
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
本篇概览
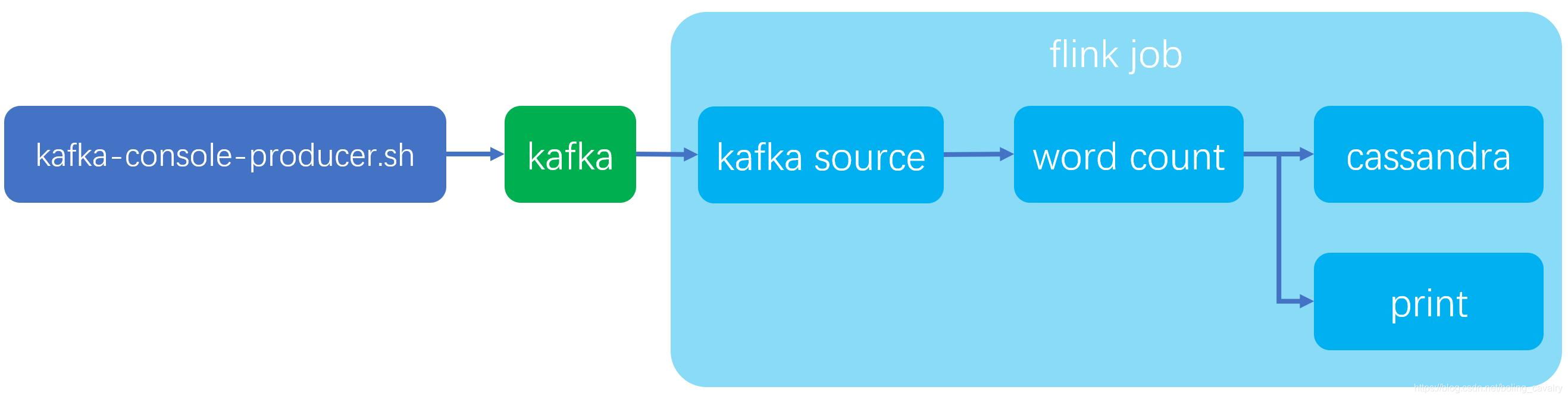
本文是《Flink的sink实战》系列的第三篇,主要内容是体验Flink官方的cassandra connector,整个实战如下图所示,我们先从kafka获取字符串,再执行wordcount操作,然后将结果同时打印和写入cassandra:

全系列链接
软件版本
本次实战的软件版本信息如下:
- cassandra:3.11.6
- kafka:2.4.0(scala:2.12)
- jdk:1.8.0_191
- flink:1.9.2
- maven:3.6.0
- flink所在操作系统:CentOS Linux release 7.7.1908
- cassandra所在操作系统:CentOS Linux release 7.7.1908
- IDEA:2018.3.5 (Ultimate Edition)
关于cassandra
本次用到的cassandra是三台集群部署的集群,搭建方式请参考《ansible快速部署cassandra3集群》
准备cassandra的keyspace和表
先创建keyspace和table:
- cqlsh登录cassandra:
cqlsh 192.168.133.168
- 创建keyspace(3副本):
CREATE KEYSPACE IF NOT EXISTS example
WITH replication = {'class': 'SimpleStrategy', 'replication_factor': '3'};
- 建表:
CREATE TABLE IF NOT EXISTS example.wordcount (
word text,
count bigint,
PRIMARY KEY(word)
);
准备kafka的topic
- 启动kafka服务;
- 创建名为test001的topic,参考命令如下:
./kafka-topics.sh \
--create \
--bootstrap-server 127.0.0.1:9092 \
--replication-factor 1 \
--partitions 1 \
--topic test001
- 进入发送消息的会话模式,参考命令如下:
./kafka-console-producer.sh \
--broker-list kafka:9092 \
--topic test001
- 在会话模式下,输入任意字符串然后回车,都会将字符串消息发送到broker;
源码下载
如果您不想写代码,整个系列的源码可在GitHub下载到,地址和链接信息如下表所示(https://github.com/zq2599/blog_demos):
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
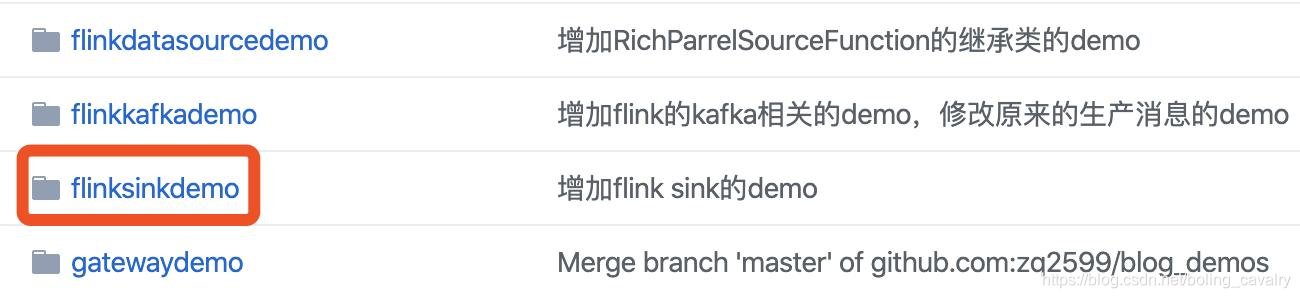
这个git项目中有多个文件夹,本章的应用在flinksinkdemo文件夹下,如下图红框所示:
两种写入cassandra的方式
flink官方的connector支持两种方式写入cassandra:
- Tuple类型写入:将Tuple对象的字段对齐到指定的SQL的参数中;
- POJO类型写入:通过DataStax,将POJO对象对应到注解配置的表和字段中;
接下来分别使用这两种方式;
开发(Tuple写入)
- 《Flink的sink实战之二:kafka》中创建了flinksinkdemo工程,在此继续使用;
- 在pom.xml中增加casandra的connector依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-cassandra_2.11</artifactId>
<version>1.10.0</version>
</dependency>
- 另外还要添加flink-streaming-scala依赖,否则编译CassandraSink.addSink这段代码会失败:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
- 新增CassandraTuple2Sink.java,这就是Job类,里面从kafka获取字符串消息,然后转成Tuple2类型的数据集写入cassandra,写入的关键点是Tuple内容和指定SQL中的参数的匹配:
package com.bolingcavalry.addsink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.PrintSinkFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.cassandra.CassandraSink;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.util.Properties;
public class CassandraTuple2Sink {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度
env.setParallelism(1);
//连接kafka用到的属性对象
Properties properties = new Properties();
//broker地址
properties.setProperty("bootstrap.servers", "192.168.50.43:9092");
//zookeeper地址
properties.setProperty("zookeeper.connect", "192.168.50.43:2181");
//消费者的groupId
properties.setProperty("group.id", "flink-connector");
//实例化Consumer类
FlinkKafkaConsumer<String> flinkKafkaConsumer = new FlinkKafkaConsumer<>(
"test001",
new SimpleStringSchema(),
properties
);
//指定从最新位置开始消费,相当于放弃历史消息
flinkKafkaConsumer.setStartFromLatest();
//通过addSource方法得到DataSource
DataStream<String> dataStream = env.addSource(flinkKafkaConsumer);
DataStream<Tuple2<String, Long>> result = dataStream
.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Long>> out) {
String[] words = value.toLowerCase().split("\\s");
for (String word : words) {
//cassandra的表中,每个word都是主键,因此不能为空
if (!word.isEmpty()) {
out.collect(new Tuple2<String, Long>(word, 1L));
}
}
}
}
)
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
result.addSink(new PrintSinkFunction<>())
.name("print Sink")
.disableChaining();
CassandraSink.addSink(result)
.setQuery("INSERT INTO example.wordcount(word, count) values (?, ?);")
.setHost("192.168.133.168")
.build()
.name("cassandra Sink")
.disableChaining();
env.execute("kafka-2.4 source, cassandra-3.11.6 sink, tuple2");
}
}
- 上述代码中,从kafka取得数据,做了word count处理后写入到cassandra,注意addSink方法后的一连串API(包含了数据库连接的参数),这是flink官方推荐的操作,另外为了在Flink web UI看清楚DAG情况,这里调用disableChaining方法取消了operator chain,生产环境中这一行可以去掉;
- 编码完成后,执行mvn clean package -U -DskipTests构建,在target目录得到文件flinksinkdemo-1.0-SNAPSHOT.jar;
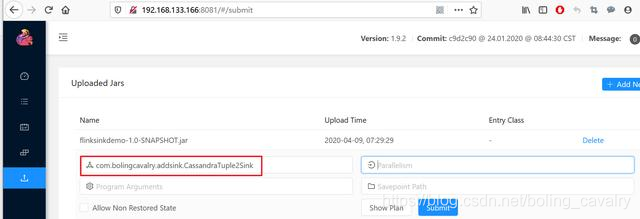
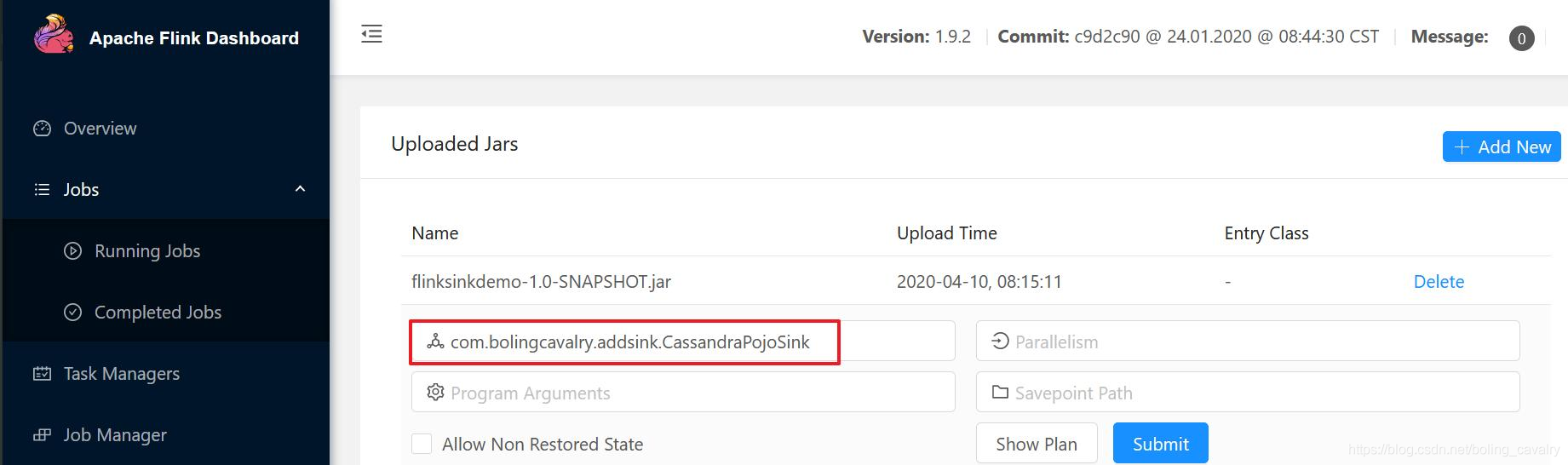
- 在Flink的web UI上传flinksinkdemo-1.0-SNAPSHOT.jar,并指定执行类,如下图红框所示:
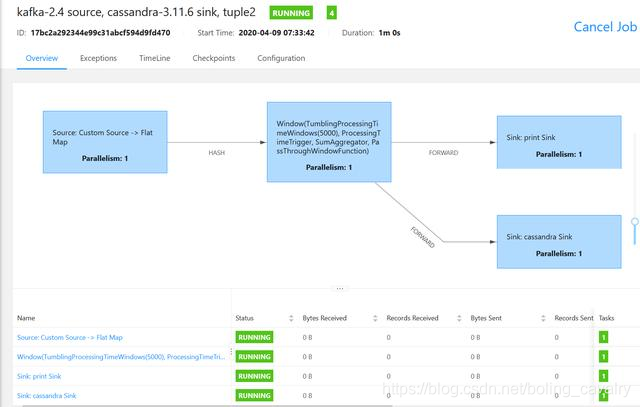
- 启动任务后DAG如下:
- 去前面创建的发送kafka消息的会话模式窗口,发送一个字符串”aaa bbb ccc aaa aaa aaa”;
- 查看cassandra数据,发现已经新增了三条记录,内容符合预期:
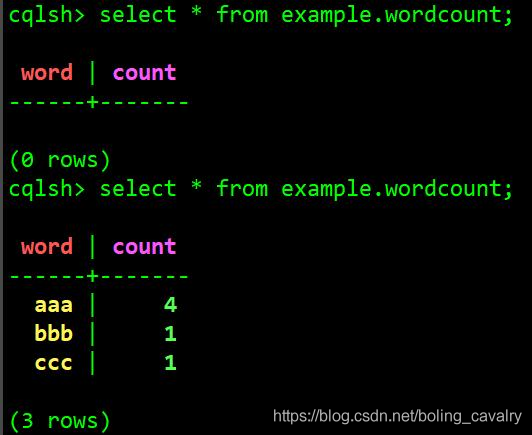
- 查看TaskManager控制台输出,里面有Tuple2数据集的打印结果,和cassandra的一致:

- DAG上所有SubTask的记录数也符合预期:

开发(POJO写入)
接下来尝试POJO写入,即业务逻辑中的数据结构实例被写入cassandra,无需指定SQL:
- 实现POJO写入数据库,需要datastax库的支持,在pom.xml中增加以下依赖:
<dependency>
<groupId>com.datastax.cassandra</groupId>
<artifactId>cassandra-driver-core</artifactId>
<version>3.1.4</version>
<classifier>shaded</classifier>
<!-- Because the shaded JAR uses the original POM, you still need
to exclude this dependency explicitly: -->
<exclusions>
<exclusion>
<groupId>io.netty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
- 请注意上面配置的exclusions节点,依赖datastax的时候,按照官方指导对netty相关的间接依赖做排除,官方地址:https://docs.datastax.com/en/developer/java-driver/3.1/manual/shaded_jar/
- 创建带有数据库相关注解的实体类WordCount:
package com.bolingcavalry.addsink;
import com.datastax.driver.mapping.annotations.Column;
import com.datastax.driver.mapping.annotations.Table;
@Table(keyspace = "example", name = "wordcount")
public class WordCount {
@Column(name = "word")
private String word = "";
@Column(name = "count")
private long count = 0;
public WordCount() {
}
public WordCount(String word, long count) {
this.setWord(word);
this.setCount(count);
}
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
public long getCount() {
return count;
}
public void setCount(long count) {
this.count = count;
}
@Override
public String toString() {
return getWord() + " : " + getCount();
}
}
- 然后创建任务类CassandraPojoSink:
package com.bolingcavalry.addsink;
import com.datastax.driver.mapping.Mapper;
import com.datastax.shaded.netty.util.Recycler;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.PrintSinkFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.cassandra.CassandraSink;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.util.Properties;
public class CassandraPojoSink {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度
env.setParallelism(1);
//连接kafka用到的属性对象
Properties properties = new Properties();
//broker地址
properties.setProperty("bootstrap.servers", "192.168.50.43:9092");
//zookeeper地址
properties.setProperty("zookeeper.connect", "192.168.50.43:2181");
//消费者的groupId
properties.setProperty("group.id", "flink-connector");
//实例化Consumer类
FlinkKafkaConsumer<String> flinkKafkaConsumer = new FlinkKafkaConsumer<>(
"test001",
new SimpleStringSchema(),
properties
);
//指定从最新位置开始消费,相当于放弃历史消息
flinkKafkaConsumer.setStartFromLatest();
//通过addSource方法得到DataSource
DataStream<String> dataStream = env.addSource(flinkKafkaConsumer);
DataStream<WordCount> result = dataStream
.flatMap(new FlatMapFunction<String, WordCount>() {
@Override
public void flatMap(String s, Collector<WordCount> collector) throws Exception {
String[] words = s.toLowerCase().split("\\s");
for (String word : words) {
if (!word.isEmpty()) {
//cassandra的表中,每个word都是主键,因此不能为空
collector.collect(new WordCount(word, 1L));
}
}
}
})
.keyBy("word")
.timeWindow(Time.seconds(5))
.reduce(new ReduceFunction<WordCount>() {
@Override
public WordCount reduce(WordCount wordCount, WordCount t1) throws Exception {
return new WordCount(wordCount.getWord(), wordCount.getCount() + t1.getCount());
}
});
result.addSink(new PrintSinkFunction<>())
.name("print Sink")
.disableChaining();
CassandraSink.addSink(result)
.setHost("192.168.133.168")
.setMapperOptions(() -> new Mapper.Option[] { Mapper.Option.saveNullFields(true) })
.build()
.name("cassandra Sink")
.disableChaining();
env.execute("kafka-2.4 source, cassandra-3.11.6 sink, pojo");
}
}
- 从上述代码可见,和前面的Tuple写入类型有很大差别,为了准备好POJO类型的数据集,除了flatMap的匿名类入参要改写,还要写好reduce方法的匿名类入参,并且还要调用setMapperOptions设置映射规则;
- 编译构建后,上传jar到flink,并且指定任务类为CassandraPojoSink:
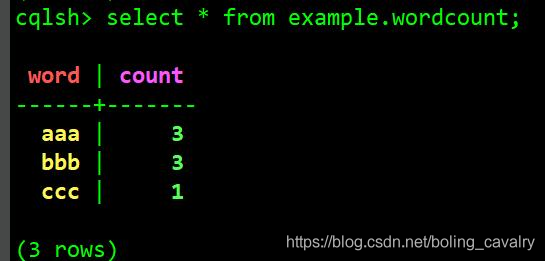
- 清理之前的数据,在cassandra的cqlsh上执行TRUNCATE example.wordcount;
- 像之前那样发送字符串消息到kafka:

- 查看数据库,发现结果符合预期:
10. DAG和SubTask情况如下:

至此,flink的结果数据写入cassandra的实战就完成了,希望能给您一些参考;
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界…
https://github.com/zq2599/blog_demos
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/2631.html原文链接:https://javaforall.net


