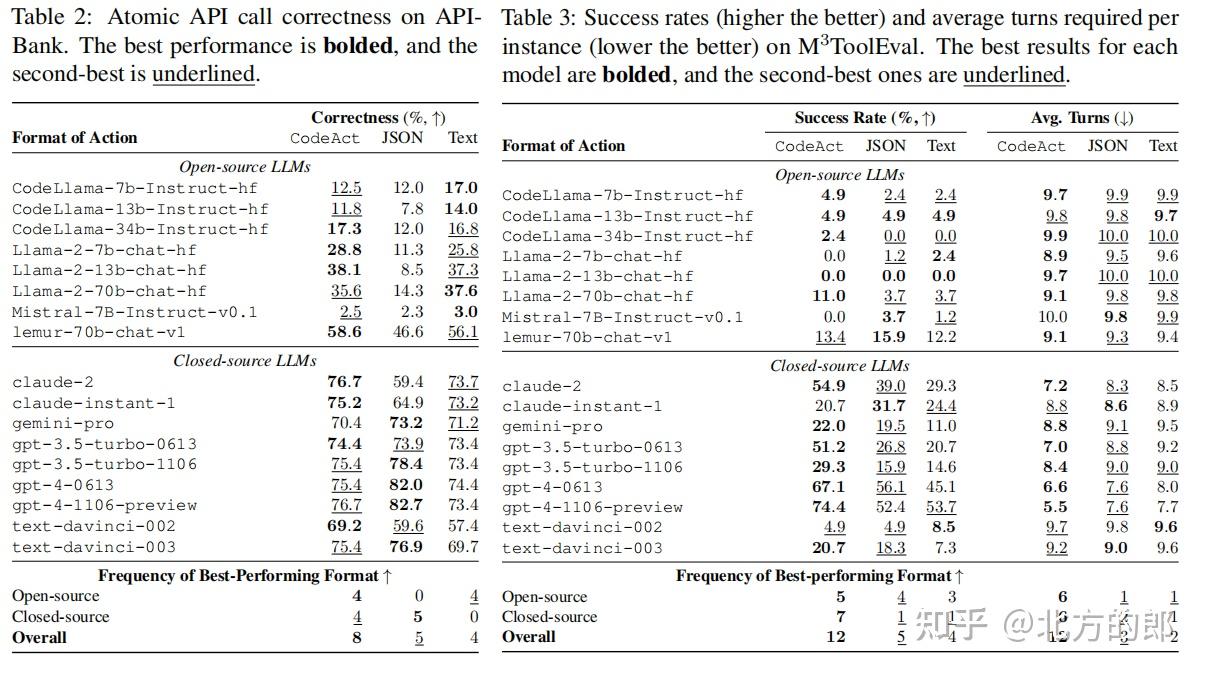
为了验证CodeAct的有效性,本文进行了一系列实验,比较了CodeAct、JSON和文本格式在工具调用任务中的表现。实验结果表明,CodeAct在大多数LLM上表现优于或至少不逊色于JSON和文本格式。特别是在开源模型上,CodeAct的优势更为明显,因为开源模型在预训练阶段接触了大量的代码数据,使得它们更容易适应CodeAct的格式。
为了进一步验证CodeAct在复杂任务中的表现,本文构建了一个新的基准测试——M3ToolEval,该基准包含82个需要多轮交互和多工具调用的复杂任务。实验结果显示,CodeAct在大多数LLM上取得了更高的任务成功率,并且所需的交互轮次更少。例如,GPT-4在使用CodeAct时,任务成功率提升了20.7%,且平均交互轮次减少了2.1次。
CodeAct通过与Python解释器的集成,能够利用现有的Python软件包执行复杂任务。例如,CodeActAgent可以使用Pandas处理数据、使用Scikit-Learn进行机器学习模型训练,并使用Matplotlib进行数据可视化。此外,CodeActAgent还能够通过多轮交互中的错误信息进行自我调试,进一步提升任务解决能力。
为了提升开源LLM Agent的CodeAct能力,本文收集了一个名为CodeActInstruct的指令微调数据集,该数据集包含7000多条高质量的Agent与环境交互轨迹。CodeActInstruct涵盖了信息检索、软件包使用、外部内存访问和机器人规划等多个领域,旨在提升Agent在多轮交互中的自我改进能力。

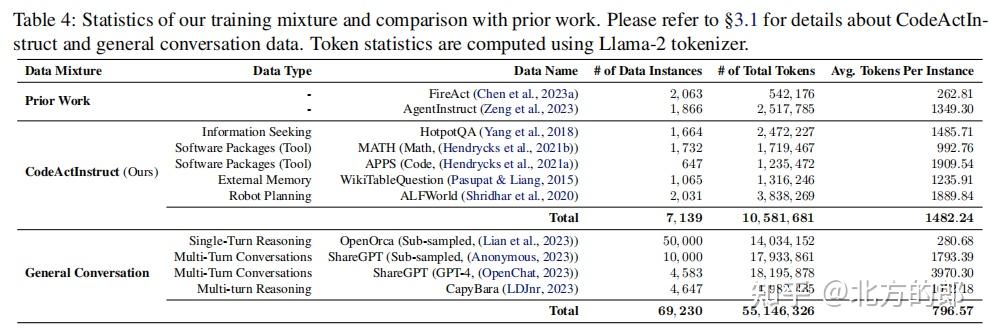
本文基于LLaMA-2和Mistral-7B模型,通过微调CodeActInstruct和通用对话数据,构建了CodeActAgent。实验表明,CodeActAgent在多个任务中表现优异,特别是在使用CodeAct作为行动格式时,任务成功率显著提升。此外,CodeActAgent在文本行动格式的任务中也表现出色,展示了其良好的泛化能力。

现有的LLM Agent通常由四个组件构成:定制化配置文件、长期记忆能力、推理与规划算法以及行动模块。行动模块是LLM Agent与外部实体(如人类和工具)交互的关键。本文提出的CodeAct框架通过统一行动空间,显著提升了LLM Agent的交互能力。
提升LLM Agent的主要方法包括提示工程和指令微调。提示工程通过设计特定的提示策略来提升模型的推理能力,而指令微调则通过微调模型来提升其在特定任务中的表现。本文的CodeActInstruct数据集通过收集多轮交互轨迹,显著提升了LLM Agent在多轮交互中的自我改进能力。
CodeAct框架通过将LLM Agent的行动统一为可执行的Python代码,显著提升了其在复杂任务中的表现。CodeAct不仅能够动态调整行动,还能利用现有的软件包进行自我调试。本文还收集了CodeActInstruct数据集,并通过微调LLaMA-2和Mistral-7B模型,构建了CodeActAgent,展示了其在多个任务中的卓越表现。
——完——
@北方的郎 · 专注模型与代码
喜欢的朋友,欢迎赞同、关注、分享三连 ^O^
发布者:Ai探索者,转载请注明出处:https://javaforall.net/244735.html原文链接:https://javaforall.net


