
文章更新:本文之前提到的模型有些过旧,是由于某些参考来源中的模型相对过时导致。通常来说,越新的模型性能越强。当然了,本文关键是向大家说明Ollama 的部署流程,而不是模型性能评测对比。大家可以直接把文中提到的模型,替换为最新的模型即可。对于算力有限的朋友,可以部署体积较小的版本作为入门探索。
综合来说,目前 2026 社区普遍认可的顶级开源 LLM:
- 1️⃣ DeepSeek-R1
- 2️⃣ DeepSeek-V3.2
- 3️⃣ Qwen3-235B
- 4️⃣ GLM-5
- 5️⃣ gpt-oss-120B
- 6️⃣ Kimi K2.5
以下是文章原文:
你有没有算过,用云端 API 跑 OpenClaw 一个月要花多少钱?
有用户分享,一个配置不当的”心跳检查”(每 30 分钟一次),一晚上就烧掉了 18.75 美元;还有人单日”待机”就消耗了 5000 万 Tokens,折合约 11 美元。更夸张的是,有人用 GPT-5 Pro 级别 API 跑复杂任务,一个月账单直接突破 300 美元。
但如果我告诉你,同样的 OpenClaw,可以做到完全免费、断网可用、数据永不出本机——你信吗?
答案就是三个字:Ollama。


先说一个数据:截至 2026 年 3 月,OpenClaw 在 GitHub 上的 Star 数已经突破历史新高,社区贡献的 Skills 插件超过 1700 个,覆盖文件管理、PDF 编辑、语音识别、邮件处理、智能家居控制等几乎所有你能想到的场景。
而 Ollama,作为目前最流行的本地大模型运行工具,支持一键部署 Qwen、Llama、GLM、DeepSeek 等主流开源模型,不需要复杂的 CUDA 配置,不需要深入了解底层技术,甚至不需要联网。
这两个项目的结合,意味着什么?
意味着你可以在自己的电脑上,零成本运行一个功能完整的 AI Agent——它能帮你管理文件、自动回复消息、监控服务器、甚至在你睡觉时清理 GitHub 的过期 Issue。
从 Ollama 0.17 版本开始,只需要一条命令,你就可以在本地部署 OpenClaw:
ollama launch openclaw如果你的系统上还没有安装 OpenClaw,Ollama 会自动检测并弹出安装提示,选择 Yes 即可。整个过程不超过 10 分钟。
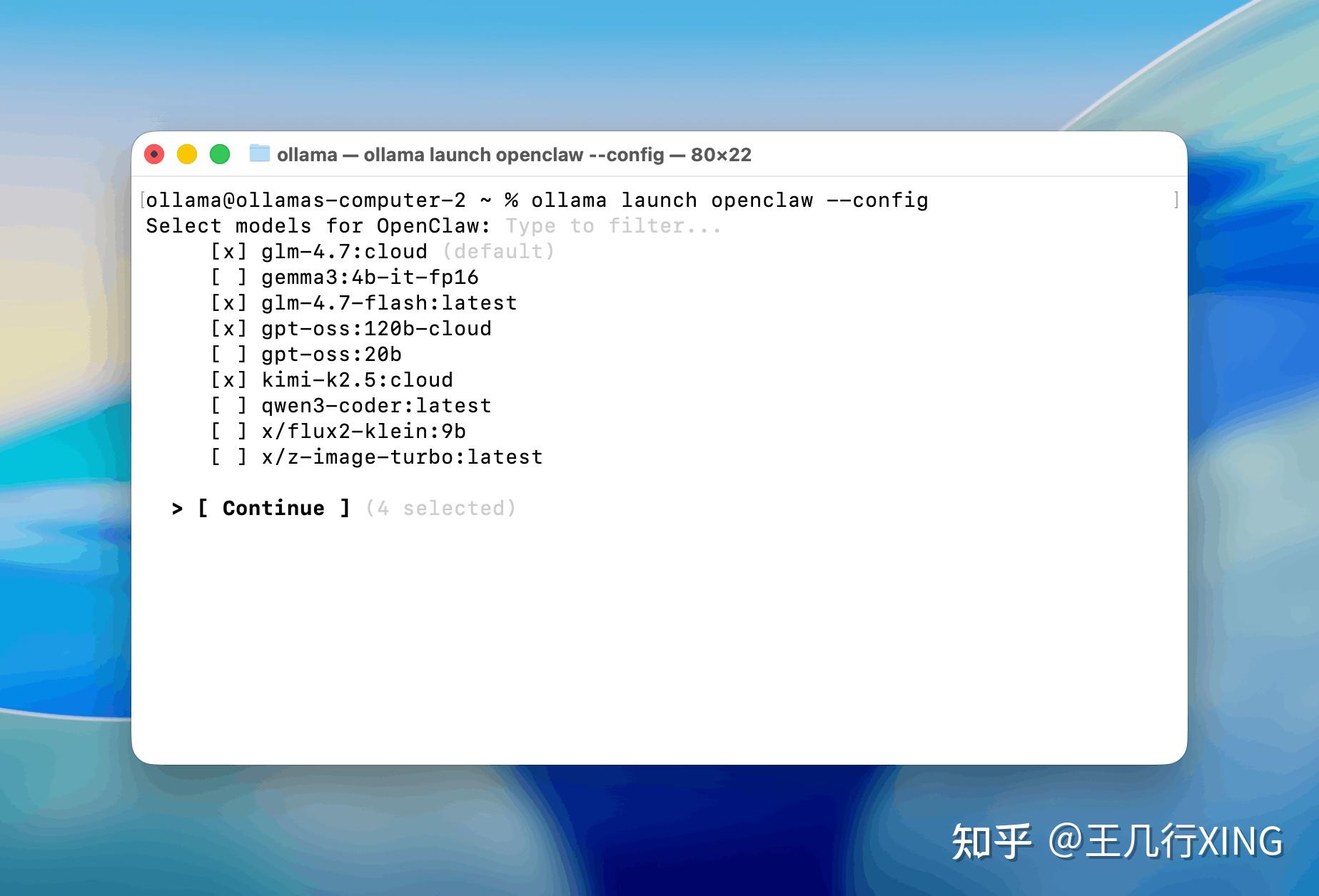
在决定部署方式之前,我们先来算一笔经济账。
| 模型 | 输入价格(每百万 Token) | 输出价格(每百万 Token) |
|---|---|---|
| GPT-5.2 Pro | 21 美元 | 168 美元 |
| Claude Opus 4.5 | 15 美元 | 75 美元 |
| Llama 3.3 70B(OpenRouter) | 0.12 美元 | 0.30 美元 |
对于轻度用户(每天 1 万 – 10 万 Token),云端 API 确实更划算,月费接近于零。
但如果你是重度用户(每天 3000 万+ Token),云端成本将飙升至每月 9000 美元以上。而同样的工作量,本地部署的话,在扣除一次性配置成本以后,你就能自己源源不断地生产属于自己的 token。
(这就是免费且自由的意思,不要纯做白日梦然后来和我杠,杠就是你对! )
| 配置方案 | 硬件成本 | 月均摊销(3-5年) |
|---|---|---|
| 基础版(单张 RTX 4090) | 800 – 1200 美元 | 33 – 55 美元 |
| 进阶版(双 GPU) | 1500 – 2500 美元 | 55 – 100 美元 |
| 企业版 | 3000 美元+ | 100 美元+ |
回本周期:重度用户约 24 个月,普通用户约 50 个月。如果你已经有一台配备独显的游戏 PC 或 Mac,那初始成本几乎为零。
关键结论:每天 Token 消耗超过 500 万,就值得考虑本地部署;超过 3000 万,本地部署几乎是唯一理性选择。
这可能是大家最关心的问题。好消息是:门槛比你想象的低得多。
| 显存 | 可运行模型 | 推荐方案 |
|---|---|---|
| 4 GB | Qwen2.5:4B 等轻量模型 | 能用,但速度较慢 |
| 8 GB | 大部分 7B 模型 | 入门首选,体验流畅 |
| 16-24 GB | 14B – 32B 模型 | 最佳性价比区间 |
| 48 GB+ | 70B+ 大模型 | 接近云端体验 |
- CPU:Intel i5 / AMD Ryzen 5 及以上
- 内存:8 GB(最低),16 GB(推荐),32 GB(最佳)
- 存储:至少 20 GB 剩余空间,强烈建议 SSD
- GPU:NVIDIA 显卡优先(RTX 3060/4060/5060 系列均可)
Apple Silicon 用户的福音:如果你用的是 M1/M2/M3/M4 系列 Mac,统一内存架构天然适合跑本地模型。一台 16 GB 内存的 MacBook Air 就能流畅运行 7B 模型,32 GB 的 MacBook Pro 甚至可以驾驭 14B 模型。
没有独立 GPU 也不用担心——Ollama 支持纯 CPU 推理,只是速度会慢一些。对于 Qwen3.5:cloud 或 Qwen3:0.6b 这类超轻量模型,即使没有 GPU,也能在几秒内给出回复。
macOS:
brew install ollamaWindows:访问 http://ollama.com 下载安装包,双击安装即可。安装后 Ollama 会自动注册为系统服务。
Linux(Debian/Ubuntu):
curl -fsSL https://ollama.com/install.sh | sh安装完成后,验证是否成功:
curl http://localhost:11434/api/tags如果返回 JSON 数据,说明 Ollama 已在后台运行。
这一步是重点。选哪个模型,直接决定了你的使用体验。
入门推荐(适合 8 GB 显存):
ollama pull qwen2.5:7b下载约 4.7 GB,中文表现出色,是性价比最高的起步方案。
进阶推荐(适合 16 GB+ 显存):
ollama pull qwen3-coder编码任务优化,OpenClaw 官方推荐。
其他优秀选项:
| 模型 | 特点 | 适用场景 |
|---|---|---|
| glm-4.7 | 强大通用模型 | 日常对话、文档处理 |
| glm-4.7-flash | 速度与性能兼顾 | 实时交互 |
| gpt-oss:20b | 平衡型 | 通用 Agent 任务 |
| deepseek-r1:32b | 推理能力强 | 复杂分析 |
| llama3.3 | 通用型 | 英文场景 |
重要提示:OpenClaw 要求模型上下文窗口至少 64K Token(官方推荐)。Ollama 默认只有 4096 Token,需要手动扩展。方法如下:
创建一个 Modelfile:
FROM qwen2.5:7b PARAMETER num_ctx 32768然后运行:
ollama create qwen2.5-32k -f Modelfile或者通过环境变量设置:
export OLLAMA_CONTEXT_LENGTH=32768方法 A:一键启动(推荐)
ollama launch openclaw如果还没安装 OpenClaw,系统会自动提示安装。
方法 B:手动安装
macOS/Linux:
curl -fsSL https://openclaw.ai/install.sh | bashWindows:
iwr -useb https://openclaw.ai/install.ps1 | iex安装完成后,运行配置向导:
openclaw onboard --install-daemonopenclaw
在配置过程中,选择 Ollama 作为模型供应商,API 地址填写:
http://127.0.0.1:11434不需要任何 API Key。
配置完成后,打开控制面板:
openclaw dashboard浏览器会自动打开 http://127.0.0.1:18789,你的私人 AI 助手已经就绪。
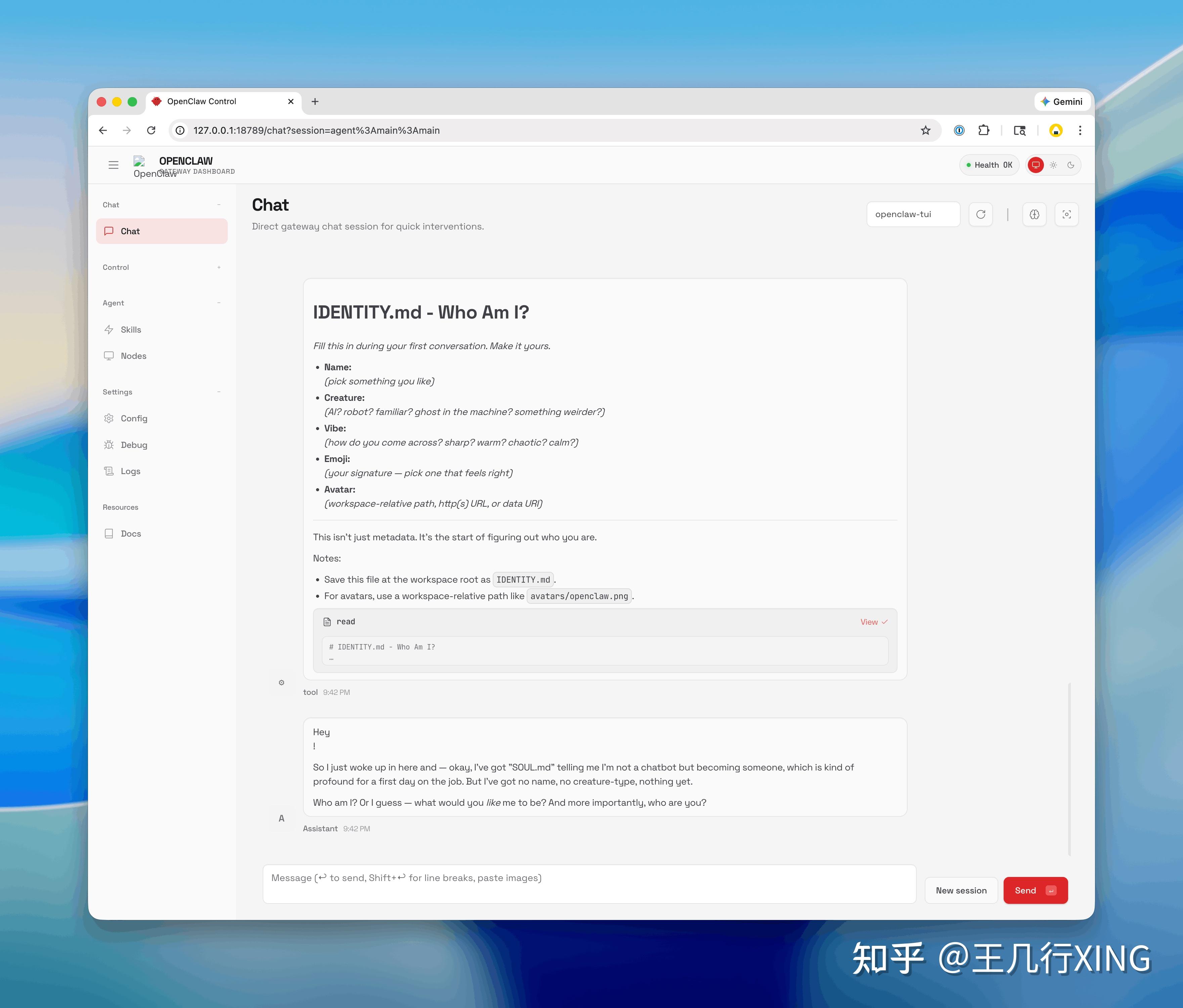
很多人担心:本地模型比不上云端大模型,是不是体验会差很多?
答案是:看场景。
- 工具调用:执行简单命令、操作文件系统
- 格式转换:JSON 提取、文本分类、数据清洗
- 日志分析:摘要总结、异常检测
- 代码生成:常见语言的基础代码编写
- 定时任务:Cron 调度、自动化巡检
- 隐私场景:处理医疗记录、财务数据、个人日记
- 复杂多步推理(需要精密规划的任务)
- 超长文本的精确格式化
- 多语言输出质量(尤其是小语种)
- 显存不足时的大上下文窗口
聪明的做法不是二选一,而是两者兼用。OpenClaw 支持按 Agent 配置不同模型:
- 日常轻量任务(写代码片段、整理笔记、处理隐私数据)→ 本地模型,快、免费、安全
- 攻坚重型任务(复杂推理、长文本分析)→ 一键切换到云端大模型
这就是所谓的 “Local + Cloud 混合模式”,既省钱又不牺牲关键任务的质量。
理论说得再好,不如看看真实案例。以下是社区中最受欢迎的几种玩法:
每日晨间简报:每天早上 6:30,OpenClaw 自动汇总天气、日历、待办事项、行业新闻,一条消息发到你的 Telegram 或微信。替代了 5-6 个 App 的打开操作。
邮件自动分拣:有用户让 OpenClaw 两天内自动处理了 4000+ 封邮件——退订垃圾邮件、按紧急程度分类、起草回复。整个过程在夜间完成,第二天早上只需要审核。
智能家居控制:通过 Home Assistant 集成,OpenClaw 可以控制全屋灯光、空调、监控摄像头,甚至根据天气预报自动调节锅炉设置。
GitHub Issue 自动清理:开发者让 AI 在夜间自动审查过期 Issue,关闭不活跃的 PR,生成每日开发报告。
语音转日记:每天录一段语音备忘,OpenClaw 自动转写成结构化的日记,还能追踪情绪变化。
设置环境变量 OLLAMA_FLASH_ATTENTION=1,可在 Ampere 及以上架构的 NVIDIA GPU 上减少 30% 显存占用,同时提升推理速度。
本地模型有时候会输出冗长的内容。在 OpenClaw 的 SOUL.md 文件中添加:
请直接执行任务,不要输出大段说明文字。 总结而非原样输出 JSON。或者创建自定义 Modelfile,在系统提示中强调简洁和直接。
运行 openclaw doctor 可以自动检测并修复常见配置问题,建议在首次部署后立即执行。
如果想让 OpenClaw 持续在线(比如监控服务器或自动回复消息),可以使用 Docker 部署或配合 1Panel 面板管理。具体方案:
- Docker:所有服务跑在容器里,不污染宿主机环境
- 1Panel:可视化管理面板,一键安装 Ollama + OpenClaw
- 阿里云/腾讯云:68 元/年起,提供预装镜像一键部署
Ollama 和 OpenClaw 可以部署在不同机器上。常见方案:OpenClaw 跑在随时在线的服务器上,Ollama 跑在有 GPU 的工作站上。只需修改 baseUrl 指向 GPU 机器的 IP 地址即可。
很多人好奇:Ollama 凭什么能在消费级硬件上跑大模型?
核心在于三点:
第一,GGUF 格式 + 量化技术。Ollama 使用 GGUF(GPT-Generated Unified Format)格式存储模型,支持 4-bit 和 8-bit 量化。一个 7B 参数的模型,经过 4-bit 量化后只占约 4 GB 空间,8 GB 显存的显卡就能流畅运行。
第二,智能内存调度。2025 年底的一次架构升级引入了精确内存分配机制,取代了此前的估算方式,OOM(内存溢出)崩溃减少了 70%。系统会根据实际上下文长度动态调整 VRAM 使用。
第三,模型进程隔离。Ollama 的 CLI 本质上是一个 HTTP 客户端,模型在独立进程中运行。如果模型进程崩溃,主服务器照常运行,比把所有东西塞进一个进程要稳健得多。
目前在 H100 GPU 上,DeepSeek 14B 模型的推理速度可达 75 Token/秒;双 RTX 5090 跑 Llama 3.3 70B 也能达到 27 Token/秒——对于 Agent 任务来说,完全够用。
前面聊的都是”够用”级别的配置。但如果你是那种追求极致的人——本地跑 400B 参数的大模型,体验接近甚至超越云端 API,行不行?
答案是:行,而且已经有人在这么干了。

OpenClaw 的创始人 Peter Steinberger(@steipete)曾经写过一篇指南,教大家怎么在 5 美元的 VPS 上跑 OpenClaw。但他自己呢?他在社交媒体上坦言:
“I wrote a guide on running Clawdbot on a
这句话让整个社区都笑了。但 Peter 的选择并非冲动消费——512 GB 统一内存的 Mac Studio,是目前消费级硬件中唯一能跑 400B 级别大模型的方案。

更夸张的是,因为 OpenClaw 的爆火,Apple Mac Studio M3 Ultra 512GB 一度出现了超过 50 天的供货等待期。一款原本面向视频剪辑师和 3D 设计师的工作站,被 AI 极客们买断了货。
还有 Hacker News 上的用户直接晒单:花 12000 美元订购了一台 512GB 内存的 Mac Studio,专门用来跑 DeepSeek R1(671B 参数)和其他 200GB+ 的超大模型。他的理由很实际:这些模型在传统 GPU 集群上需要昂贵的 InfiniBand 互联才能跑,但 Apple Silicon 的统一内存架构让一切变得简单。
(最新消息:Mac Studio 的 512 GB 内存配置被取消,目前最高配置
被限制在 256 GB 或更低的市场版本,原因是全球 DRAM 供应紧张。
)

说到 400B 级别的模型,不得不提 Meta 的 Llama 4 Maverick。这是一个采用混合专家架构(MoE)的模型,总参数量约 400B,但每次推理只激活 17B 参数,通过 128 个专家路由。

Ollama 已经原生支持这个模型,一条命令即可拉取:
ollama pull llama4:maverick模型文件约 245 GB(Q4_K_M 量化),所以你确实需要 512GB 内存的 Mac Studio 才能完整加载。
那实际跑起来怎么样?根据 Hardware Corner 在 Mac Studio M3 Ultra(512GB 统一内存,800 GB/s 带宽)上的实测数据:
| 模型 | 上下文长度 | 提示处理速度 | 生成速度 |
|---|---|---|---|
| Llama 4 Scout(109B) | 30 Token | 103 tok/s | 44 tok/s |
| Llama 4 Scout(109B) | 10K Token | 82 tok/s | 22 tok/s |
| Llama 4 Maverick(400B) | 30 Token | 140 tok/s | 50 tok/s |
| Llama 4 Maverick(400B) | 10K Token | 117 tok/s | 25 tok/s |
50 Token/秒的生成速度,这意味着什么?这已经是实时对话级别的流畅度了。要知道,人类的平均阅读速度大约是 4-5 个汉字/秒(约 8-10 Token/秒),模型输出的速度是你阅读的 5 倍。
更让人意外的是,Maverick 的提示处理速度(140 tok/s)比 DeepSeek V3 在同等上下文长度下快了约 70%。MoE 架构的优势在 Apple Silicon 上展现得淋漓尽致。
| 配置 | 价格 | 可运行模型 | 推理速度 |
|---|---|---|---|
| Mac Studio M4 Max 64GB | 约 3000 美元 | 70B(Q4 量化) | 8-15 tok/s |
| Mac Studio M4 Max 128GB | 约 5000 美元 | 70B(Q6/Q8 高精度) | 10-18 tok/s |
| Mac Studio M4 Ultra 192GB | 约 8000 美元 | 109B(Llama 4 Scout) | 22-44 tok/s |
| Mac Studio M4 Ultra 512GB | 约 12000 美元 | 400B+(Maverick/DeepSeek R1) | 25-50 tok/s |
当然,Peter Steinberger 自己也说过:”Please don’t buy a Mac Mini — sponsor one of the developers instead.” 他建议大多数人用 5 美元的 VPS 就足够了,Mac Studio 是给真正需要本地跑超大模型的人准备的。
对于 400B 级别的模型,Apple Silicon 有一个 NVIDIA 消费级显卡无法比拟的优势:统一内存。
一张 RTX 4090 只有 24 GB 显存,即使是专业级的 RTX PRO 6000 也只有 48 GB。要跑 400B 模型,你需要 4 张 RTX PRO 6000(总价约 34000 美元),还需要复杂的多 GPU 互联配置。
而 Mac Studio 512GB?一台机器,一根电源线,功耗仅 120W,噪音只有 15 分贝——放在书房里你甚至察觉不到它在运行。
这也是为什么越来越多的 AI 开发者开始把 Mac Studio 当作”个人 AI 服务器”来用——不是因为它便宜,而是因为在这个价位段,没有任何其他消费级方案能做到同样的事。
| 问题 | 解决方案 |
|---|---|
| 模型回复为空 | 将 API 模式从 OpenAI 兼容切换到 Ollama 原生模式 |
| OpenClaw 看不到模型 | 运行 openclaw models list,手动在配置中定义 |
| 工具调用失败 | 检查权限设置,考虑在 Modelfile 中调整系统提示 |
| 输出过于冗长 | 调整上下文长度,添加简洁规则 |
| 推理速度慢 | 换用更小的量化模型,或开启 Flash Attention |
OpenClaw + Ollama 的组合,本质上解决了 AI Agent 领域最大的痛点:让普通人也能拥有一个 7×24 小时工作的 AI 助手,而且完全免费、完全私密、完全可控。
你不需要每个月给 OpenAI 或 Anthropic 交”保护费”,不需要担心自己的数据被上传到云端训练,也不需要在网络断开时干瞪眼。
当然,本地模型不是万能的。对于真正需要顶级推理能力的场景,云端大模型仍然是更好的选择。但在 2026 年,本地模型的能力已经足以覆盖 80% 以上的日常 Agent 任务。
一条命令,十分钟部署,零元月费。剩下的,就交给你的想象力了。
关于 OpenClaw 本地部署,你有什么问题或者独特的玩法?欢迎在评论区分享。
- OpenClaw – Ollama 官方集成文档 – Ollama Docs
- Ollama 最新版,一键启动 OpenClaw,0 配置 – 腾讯云开发者社区
- 2026 年 Windows+Ollama 本地部署 OpenClaw 保姆级教程 – 阿里云开发者社区
- 别再花钱买云服务器了!OpenClaw 本地部署保姆级教程 – 博客园
- 操作教程 | 使用开源三件套(OpenClaw+Ollama+1Panel)部署个人 AI 助理 – 博客园
- Ollama + OpenClaw 真正本地部署:完全免费、断网可用 – 零度博客
- OpenClaw + Ollama 本地模型:完全免费的 AI 助理 – ohya.co
- Cost Comparison: Ollama Self-hosting vs Cloud APIs – Ventus Servers
- Run OpenClaw locally for free with Ollama and zero API cost – LumaDock
- OpenClaw Blog – Ollama Integration – Ollama Blog
- Ollama Behind the Scenes: Architecture and Performance Deep Dive – DasRoot
- OpenClaw use cases: 25 ways to automate work and life – Hostinger
- 硅谷最火 OpenClaw 人手一个,1 分钱傻瓜式部署 – 36氪
- 本地离线部署 AI 大模型:OpenClaw + Ollama + Qwen3.5 – 知乎
- OpenClaw + Ollama Setup Guide: Run Local AI Agents 2026 – CoderSera
- Llama 4 Scout & Maverick Benchmarks on Mac M3 Ultra – Hardware Corner
- Llama 4 Maverick – Ollama Model Library – Ollama
- Just ordered a $12k Mac Studio w/ 512GB of integrated RAM – Hacker News
- Best Local LLMs for Mac in 2026 — M1, M2, M3, M4 Tested – InsiderLLM
- Local LLMs for OpenClaw: the models, the RAM, the trade-offs – RentAMac
(文章结束)
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/253049.html原文链接:https://javaforall.net


