
📖 论文标题:A-Mem: Agentic Memory for LLM Agents
👥 作者:Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, Yongfeng Zhang
🏫 机构:Rutgers University, Ant Group, Salesforce Research
📅 发表:NeurIPS 2025
🔗 代码:https://github.com/WujiangXu/AgenticMemory
A-Mem 借鉴德国社会学家卢曼的”卡片盒笔记法”,为LLM智能体设计了一套能自主构建、动态链接、持续进化的记忆系统,让智能体不再只是”死记硬背”,而是像人类一样建立起有机的知识网络。
想象你是一个客服智能体,用户问你:”我上周说的那个缓存问题解决了吗?“如果你只能机械地搜索”缓存”这个关键词,大概率会返回一堆不相关的技术文档。但如果你能像人类一样,把”这个用户”+“上周”+“缓存问题”+”他当时在做的项目”这些信息有机关联起来,回答就会精准得多。
这就是当前LLM智能体记忆系统面临的核心问题。
什么是LLM Agent的记忆系统?
在深入A-Mem之前,先厘清几个基本概念。LLM Agent的记忆系统通常分为三层:
A-Mem主要关注的是情景记忆——如何有效地存储、组织和检索历史交互信息。
传统记忆系统的困境
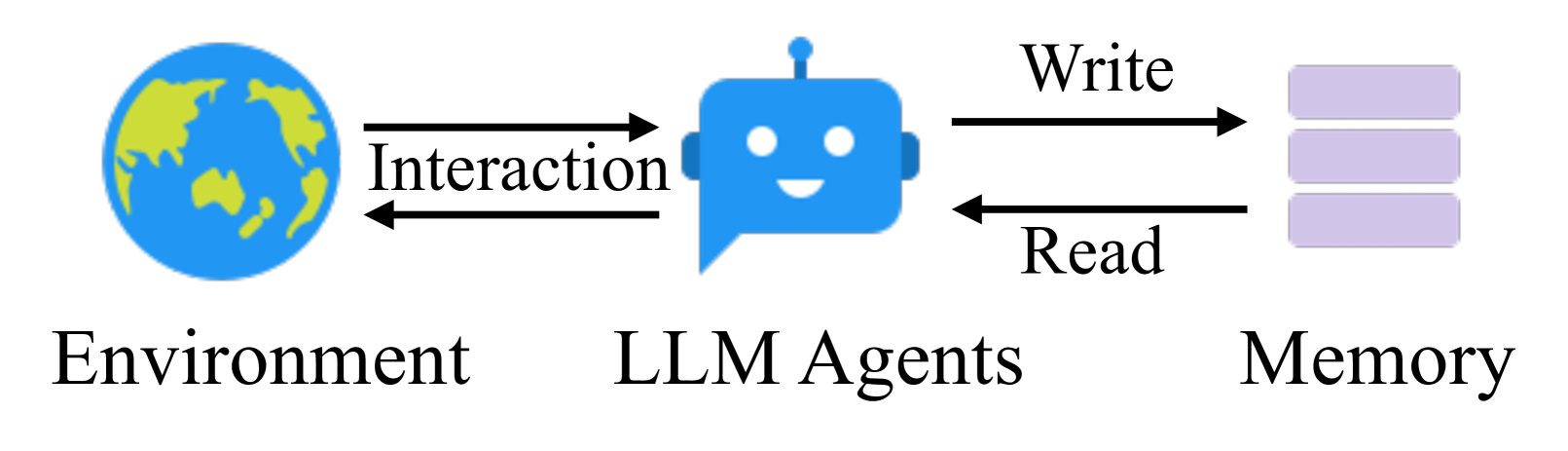

图1:传统记忆系统只提供简单的读写接口,智能体与记忆之间是”死”的交互
传统记忆系统的三大痛点:
即便是MemGPT这类尝试引入图数据库的系统,也存在一个根本性问题:它们的记忆结构是人为预设的,而不是根据实际交互动态演化的。这就像让你用一套固定的文件夹分类法整理所有笔记——对某些内容很有效,对另一些则完全不适用。
以MemGPT为例,它借鉴操作系统的虚拟内存概念,设计了主上下文(Main Context)和外部上下文(External Context)两层结构。智能体可以主动管理信息在两层之间的流动。这个思路很有创意,但问题在于:信息的组织方式是固定的,智能体只能决定”放哪里”,不能决定”怎么理解”。
A-Mem的灵感来源于德国社会学家尼克拉斯·卢曼(Niklas Luhmann)的卡片盒笔记法(Zettelkasten)。
卢曼一生发表了70多本书和400多篇论文,他的秘诀就是这套独特的笔记系统。核心原则很简单:
- 原子性:每张卡片只记录一个想法
- 链接性:卡片之间通过编号相互引用,形成网络
- 进化性:新卡片会促使你重新审视和更新旧卡片
图2:A-Mem不是被动的存储器,而是能主动组织、链接、进化记忆的”智能助手”
A-Mem把这套方法论迁移到了LLM智能体的记忆系统中。它不是简单地存储对话历史,而是:
- 为每条记忆生成结构化的笔记(包含关键词、标签、上下文描述)
- 自动分析新旧记忆之间的语义关联并建立链接
- 当新记忆加入时,触发相关旧记忆的更新
这样一来,记忆系统就从一个”死”的数据库,变成了一个能自我组织、持续进化的”知识网络”。
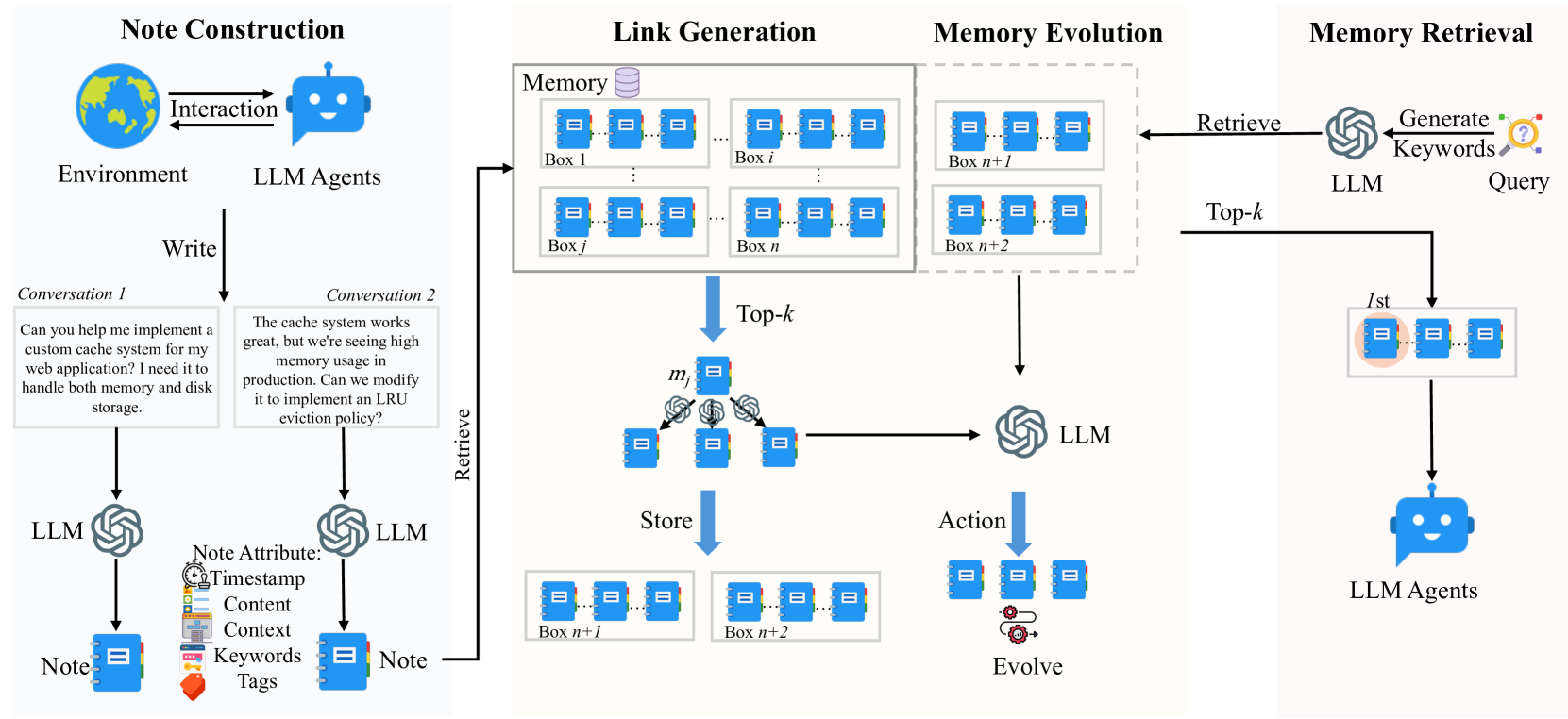
图3:A-Mem完整工作流程——从笔记构建、链接生成、记忆进化到检索使用
这张图展示了A-Mem的完整工作流。用一个具体例子来走一遍这个流程:
假设用户在第一次对话中问:”能帮我实现一个缓存系统吗?需要支持内存和磁盘存储。”一周后,用户又说:“缓存系统运行得不错,但生产环境内存占用太高,能加个LRU淘汰策略吗?”
机制一:笔记构建(Note Construction)
当第一次对话结束后,A-Mem不是直接存储原始文本,而是调用LLM生成一张结构化的”笔记卡片”:
关键在于那个字段。它不是对原始内容的复述,而是LLM对这条记忆潜在意义的理解——用户可能后续会有性能优化需求。这种”超出字面意思的理解”是A-Mem区别于传统系统的核心。
机制二:链接生成(Link Generation)
当第二次对话到来时,A-Mem会:
- 先用语义向量检索Top-k个相关的历史记忆
- 然后让LLM分析新记忆与候选记忆之间是否存在有意义的关联
- 建立链接关系
这里的关键不是简单的相似度匹配。LLM会判断记忆1和新记忆讲的是同一个项目的不同阶段,而记忆2、3虽然也涉及存储,但属于不同的技术场景。
机制三:记忆进化(Memory Evolution)
这是A-Mem最独特的地方。当新记忆与历史记忆建立链接后,系统会考虑是否需要更新历史记忆。
继续上面的例子,原来的记忆1变成了:
这种进化机制让记忆网络能够持续精炼——旧的记忆不再是静态的历史档案,而是会随着新信息的加入不断完善自己的描述。
用人类的记忆做类比:你第一次见某个人,只记得”他是做技术的”;后来你们聊过几次,你的记忆会自动更新成”他是做后端的,最近在搞性能优化,人挺nice”。A-Mem模拟的就是这种记忆的动态演化过程。
机制四:记忆检索(Memory Retrieval)
检索阶段相对简单:给定查询 ,系统首先将其编码为语义向量 ,然后计算与所有记忆笔记的余弦相似度:
返回相似度最高的Top-k个记忆作为上下文输入给智能体。
但由于前面的结构化处理,检索质量会高很多:
- 字段提供了更丰富的语义信息,使得语义向量能捕捉更深层的含义
- 和可以作为辅助匹配条件
- 可以用于扩展检索(检索到一条记忆后,顺着链接找到相关记忆)
核心算法流程
把上面四个机制串起来,A-Mem的完整工作流程可以用伪代码表示:
这段伪代码清晰地展示了A-Mem的核心逻辑。值得注意的是,语义向量是基于原始内容加上下文描述一起编码的,这让embedding能够捕捉到LLM理解后的”增强语义”,而不仅仅是原始文本的字面含义。
作者在LoCoMo数据集上进行了评估。这个数据集专门测试长对话场景下的记忆能力,平均每段对话有9000多个token,跨越35个会话,非常有挑战性。
主实验:全面领先
表1:GPT-4o-mini作为基础模型时的性能对比
几个值得关注的点:
1. 多跳推理能力提升惊人
A-Mem在多跳推理任务上达到45.85的F1分数,是MemGPT的1.8倍。多跳推理需要整合多条分散的记忆才能得出答案,这正是链接机制和记忆进化的用武之地。
2. Token效率极高
A-Mem只用了2520个token(约是LoCoMo的15%),就实现了全面领先的性能。这得益于选择性Top-k检索——只把真正相关的记忆放入上下文。
3. 在小模型上优势更明显
在Qwen2.5-1.5B和Llama 3.2-1B这样的小模型上,A-Mem的提升更加显著。这说明A-Mem的结构化记忆能够补偿小模型在长上下文理解上的不足。
消融实验:每个组件都不可或缺
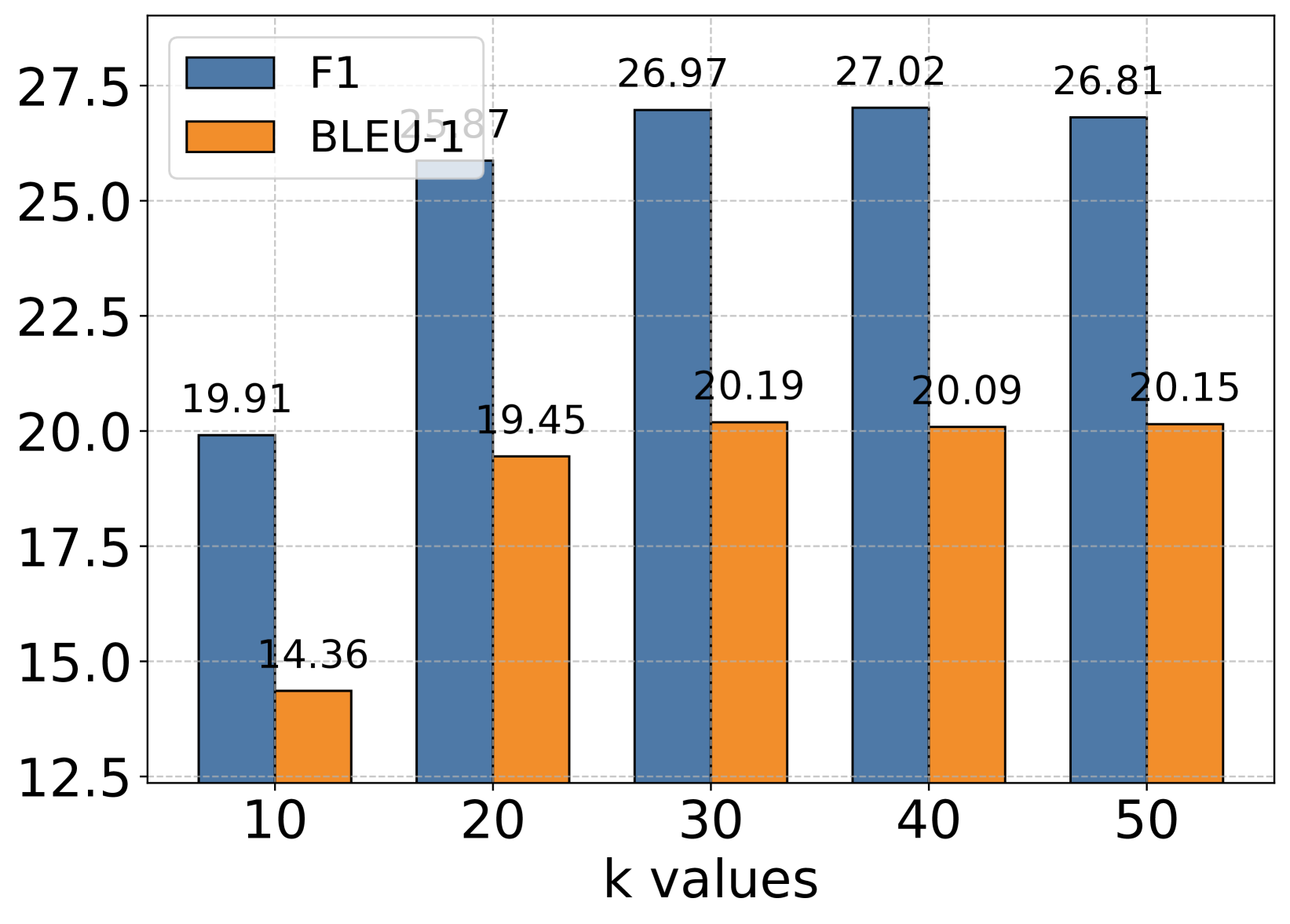
图4:消融实验——移除链接生成(LG)或记忆进化(ME)后的性能下降
链接生成的贡献更大(移除后下降6.88),但记忆进化的作用也不容忽视。两者是互补关系:链接生成建立了记忆之间的关联骨架,记忆进化则让这个骨架上的”血肉”更加丰满。
可视化分析:记忆组织更有结构
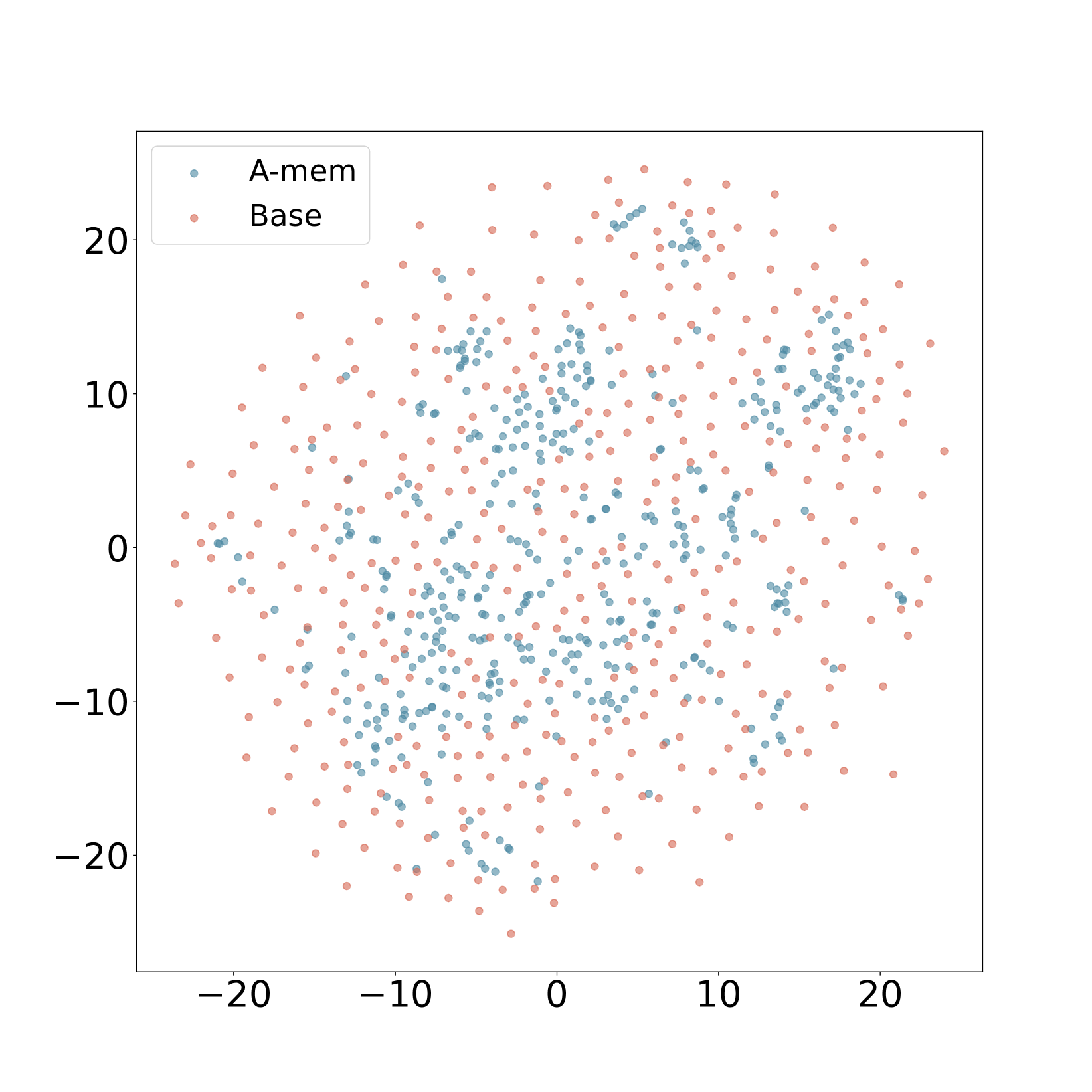
图5:T-SNE可视化——A-Mem的记忆嵌入(橙色)比基线(蓝色)呈现更清晰的聚类结构
这组T-SNE可视化非常直观。A-Mem生成的记忆嵌入形成了明显的聚类模式——语义相关的记忆被组织在一起。而基线方法的记忆分布则更加散乱,缺乏结构。
这验证了A-Mem的核心假设:通过上下文描述生成和记忆进化机制,系统能够捕捉到记忆之间的深层语义关系,而不仅仅是表面的词汇相似性。
参数敏感性分析:Top-k值的影响
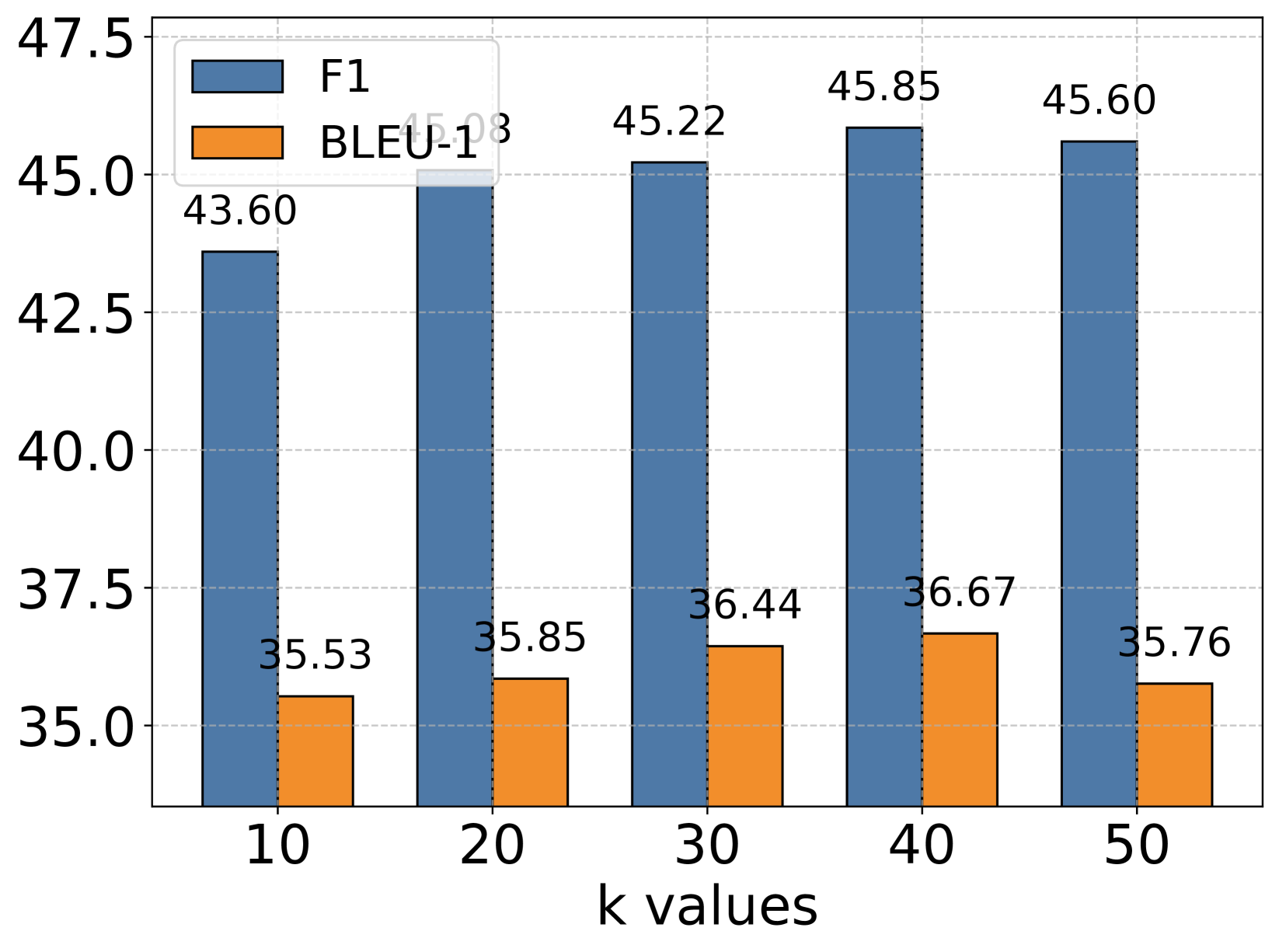
图6:不同基础模型在不同k值下的F1和BLEU-1分数变化
作者还分析了检索数量k对性能的影响。几个有趣的发现:
GPT系列模型:在k=30左右达到最佳性能,之后趋于平稳。说明大模型能够有效利用更多的上下文信息。
小模型(Qwen、Llama):最佳k值通常在10-20之间,k过大反而会导致性能下降。这是因为小模型的上下文处理能力有限,塞入太多记忆反而会”淹没”真正重要的信息。
这个发现对工程实践很有指导意义:不是检索得越多越好,需要根据基础模型的能力选择合适的k值。
与LoCoMo数据集的适配分析
LoCoMo数据集设计了五类不同难度的问题,让我们看看A-Mem在各类问题上的表现差异:
A-Mem在多跳任务上的提升最为明显(1.8倍),这正好验证了链接机制的价值——当答案需要从多个分散的记忆中拼凑时,有机的记忆网络比扁平的记忆列表更有效。
LLM调用的Prompt设计
A-Mem的效果很大程度上取决于提示词的设计。根据论文和开源代码,这里给出几个关键prompt的设计思路:
笔记构建Prompt:
链接分析Prompt:
记忆进化Prompt:
向量数据库的选择
A-Mem需要一个高效的向量存储和检索系统。实际部署时可以选择:
论文中使用的是基于余弦相似度的简单检索,实际生产中可以根据需求选择更复杂的混合检索策略(向量检索 Agent 智能体 + 关键词检索 + 标签过滤)。
1. 从”存储器”到”知识库”的范式转换
A-Mem最打动我的不是某个具体技术,而是它背后的设计理念:记忆系统应该是主动的参与者,而不是被动的存储器。
传统方案把记忆当作数据库——你存什么就是什么,检索什么就返回什么。A-Mem则把记忆当作知识库——存入的信息会被理解、结构化、关联,并随着新信息的加入不断演化。
这种范式转换对于构建真正智能的Agent至关重要。
2. Zettelkasten方法论的成功迁移
用卡片盒笔记法来设计AI记忆系统,这个跨界很有启发性。卢曼的核心洞察是:知识的价值不在于单条信息本身,而在于信息之间的连接。
A-Mem用Link Generation机制实现了”连接”,用Memory Evolution机制实现了”持续精炼”。这两个机制的结合,让AI记忆系统具备了类似人类知识网络的特性。
3. 工程落地的可行性
从工程角度看,A-Mem的实现并不复杂:
- 笔记构建:一次LLM调用
- 链接生成:向量检索 + 一次LLM调用
- 记忆进化:一次LLM调用(可选)
- 检索:向量检索
每次记忆写入大约需要2-3次LLM调用,考虑到记忆写入通常不是高频操作,这个开销是可接受的。而且,论文实验表明即使用7B级别的小模型也能取得不错效果,进一步降低了部署成本。
4. 潜在的局限性
当然,A-Mem也有一些值得注意的问题:
- 对LLM能力的依赖:笔记构建、链接分析、进化决策都依赖LLM的理解能力。如果基础模型在某些领域理解不准,记忆组织也会出问题。
- 记忆膨胀:随着交互增加,记忆数量和链接关系会越来越复杂。如何进行合理的记忆遗忘和压缩,论文没有深入讨论。
- 多模态扩展:当前仅支持文本记忆,图像、音频等多模态信息的处理还有待探索。
- 计算开销:每次记忆写入需要多次LLM调用,在高频写入场景下可能成为瓶颈。
5. 与其他记忆系统的对比
为了更清晰地理解A-Mem的定位,这里整理一个主流记忆系统的对比表:
A-Mem的核心差异化在于:它把记忆当作一个动态演化的知识图谱,而非静态的数据存储。这种设计在需要复杂推理的场景下优势明显,但在简单问答场景下可能”杀鸡用牛刀”。
6. 实际应用建议
基于论文结果和我的理解,给出几个落地建议:
适合使用A-Mem的场景:
- 长期客服对话,需要记住用户历史问题和偏好
- 个人助手,需要理解用户的项目进展和关注点
- 知识密集型任务,需要整合多个来源的信息
不太适合的场景:
- 简单的单轮问答
- 对响应延迟敏感的实时系统(LLM调用有延迟)
- 记忆量极大(>10万条)的场景,链接维护成本高
优化建议:
- 使用异步处理记忆写入,避免阻塞主流程
- 对于高频场景,可以批量处理记忆写入
- 定期清理低价值记忆,控制记忆库规模
- 针对特定领域fine-tune笔记生成能力
如果你对LLM智能体的记忆系统感兴趣,可以关注以下相关工作:
A-Mem展示了一种将人类知识管理方法论迁移到AI系统的有趣尝试。它的核心贡献不在于某个惊艳的技术突破,而在于提出了一种新的思考方式:智能体的记忆系统应该像人类大脑一样,能够自主组织、动态关联、持续进化。
对于正在构建复杂Agent系统的开发者来说,A-Mem提供了一个值得借鉴的架构参考。而对于研究者来说,如何让记忆系统更高效地进化、如何处理多模态记忆、如何实现合理的记忆遗忘,都是值得深挖的方向。
记忆,是智能的基石。让我们期待更多在这个方向上的创新。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/244738.html原文链接:https://javaforall.net


