
阿里千问团队昨晚发布了20B的MMDiT架构的图像生成模型Qwen-Image,这是通义千问系列中首个图像生成基础模型,可以支持文生图和通用图像编辑,当前文生图模型以及技术报告已经开源:
- 模型:https://huggingface.co/Qwen/Qwen-Image
- 技术报告:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/Qwen_Image.pdf


Qwen-Image 的一大亮点是文本渲染的能力。无论是英文字母语言,还是中文等表意文字,它都能准确保留字体细节、排版结构和语境一致性。文本不再是简单叠加在图像上的内容,而是与图像视觉元素无缝融合。

除了文本能力,Qwen-Image 在通用图像生成方面同样表现出色,支持多种艺术风格。从写实场景到印象派画作,从动漫风格到极简设计,它都能灵活响应创意提示,是艺术家、设计师和叙事创作者的多功能利器。

在图像编辑方面,Qwen-Image 支持通用编辑能力,如风格迁移、物体插入或移除、细节增强、图像中的文字编辑,甚至是人物姿态的调整。

除此之外, Qwen-Image 还支持物体检测、语义分割、深度与边缘(Canny)估计、新视角合成和超分辨率等任务。

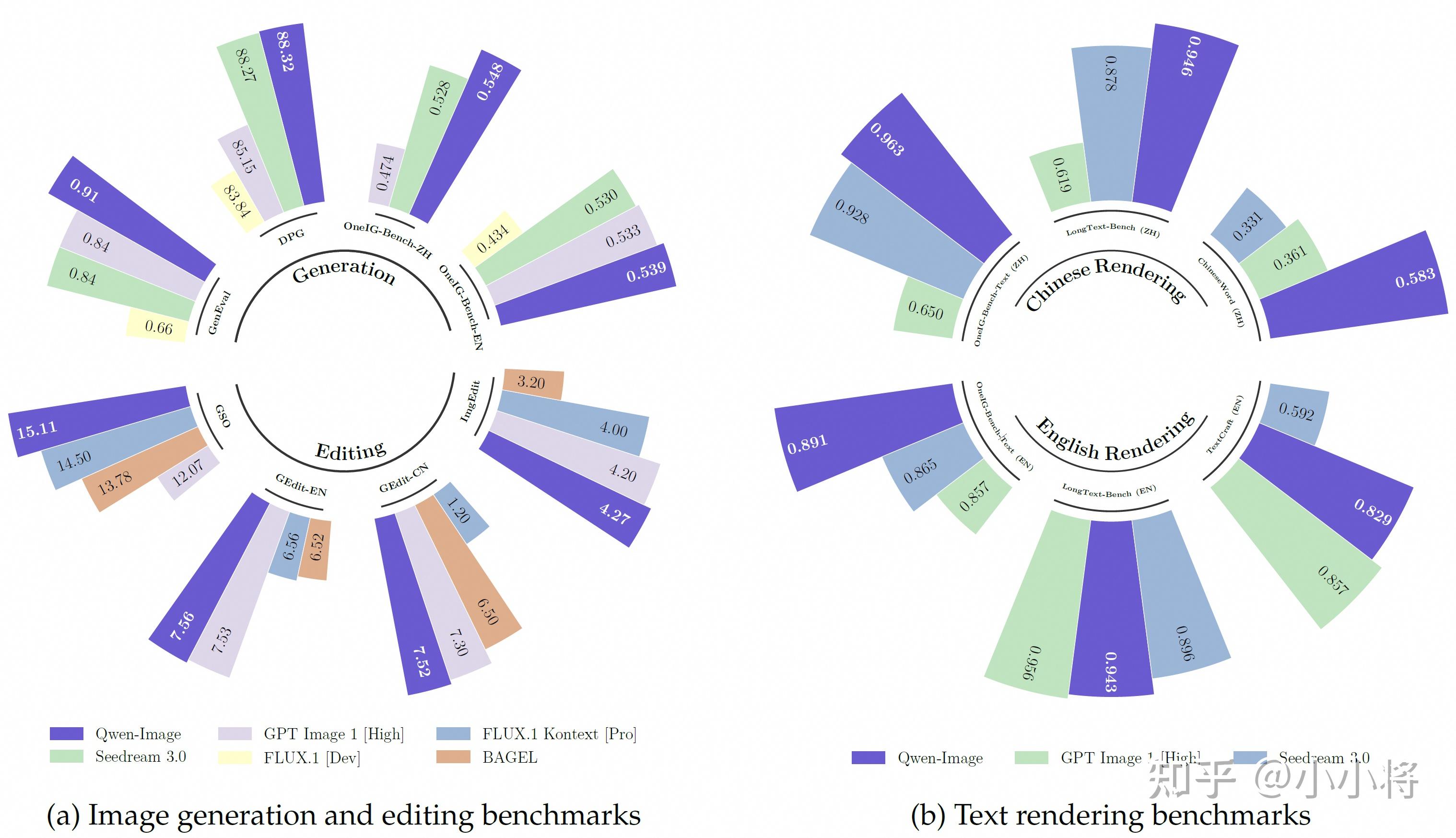
Qwen-Image 在多个公开基准测试中均取得SOTA。其在通用图像生成任务中的表现优于现有模型,涵盖 GenEval(0.91)、DPG(88.34) 和 OneIG-Bench 等主流基准;在图像编辑领域,如 GEdit、ImgEdit 和 GSO 等测试中也取得最先进性能。同时,Qwen-Image 在文本渲染方面表现尤为出色,尤其在 LongText-Bench、ChineseWord 及 TextCraft 等评估中,在中英文场景下均实现高保真渲染,显著优于现有同类模型。
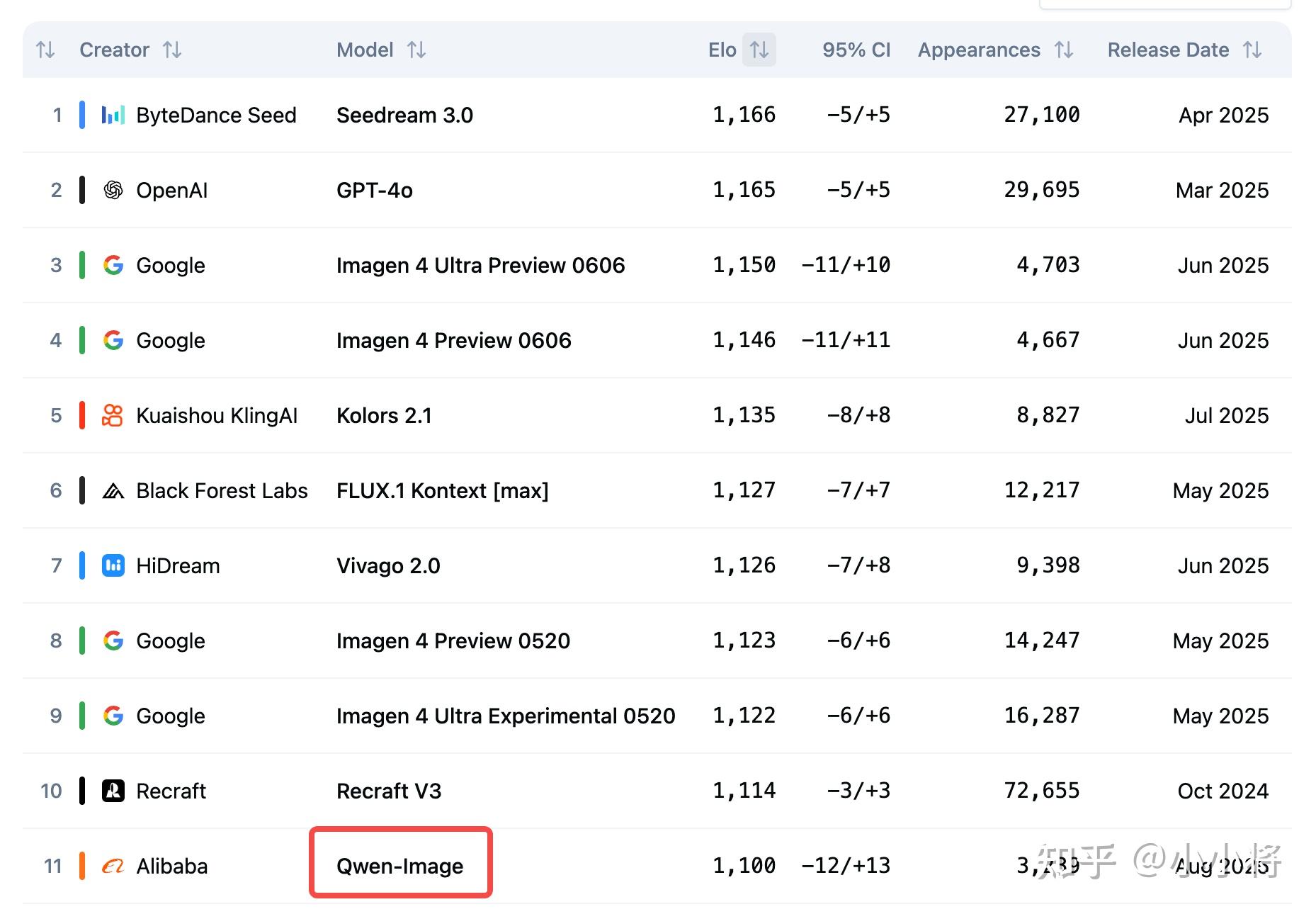
当前在Artificial Analysis Image Arena排行榜上,Qwen-Image排名第11,不过Elo已经达到1100,是目前排名第一的开源模型。
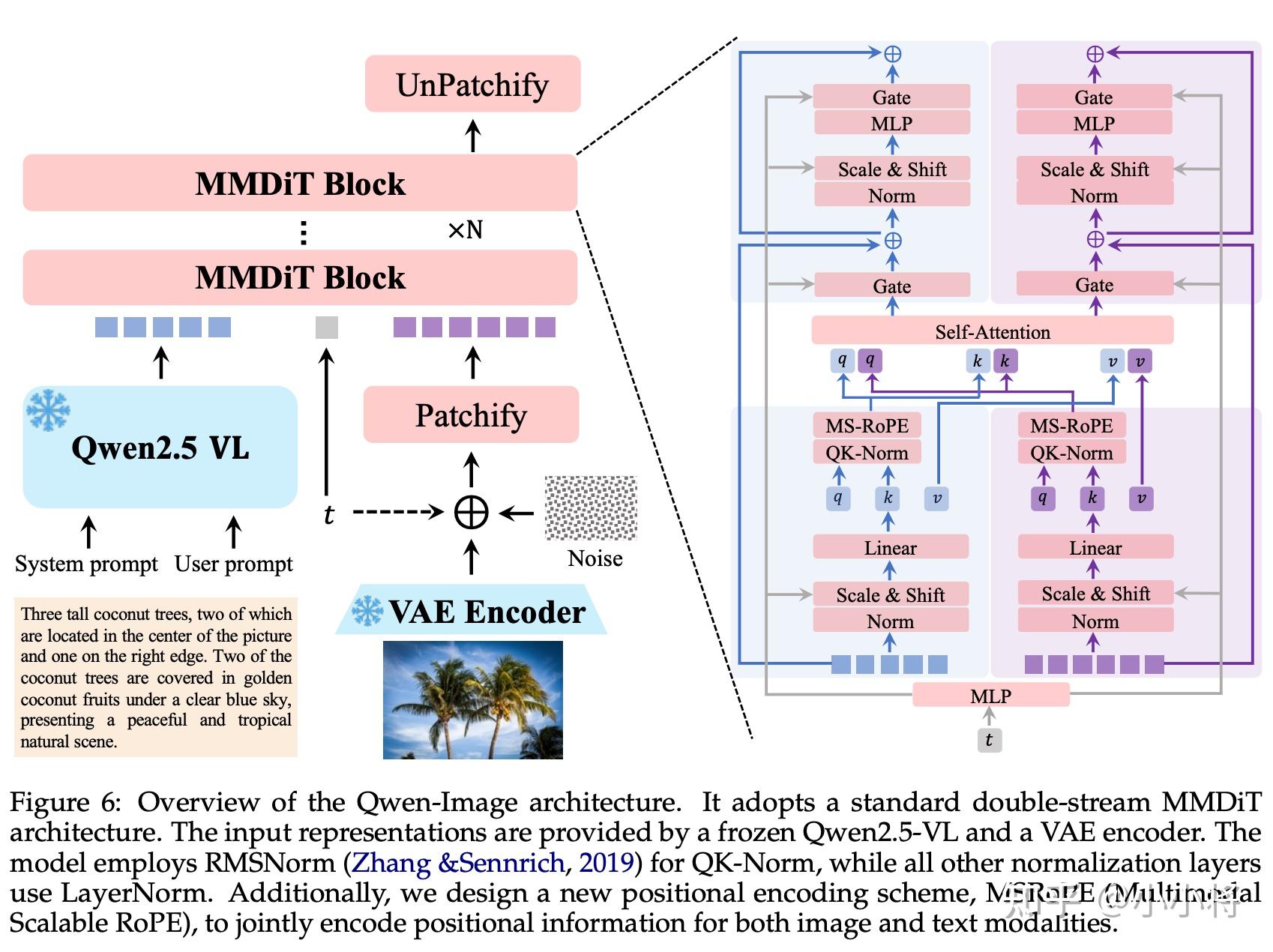
下面简单介绍一下Qwen-Image的模型设计以及训练流程。Qwen-Image的模型架构如下所示:
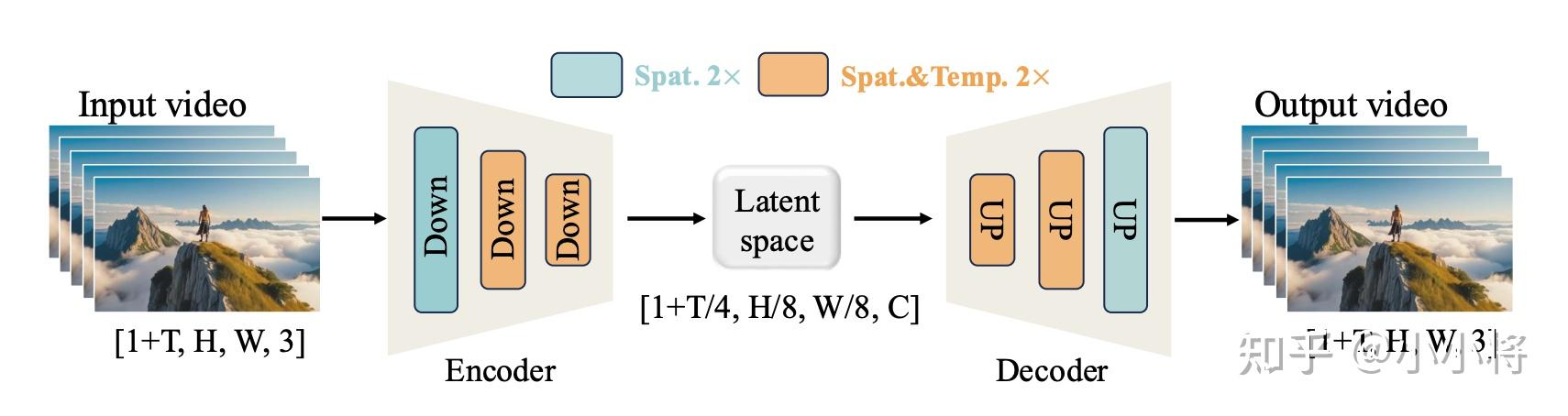
VAE是采用同时支持编码图像和视频的3D VAE,以在未来支持视频。这里的3D VAE复用Wan 2.1 VAE,模型大小为127M,空间下采样8x,时序下采样4x,latent特征维度为16,比如对于输入为1024×1024的图像,VAE编码的latent特征维度16x128x128。另外,为了提升VAE的重建精度,尤其是针对小字体文本和细粒度细节的还原能力,这里还基于内部构建的富含文本的图像数据集上对VAE decoder进行了微调,这里仅组合使用重建损失和感知损失。
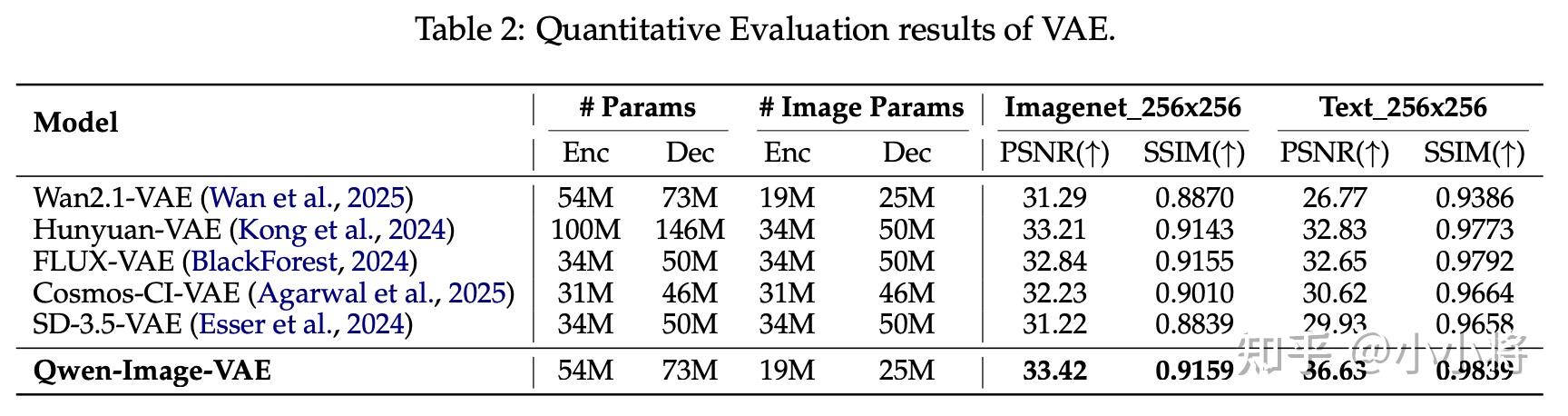
Qwen-Image的VAE在重建效果上优于Flux的VAE,特别是文字重建方面:

text encoder采用Qwen2.5-VL(提取模型最后一层的隐含层特征),具体来说是Qwen2.5-VL-7B。Qwen2.5-VL 的语言与视觉空间已经对齐,而且保留了纯语言模型的语言建模能力,相较于仅语言模型更适用于文生图任务,而且Qwen2.5-VL 支持多模态输入,使得 Qwen-Image 能够更好地支持图像编辑这样的任务。这里还针对纯文本输入和图文混合输入分别设计了不同的系统提示词,对于文生图任务,其系统提示词如下所示:

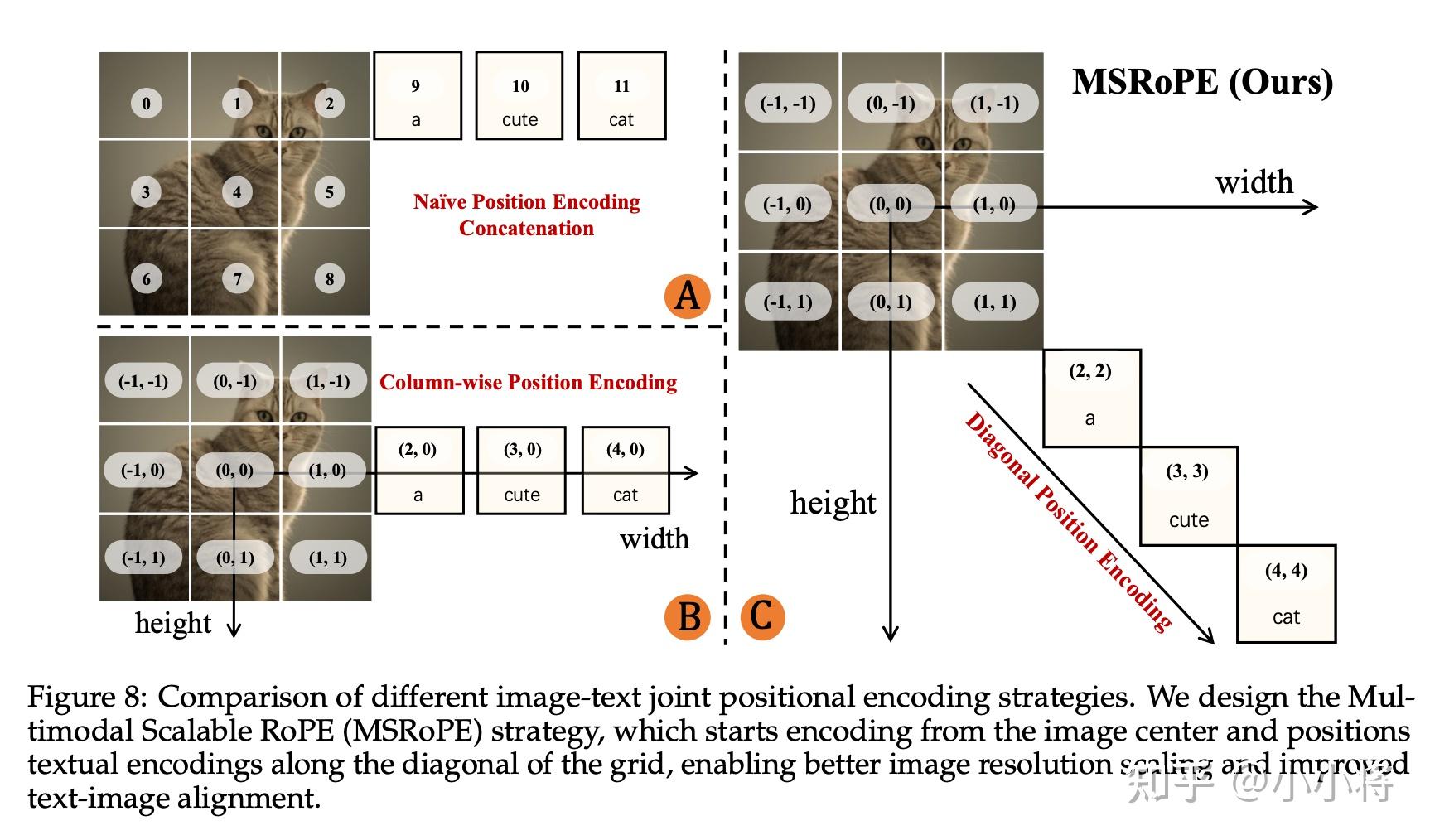
扩散模型是一个20B的MMDiT,采用Flow Matching,patch size为2×2。但是这里的模型架构设计和SD3类似,transformer只包含60层的MMDiT block(文本和图像采用不同的参数),而不像Flux那样还包含单流的DiT Block(文本和图像共享参数)。Qwen-Image的MMDiT一个独特设计是位置编码,这里引入了一种新的位置编码方法:多模态可扩展旋转位置编码(Multimodal Scalable RoPE,简称 MSRoPE)。在传统的 MMDiT 模块中,文本 token 被直接拼接在展平后的图像位置嵌入之后(下图A)。而 字节的Seedream 3.0则引入了 缩放 RoPE(Scaling RoPE),将图像的位置编码向图像中心区域偏移,同时将文本 token 视为具有 [1, L] 形状的二维 token,并使用 2D RoPE 进行图文联合位置编码(下图B)。尽管这种调整有助于支持不同分辨率的训练,但在下图B中所示的某些行(例如第 0 行的中间部分),文本和图像的位置编码会变得同构,导致模型难以区分文本 token 与图像 latent token。这里提出的MSRoPE将文本输入看作是二维张量,在两个维度上都使用相同的位置 ID。如下图C所示,文本是沿图像的对角线拼接的。这种设计使得 MSRoPE 能够在图像端利用分辨率缩放的优势;而且在文本端保持与一维 RoPE 等效的行为,从而无需再为文本设计复杂的位置编码策略。
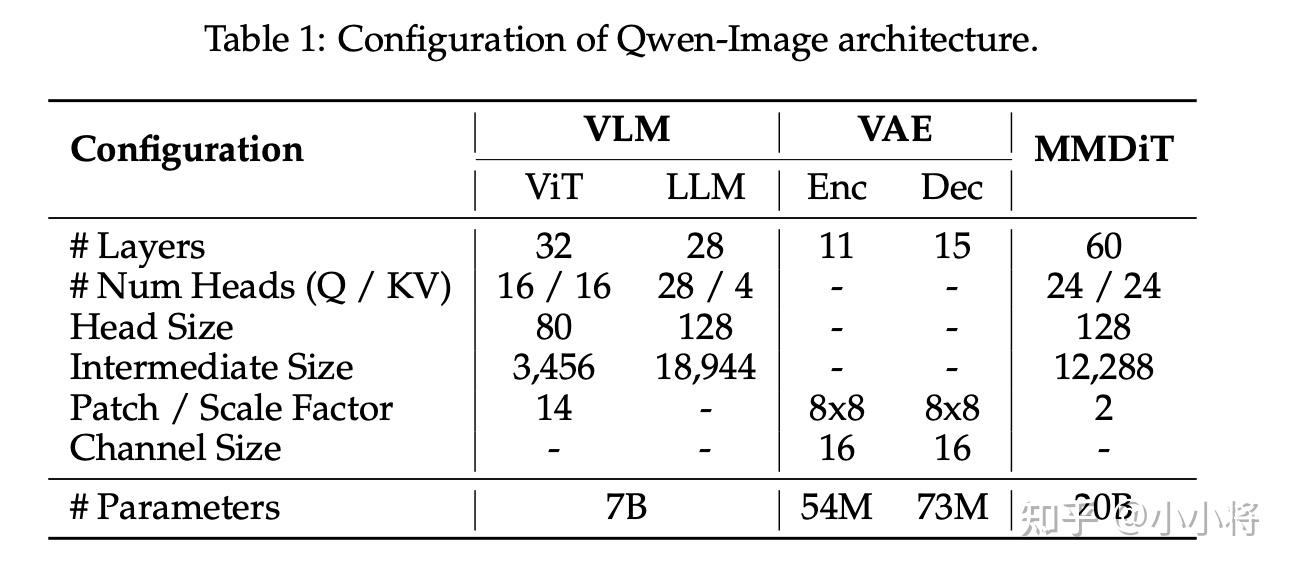
Qwen-Image的模型的详细参数配置如下表所示:
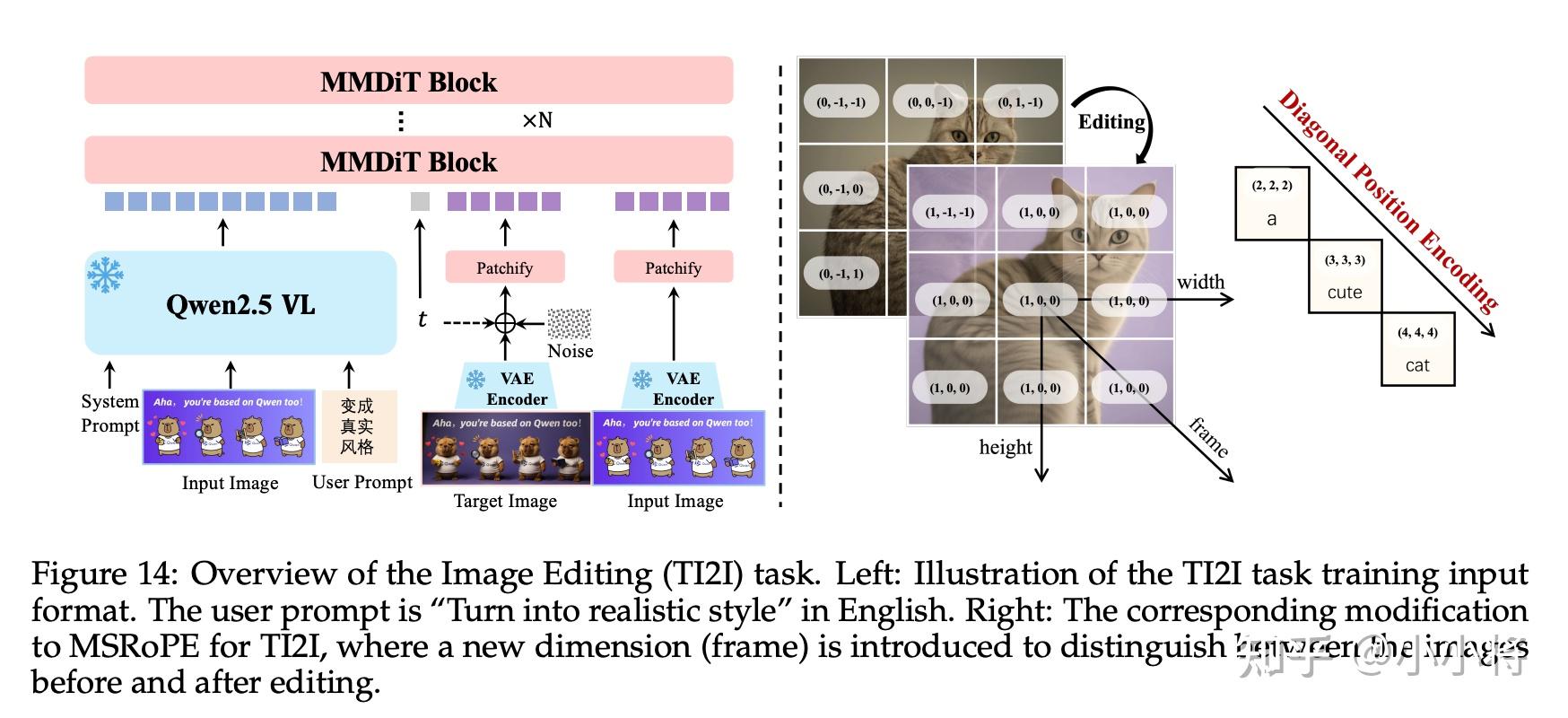
除了文本生成图像任务外,这里还将基础模型扩展到了通用图像编辑任务,包括:基于指令的图像编辑、新视角合成、以及如深度估计等计算机视觉任务。这里一方面用VAE来编码输入的图像得到图像tokens,并将图像tokens和noisy tokens进行拼接;另外一方面用Qwen2.5-VL 的ViT提取视觉 patch,随后这些 patch 会与文本 token 一同拼接,组成输入序列。VAE 编码的图像 latent 有助于保持人物和场景的一致性,而Qwen2.5-VL提取的视觉特征有助于增强语义。为了使模型能够区分多张图像,在 MSRoPE中新增了一个帧(frame)维度,在原有的高度和宽度维度之外,用于标识不同图像中的图像 patch。
对于图像编辑任务,Qwen2.5-VL 采用不同的系统提示词:

Qwen-Image的训练数据规模是十亿级图文对,包含自然类(Nature)、设计类(Design)、人物类(People)以及合成类数据(Synthetic Data):
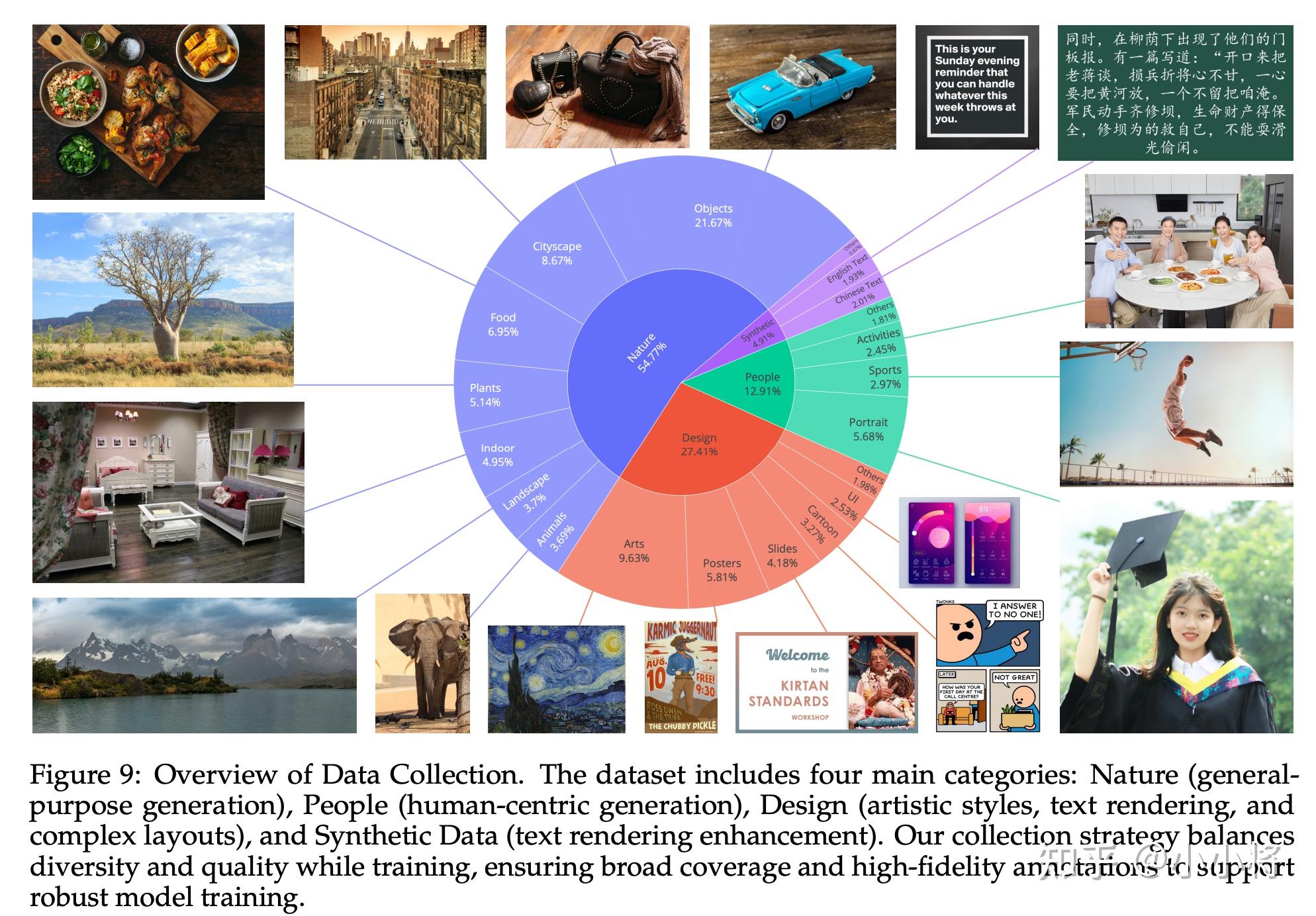
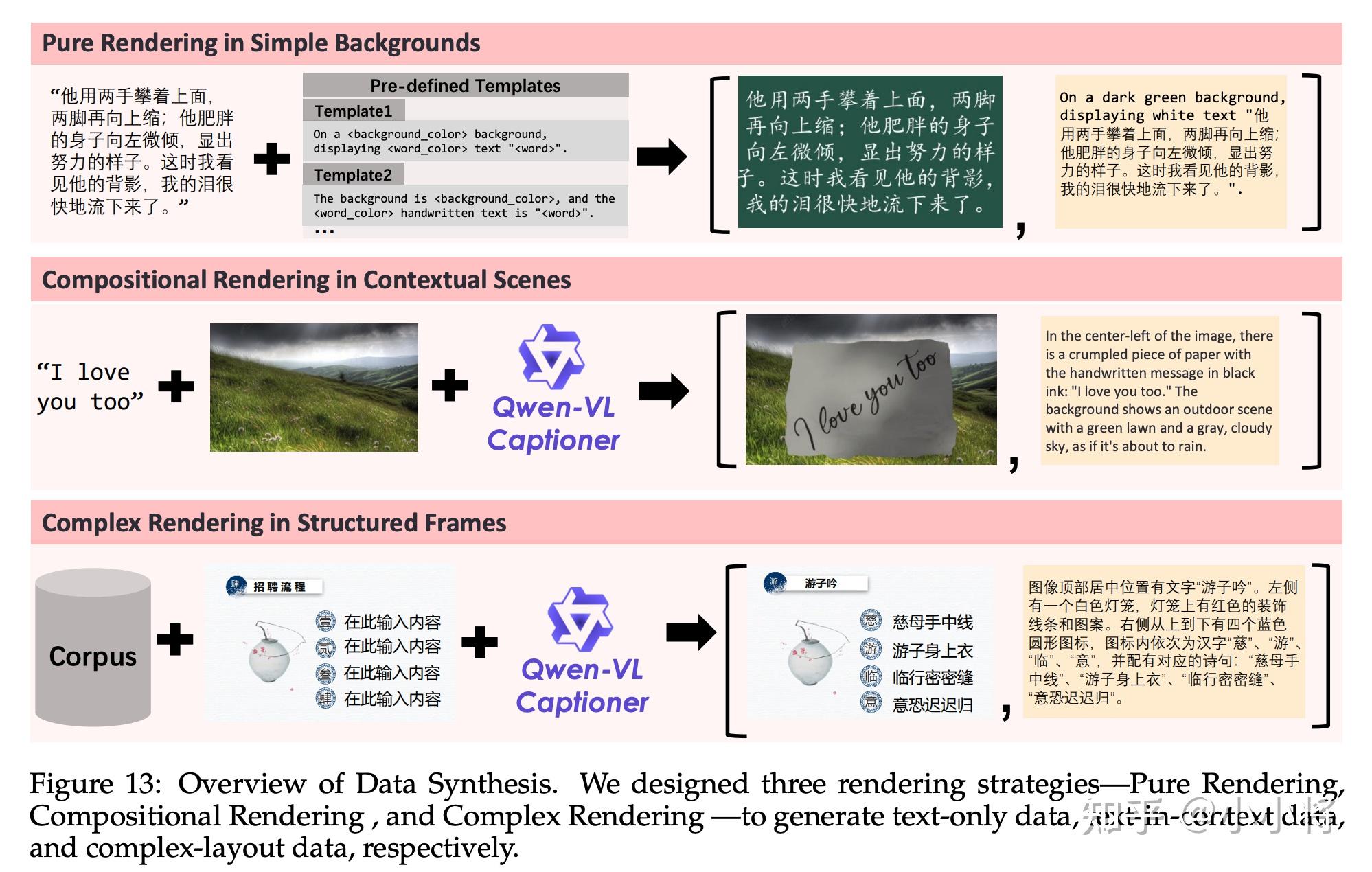
其中合成数据占比约5%。但是这里所说的“合成”并不包括由其他AI模型生成的图像,而是指通过受控的文本渲染技术生成的数据:
数据的标注采用Qwen2.5-VL,这里不仅用于生成详细的图像描述,还用于提取结构化元数据,比如图像类型(如照片、插画、截图)、图像风格(如写实、卡通)、以及是否存在水印等:

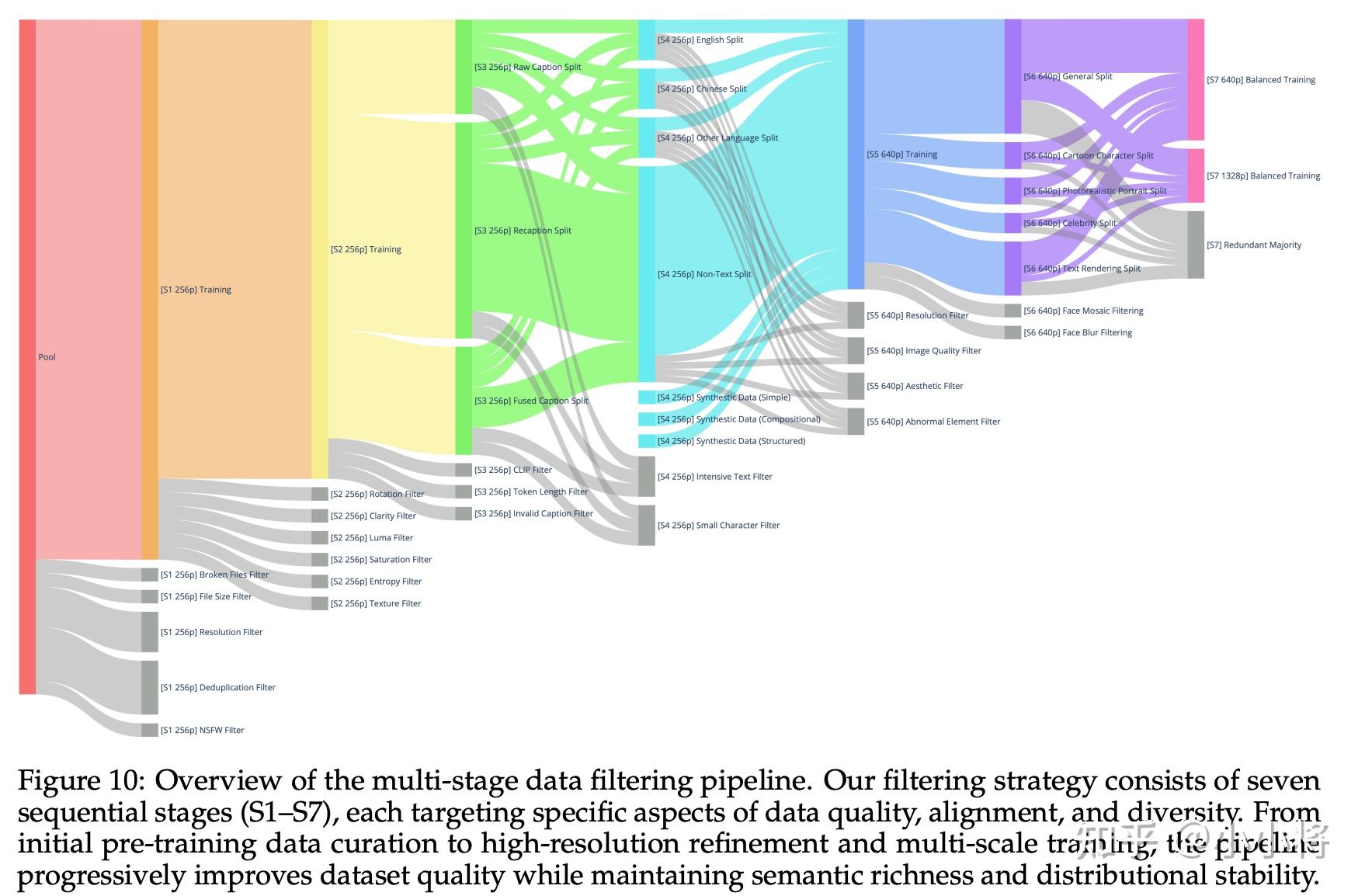
训练数据采用七阶段的渐进式数据过滤流程,如下图所示,这些阶段会随着训练进程依次进行,同时数据分布也会不断被优化调整:逐步提升图像质量、文本对齐度、分辨率以及数据分布。
模型的后训练包括SFT和RL,在微调阶段,用高质量图像和人工标注优化模型,使其生成更真实、细节更丰富的内容。在强化学习阶段中,先用高效的DPO方法进行大规模偏好训练,再用GRPO做小范围精细调整,从而提升生成效果。
最后放一些Qwen-Image和其它的模型的可视化对比:











当前,Qwen-Image可以在魔塔上体验:
- https://modelscope.cn/aigc/imageGeneration
我拿GPT-4o的几个例子试了一下,发现Qwen-Image的整体效果确实不错,但是在复杂场景下,文本指令遵循能力还是稍差于GPT-4o(展示的分别是GPT-4o和Qwen-Image的生成图片):





发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/259328.html原文链接:https://javaforall.net


